
sponsored post

The challenges of building multimodal models from scratch
For many machine learning use cases, organizations rely solely on tabular data and tree-based models like XGBoost and LightGBM. This is because deep learning is simply too difficult for most ML teams. Common challenges include:
- Lack of expert knowledge needed to develop complex deep learning models
- Frameworks like PyTorch and Tensorflow require teams to write thousands of lines of code that are prone to human error.
- Training distributed DL pipelines requires deep knowledge of the infrastructure and can take weeks to train models
As a result, teams miss valuable signals hidden in unstructured data like text and images.
Rapid model development with declarative systems
New declarative machine learning systems, like the open source Ludwig started at Uber, provide a low-code approach to automating machine learning that allows data teams to build and deploy next-generation models faster with one configuration file. simple. Specifically, Predibase, the leading low-code declarative machine learning platform, together with Ludwig make it easy to build multimodal deep learning models in < 15 lines of code.
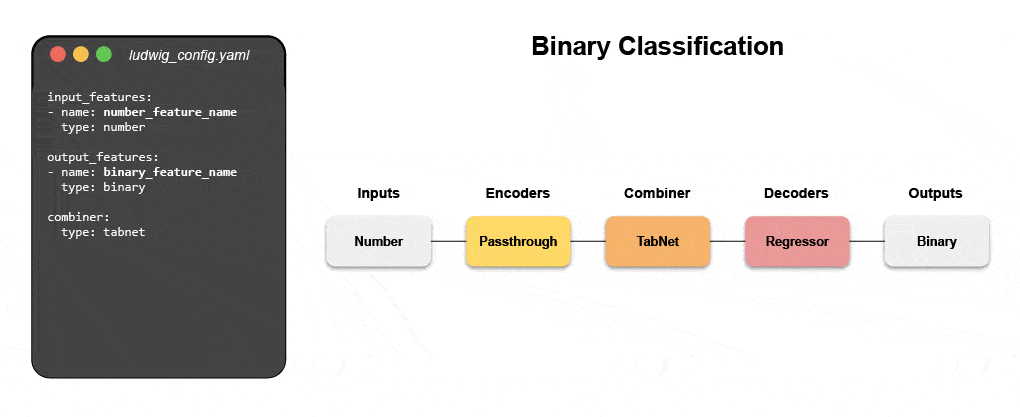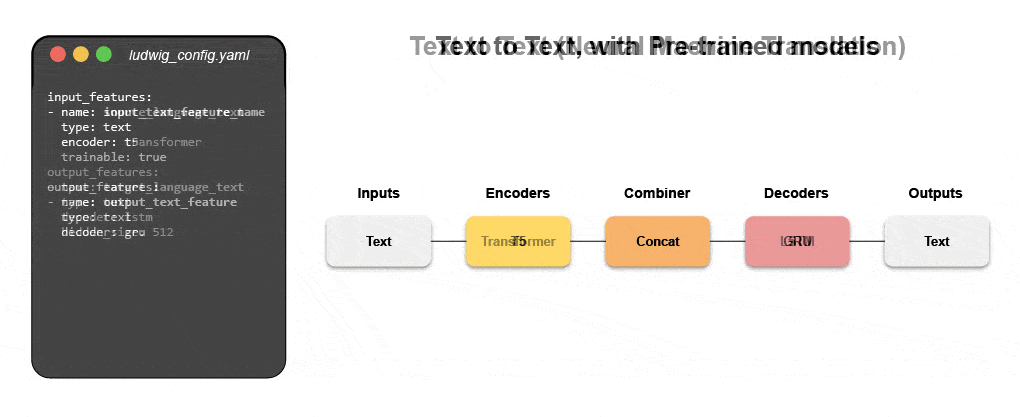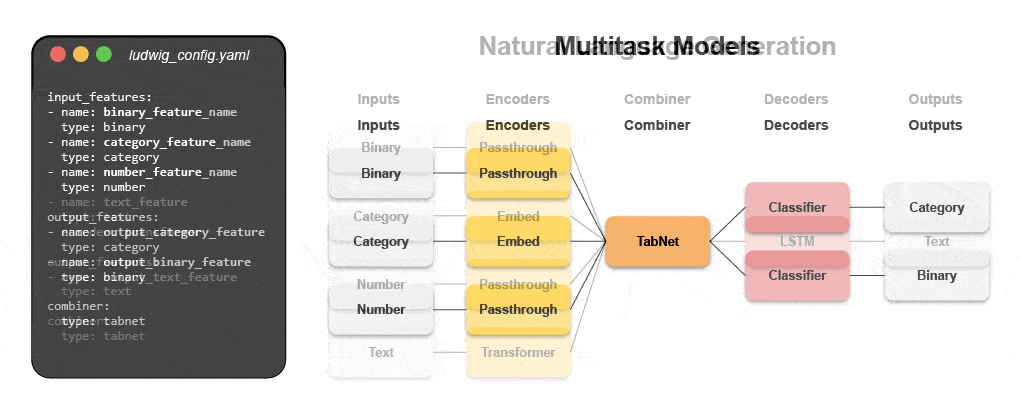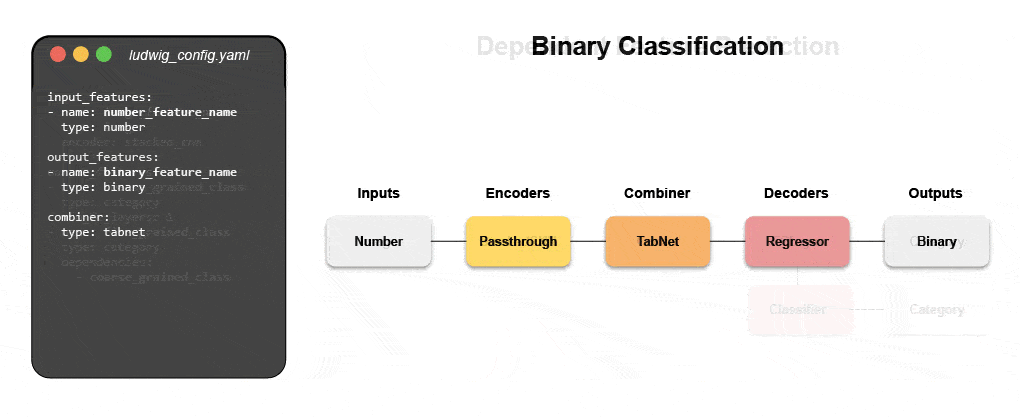
Learn how to build a multimodal model with declarative ML
Join our next webinar and a live tutorial to learn about declarative systems like Ludwig and follow step-by-step instructions to build a multimodal customer review prediction model that leverages text and tabular data.
In this session you will learn to:
- Quickly train, iterate, and deploy a multi-modal model for customer review predictions,
- Use low-code declarative machine learning tools to dramatically reduce the time it takes to build multiple machine learning models.
- Leverage unstructured data just as easily as structured data with Ludwig and open source Predibase




{kind=link}