
Image by author
In today's world we constantly generate information, but much of it appears in unstructured formats.
This includes the wide range of social media content, as well as countless PDF files and Word documents stored on organizational networks.
Getting information and value from these unstructured sources, whether text documents, web pages or social media updates, poses a considerable challenge.
However, the emergence of Large Language Models (LLM) such as GPT or LlaMa has completely revolutionized the way we deal with unstructured data.
These sophisticated models serve as powerful instruments for transforming unstructured data into structured and valuable information, effectively mining the hidden treasures within our digital landscape.
Let's look at 4 different ways to extract insights from unstructured data using GPT
Throughout this tutorial, we will work with the OpenAI API. If you don't have a working account yet, check this out tutorial on how to get your OpenAI API account.
Imagine that we have an e-commerce (Amazon in this case ), and we are responsible for managing the millions of reviews that users leave about our products.
To demonstrate the opportunity that LLMs represent to handle this type of data, I am using a Kaggle dataset with Amazon reviews.
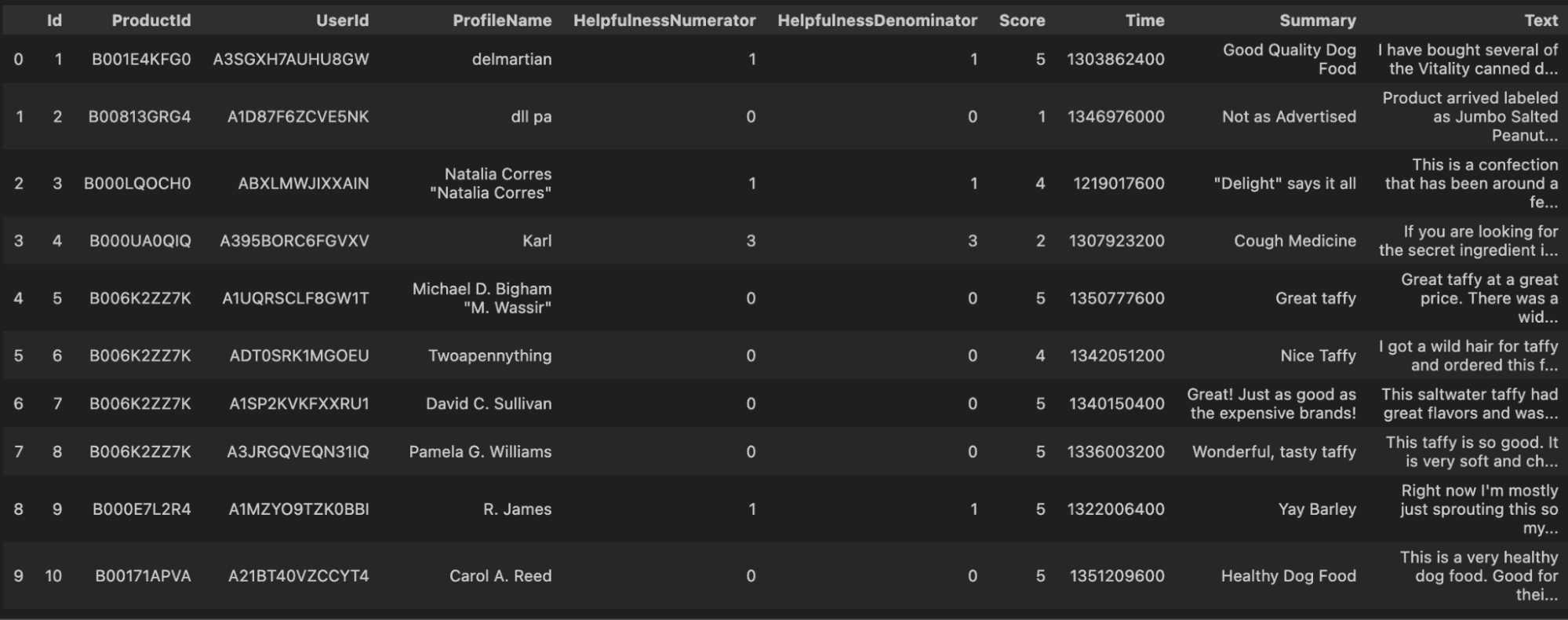
Original data set
Structured data refers to data types that are formatted and repeated consistently. Classic examples include banking transactions, airline reservations, retail sales, and telephone call records.
This data generally arises from transactional processes.
This data is suitable for storage and management within a conventional database management system due to its uniform format.
On the other hand, text is usually classified as unstructured data. Historically, before the development of textual disambiguation techniques, incorporating text into a standard database management system was challenging due to its less rigid structure.
And this leads us to the next question…
Is the text truly unstructured or does it have an underlying structure that is not immediately evident?
Text inherently has structure, but this complexity does not align with the conventional structured format recognizable by computers. Computers are capable of interpreting simple and direct structures, but language, with its elaborate syntax, is outside their field of understanding.
So this brings us to one last question:
If computers have difficulty processing unstructured data efficiently, is it possible to convert this unstructured data to a structured format for better handling?
Manual conversion to structured data is time-consuming and has a high risk of human error. It is often a mix of words, sentences and paragraphs, in a wide variety of formats, making it difficult for machines to understand its meaning and structure it.
And this is precisely where LLMs play a key role. Converting unstructured data to a structured format is essential if we want to work with or process it in any way, including data analysis, information retrieval, and knowledge management.
Large Language Models (LLM) such as GPT-3 or GPT-4 offer powerful capabilities for extracting information from unstructured data.
So our main weapons will be the OpenAI API and creating our own messages to define what we need. Here are four ways you can leverage these models to get structured insights from unstructured data:
1. Text summary
LLMs can efficiently summarize large volumes of text, such as reports, articles or long documents. This can be especially useful for quickly understanding key points and themes in large data sets.
In our case, it is much better to have a first summary of the review than the full review. So GPT can fix it in seconds.
And our only (and most important) task will be to craft a good message.
In this case, I can tell GPT that:
Summarize the following review: \"{review}\" with a 3 words sentence.So let's put this into practice with a few lines of code.
Code by author
And we will get something like the following…
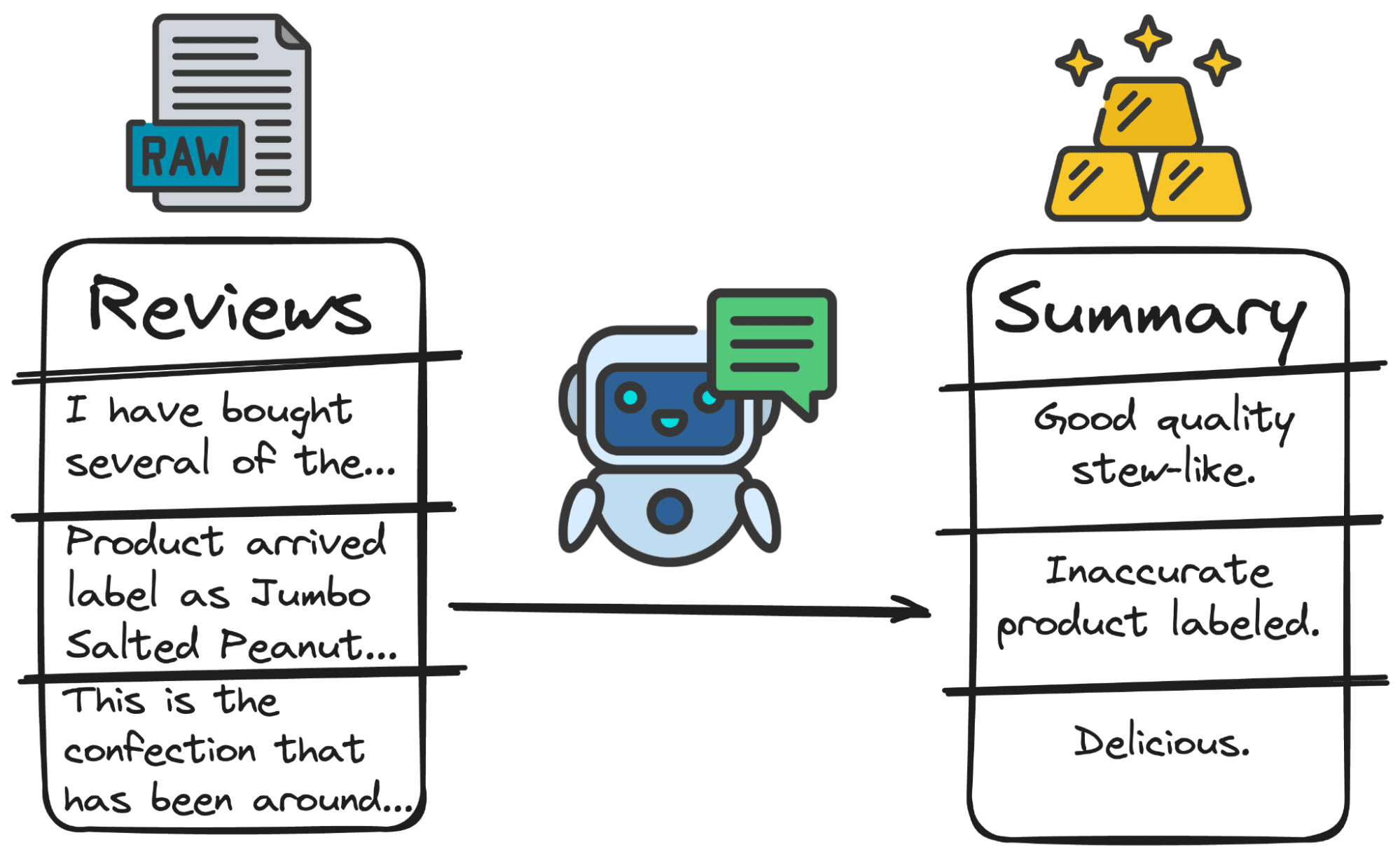
Image by author
2. Sentiment analysis
These models can be used for sentiment analysis, determining the tone and sentiment of text data such as customer reviews, social media posts, or feedback surveys.
The simplest, but most used, classification of all time is polarity.
- Positive reviews or why people are happy with the product.
- Negative reviews or why they are upset.
- Neutral or why people are indifferent to the product.
By analyzing these sentiments, companies can measure public opinion, customer satisfaction, and market trends. So, instead of one person deciding each review, we can have our friend GPT rank them for us.
So again the main code will consist of a message and a simple API call.
Let's put this into practice.
Code by author
And we would obtain something like this:
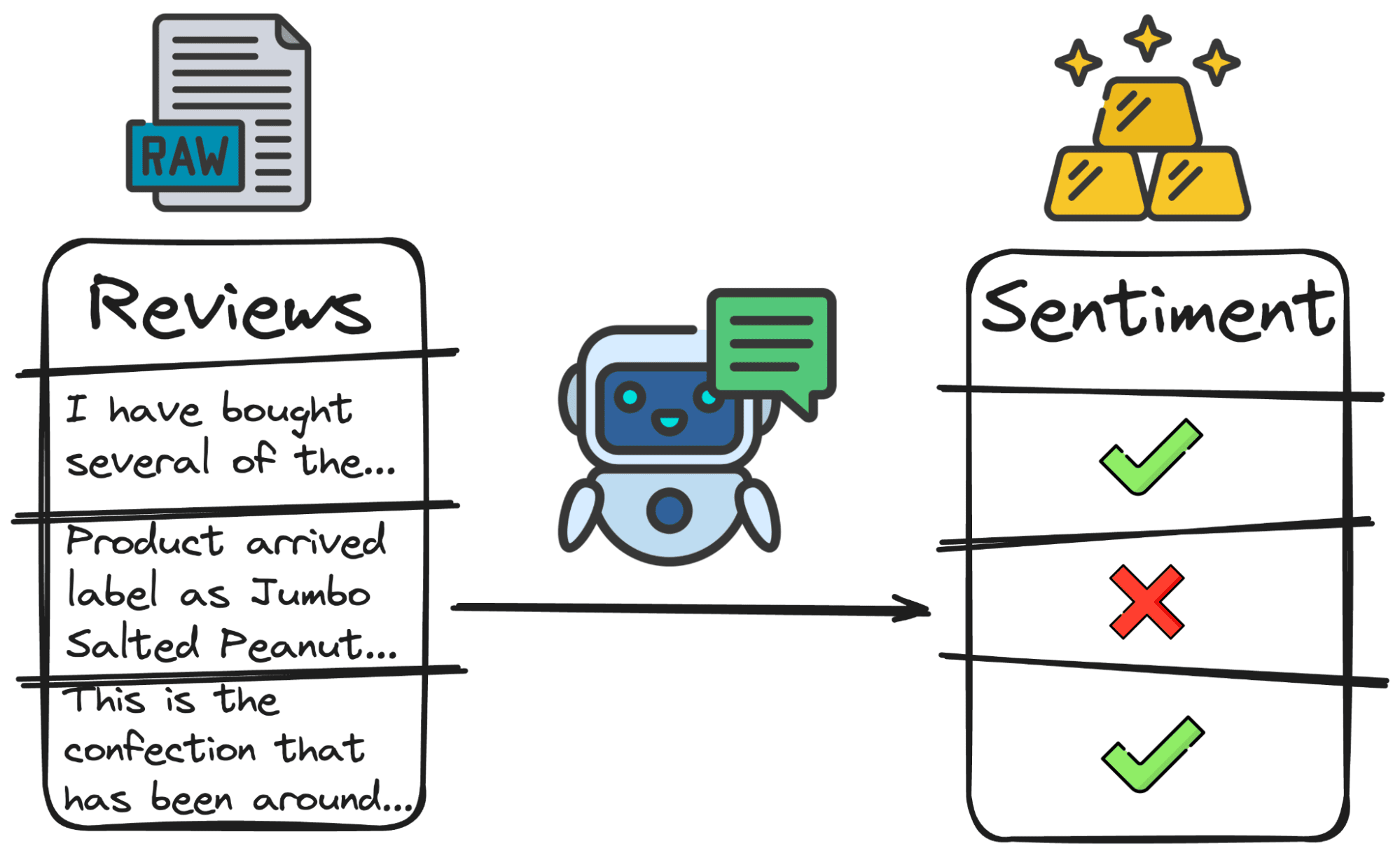
Image by author
3. Thematic analysis
LLMs can identify and categorize themes or topics within large data sets. This is particularly useful for qualitative data analysis, where you may need to examine large amounts of text to understand common themes, trends, or patterns.
When analyzing reviews, it can be helpful to understand the main purpose of the review. Some users will complain about something (service, quality, cost…), others will rate their experience with the product (good or bad) and others will ask questions.
Again, doing this work manually would take many hours. But with our friend GPT, only a few lines of code are needed:
Code by author
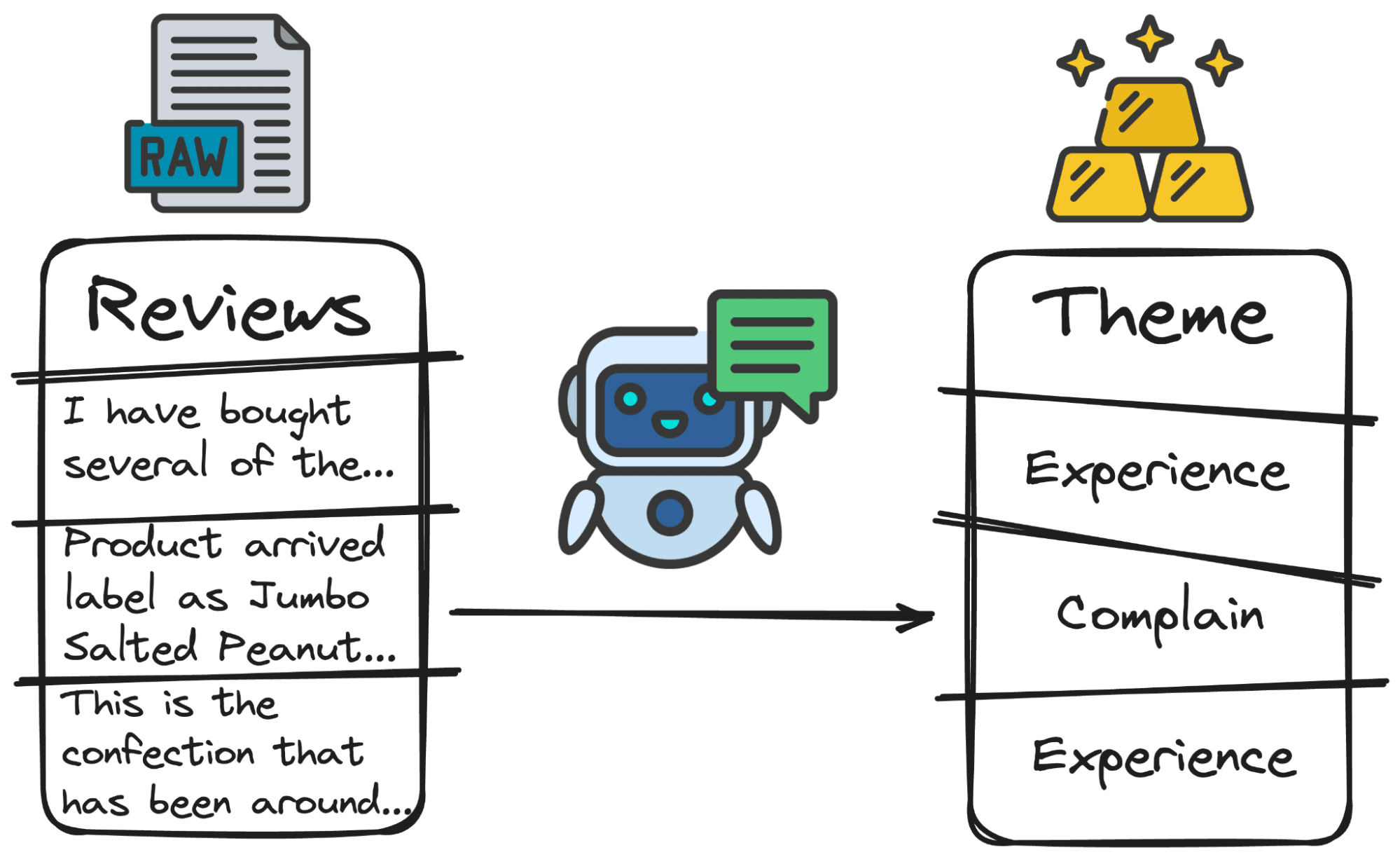
Image by author
4. Keyword extraction
LLMs can be used to extract keywords. That is, detect any element that we request.
Let's imagine, for example, that we want to know if the product to which the review is attached is the product that the user is talking about. To do this we must detect which product the user is reviewing.
And again… we can ask our GPT model to find out what main product the user is talking about.
So let's put this into practice!
Code by author
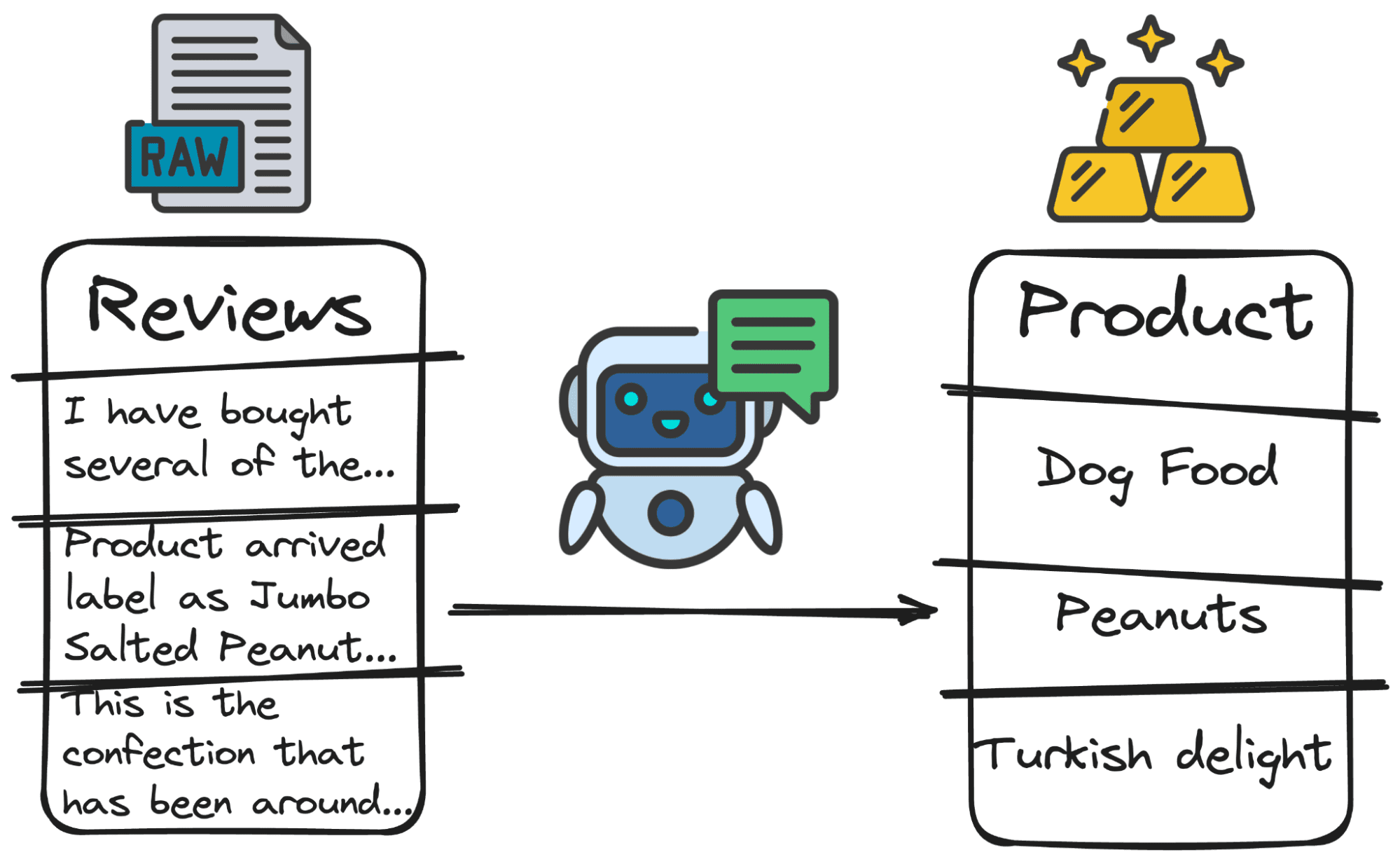
Image by author
In conclusion, the transformative power of large language models (LLMs) in turning unstructured data into structured insights cannot be underestimated. By leveraging these models, we can extract meaningful insights from the vast sea of unstructured data flowing within our digital world.
The four methods discussed (text summarization, sentiment analysis, thematic analysis, and keyword extraction) demonstrate the versatility and efficiency of LLMs in handling various data challenges.
These capabilities allow organizations to gain a deeper understanding of customer feedback, market trends, and operational inefficiencies.
Joseph Ferrer He is an analytical engineer from Barcelona. He graduated in physical engineering and currently works in the field of Data Science applied to human mobility. He is a part-time content creator focused on data science and technology. You can contact him at LinkedIn, Twitter either Half.






{kind=link}