Introducción
Después de un año de adoptar ChatGPT, el panorama de la IA da la bienvenida al tan esperado Gemini de Google, un competidor formidable. La serie Gemini comprende tres potentes modelos de lenguaje: Gemini Pro, Gemini Nano y el Gemini Ultra de primer nivel, que ha demostrado un rendimiento excepcional en varios puntos de referencia, aunque aún no se ha lanzado al mercado. Actualmente, los modelos Gemini Pro ofrecen un rendimiento comparable al gpt-3.5-turbo, lo que proporciona una solución accesible y rentable para tareas de visión y comprensión del lenguaje natural. Estos modelos se pueden aplicar a diversos escenarios del mundo real, incluida la narración en video, la respuesta visual a preguntas (QA), RAG (Generación de recuperación aumentada) y más. En este artículo, analizaremos las capacidades de los modelos Gemini Pro y lo guiaremos en la creación de un bot de control de calidad multimodal utilizando Gemini y Gradio.

Objetivos de aprendizaje
- Explora los modelos Géminis.
- Autentique VertexAI para acceder a los modelos Gemini.
- Explore la API de Gemini y el SDK de Python de GCP.
- Conozca más sobre Gradio y sus componentes.
- Cree un bot de control de calidad multimodal funcional utilizando Gemini y Gradio.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Antes de comenzar a construir nuestro QA Bot usando Gemini y Gradio, comprendamos las características de Gemini.
¿Qué es Google Géminis?
Al igual que GPT, la familia de modelos Gemini utiliza decodificadores de transformadores optimizados para entrenamiento de escala e inferencia en las Unidades de Procesamiento Tensoriales de Google. Estos modelos se someten a un entrenamiento conjunto en varias modalidades de datos, incluidos texto, imagen, audio y video, para desarrollar modelos de lenguaje grande (LLM) con capacidades versátiles y una comprensión integral de múltiples modos. Gemini consta de tres clases de modelos: Gemini Pro, Nano y Ultra, cada una de ellas ajustada para casos de uso específicos.
- Géminis Ultra: El de mayor rendimiento de Google ha mostrado un rendimiento de última generación en tareas como matemáticas, razonamiento, capacidades multimodales, etc. Según el informe técnico de Google, Gemini Ultra ha tenido un mejor rendimiento que GPT-4 en muchos puntos de referencia. .
- Géminis profesional: El modelo profesional está optimizado para rendimiento, escalabilidad e inferencia de baja latencia. Es un modelo capaz que rivaliza con el gpt-3.5-turbo con capacidades multimodales.
- Géminis Nano: Nano tiene dos LLM más pequeños con parámetros 1.8B y 3B. Se entrena destilando modelos Gemini más grandes optimizados para ejecutarse en dispositivos con poca y alta memoria.
Puede acceder a los modelos a través de GCP Vertex ai o Google ai Studio. Si bien Vertex ai es adecuado para aplicaciones de producción, exige una cuenta de GCP. Sin embargo, con Estudio de IA, los desarrolladores pueden crear una clave API para acceder a los modelos Gemini sin una cuenta de GCP. Exploraremos ambos métodos en este artículo, pero implementaremos el método VertexAI. Puedes implementar esto último con algunos ajustes en el código.
Ahora, ¡comencemos a construir un bot de control de calidad usando Gemini!
Accediendo a Gemini usando VertexAI
Se puede acceder a los modelos Gemini desde VertexAI en GCP. Entonces, para comenzar a construir con estos modelos, necesitamos configurar Google Cloud CLI y autenticarnos con Vertex ai. Primero, instalar la CLI de GCP e inicializar con inicio de gcloud.
Cree una credencial de autenticación para su cuenta con el comando gcloud auth application-inicio de sesión predeterminado. Esto abrirá un portal para iniciar sesión en Google y seguir las instrucciones. Una vez hecho esto, podrás trabajar con Google Cloud desde un entorno local.
Ahora, cree un entorno virtual e instale la biblioteca Python. Este es el SDK de Python para GCP para acceder a los modelos Gemini.
pip install --upgrade google-cloud-aiplatformAhora que nuestro entorno está preparado. Entendamos la API de Gemini.
Solicitar cuerpo a la API de Gemini
Google ha lanzado solo los modelos Pro y Pro vision para uso público. Gemini Pro es un LLM de solo texto adecuado para casos de uso de generación de texto, como resumir, parafrasear, traducir, etc. Tiene un tamaño de contexto de 32k. Sin embargo, el modelo de visión puede procesar imágenes y vídeos. Tiene un tamaño de contexto de 16k. Podemos enviar 16 archivos de imagen o un vídeo a la vez.
A continuación se muestra un cuerpo de solicitud para la API de Gemini:
{
"contents": (
{
"role": string,
"parts": (
{
// Union field data can be only one of the following:
"text": string,
"inlineData": {
"mimeType": string,
"data": string
},
"fileData": {
"mimeType": string,
"fileUri": string
},
// End of list of possible types for union field data.
"videoMetadata": {
"startOffset": {
"seconds": integer,
"nanos": integer
},
"endOffset": {
"seconds": integer,
"nanos": integer
}
}
}
)
}
),
"tools": (
{
"functionDeclarations": (
{
"name": string,
"description": string,
"parameters": {
object (OpenAPI Object Schema)
}
}
)
}
),
"safetySettings": (
{
"category": enum (HarmCategory),
"threshold": enum (HarmBlockThreshold)
}
),
"generationConfig": {
"temperature": number,
"topP": number,
"topK": number,
"candidateCount": integer,
"maxOutputTokens": integer,
"stopSequences": (
string
)
}
}En el esquema JSON anterior, tenemos roles (usuario, sistema o función), texto, datos de archivos para imágenes o videos y configuración de generación para más parámetros del modelo y configuraciones de seguridad para alterar la tolerancia de sensibilidad del modelo.
Esta es la respuesta JSON de la API.
{
"candidates": (
{
"content": {
"parts": (
{
"text": string
}
)
},
"finishReason": enum (FinishReason),
"safetyRatings": (
{
"category": enum (HarmCategory),
"probability": enum (HarmProbability),
"blocked": boolean
}
),
"citationMetadata": {
"citations": (
{
"startIndex": integer,
"endIndex": integer,
"uri": string,
"title": string,
"license": string,
"publicationDate": {
"year": integer,
"month": integer,
"day": integer
}
}
)
}
}
),
"usageMetadata": {
"promptTokenCount": integer,
"candidatesTokenCount": integer,
"totalTokenCount": integer
}
}Como respuesta, obtenemos un JSON con las respuestas, citas, calificaciones de seguridad y datos de uso. Estos son los esquemas JSON de solicitudes y respuestas a la API de Gemini. Para obtener más información, consulte este funcionario. ai/docs/generative-ai/model-reference/gemini” target=”_blank” rel=”noreferrer noopener nofollow”>documentación para Géminis.
Puede comunicarse directamente con API con JSON. A veces, es mejor comunicarse directamente con los puntos finales de API en lugar de depender de los SDK, ya que estos últimos suelen sufrir cambios importantes.
Para simplificar, usaremos el SDK de Python que instalamos anteriormente para comunicarnos con los modelos.
from vertexai.preview.generative_models import GenerativeModel, Image, Part, GenerationConfig
model = GenerativeModel("gemini-pro-vision", generation_config= GenerationConfig())
response = model.generate_content(
(
"Explain this image step-by-step, using bullet marks in detail",
Part.from_image(Image.load_from_file("whisper_arch.png"))
),
)
print(response)Esto generará un objeto Generación.
candidates {
content {
role: "model"
parts {
text: " * response
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 271
candidates_token_count: 125
total_token_count: 396
}Podemos recuperar los textos con el siguiente código.
print(response.candidates(0).content.parts(0).text)Producción
Para recibir un objeto de transmisión, cambie la transmisión a Verdadero.
response = model.generate_content(
(
"Explain this image step-by-step, using bullet marks in detail?",
Part.from_image(Image.load_from_file("whisper_arch.png"))
), stream=True
)Para recuperar fragmentos, itere sobre el objeto StreamingGeneration.
for resp in response:
print(resp.candidates(0).content.parts(0).text)Producción
Antes de crear la aplicación, veamos una breve introducción a Gradio.
<h2 class="wp-block-heading" id="h-accessing-gemini-using-ai-studio”>Accediendo a Gemini usando ai Studio
Google ai Studio te permite acceder a los modelos Gemini a través de una API. Entonces, dirígete al Página Oficial y cree una clave API. Ahora, instale la siguiente biblioteca.
pip install google-generativeaiConfigure la clave API configurándola como una variable de entorno:
import google.generativeai as genai
api_key = "api-key"
genai.configure(api_key=api_key)Ahora, inferencia a partir de modelos.
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("What is the meaning of life?",)La estructura de respuesta es similar al método anterior.
print(response.candidates(0).content.parts(0).text)Producción
De manera similar, también se pueden inferir del modelo de visión.
import PIL.Image
img = "whisper_arch.png"
img = PIL.Image.open(img)
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(("Explain the architecture step by step in detail", img),
stream=True)
response.resolve()
for resp in response:
print(resp.text)
Producción
ai Studio es un excelente lugar para acceder a estos modelos si no desea utilizar GCP. Como usaremos VertexAI, puedes usar esto con algunas modificaciones.
Comencemos a construir un bot de control de calidad usando Gradio
Gradio es una herramienta de código abierto para crear aplicaciones web en Python para compartir modelos de aprendizaje automático. Tiene componentes modulares que se pueden juntar para crear una aplicación web sin involucrar códigos JavaScript o HTML. Gradio tiene API de bloques que te permite crear interfaces de usuario web con más personalización. El backend de Gradio está construido con Fastapi y el front-end está construido con Svelte. La biblioteca de Python abstrae las complejidades subyacentes y nos permite crear rápidamente una interfaz de usuario web. En este artículo, usaremos Gradio para crear la interfaz de usuario de nuestro bot de control de calidad.
Consulte este artículo para obtener una guía detallada para crear un chatbot de Gradio: Construyamos su chatbot de GPT con Gradio
Frontal con Gradio
Usaremos la API de bloques de Gradio y otros componentes para construir nuestra interfaz. Entonces, instala Gradio con pip si aún no lo has hecho e importa la biblioteca.
Para la interfaz, necesitamos una interfaz de usuario de chat para preguntas y respuestas, un cuadro de texto para enviar consultas de los usuarios, un cuadro de archivo para cargar imágenes/vídeos y componentes como un control deslizante, y un botón de opción para personalizar los parámetros del modelo, como temperatura, top-k. , arriba-p, etc.
Así podemos hacerlo con Gradio.
# Importing necessary libraries or modules
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=3):
gr.Markdown("Chatbot")
# Adding a Chatbot with a height of 650 and a copy button
chatbot = gr.Chatbot(show_copy_button=True, height=650)
with gr.Row():
# Creating a column with a scale of 6
with gr.Column(scale=6):
# Adding a Textbox with a placeholder "write prompt"
prompt = gr.Textbox(placeholder="write your queries")
# Creating a column with a scale of 2
with gr.Column(scale=2):
# Adding a File
file = gr.File()
# Creating a column with a scale of 2
with gr.Column(scale=2):
# Adding a Button
button = gr.Button()
# Creating another column with a scale of 1
with gr.Column(scale=1):
with gr.Row():
gr.Markdown("Model Parameters")
# Adding a Button with the value "Reset"
reset_params = gr.Button(value="Reset")
gr.Markdown("General")
# Adding a Dropdown for model selection
model = gr.Dropdown(value="gemini-pro", choices=("gemini-pro", "gemini-pro-vision"),
label="Model", info="Choose a model", interactive=True)
# Adding a Radio for streaming option
stream = gr.Radio(label="Streaming", choices=(True, False), value=True,
interactive=True, info="Stream while responses are generated")
# Adding a Slider for temperature
temparature = gr.Slider(value=0.6, maximum=1.0, label="Temperature", interactive=True)
# Adding a Textbox for stop sequence
stop_sequence = gr.Textbox(label="Stop Sequence",
info="Stops generation when the string is encountered.")
# Adding a Markdown with the text "Advanced"
gr.Markdown(value="Advanced")
# Adding a Slider for top-k parameter
top_p = gr.Slider(
value=0.4,
label="Top-k",
interactive=True,
info="""Top-k changes how the model selects tokens for output:
lower = less random, higher = more diverse. Defaults to 40."""
)
# Adding a Slider for top-p parameter
top_k = gr.Slider(
value=8,
label="Top-p",
interactive=True,
info="""Top-p changes how the model selects tokens for output.
Tokens are selected from most probable to least until
the sum of their probabilities equals the top-p value"""
)
demo.queue()
demo.launch()Hemos utilizado la API de filas y columnas de Gradio para personalizar la interfaz web. Ahora, ejecute el archivo Python con el construyendo app.py. Este abrirá un servidor Uvicorn en localhost:7860. Así se verá nuestra aplicación.
Producción
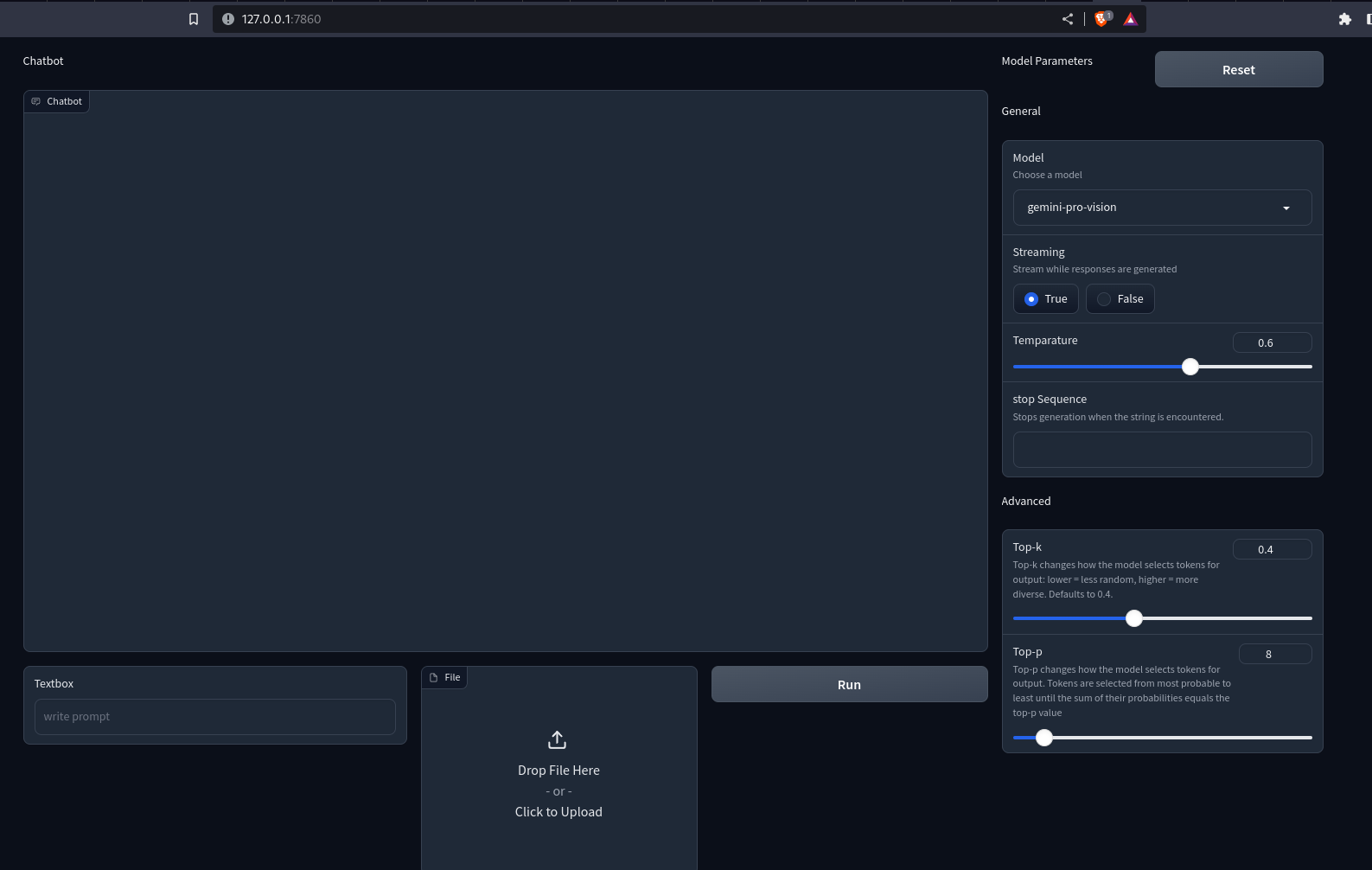
Notas que no pasa nada al presionar los botones. Para hacerlo interactivo, necesitamos definir controladores de eventos. Aquí, necesitamos controladores para los botones Ejecutar y Restablecer. Así es como podemos hacerlo.
button.click(fn=add_content, inputs=(prompt, chatbot, file), outputs=(chatbot))\
.success(fn = gemini_generator.run, inputs=(chatbot, prompt, file, model, stream,
temparature, stop_sequence,
top_k, top_p), outputs=(prompt,file,chatbot)
)
reset_params.click(fn=reset, outputs=(model, stream, temparature,
stop_sequence, top_p, top_k))Cuando se presiona el botón de clic, la función en el parámetro fn se llama con todas las entradas. Los valores devueltos por la función se envían a los componentes en las salidas. El evento de éxito es cómo podemos encadenar múltiples eventos. Pero notarás que no hemos definido las funciones. Necesitamos definir estas funciones para hacerlas interactivas.
Construyendo el back-end
La primera función que definiremos aquí es add_content. Esto mostrará los mensajes de usuario y API en la interfaz de chat. Así es como podemos hacer esto.
def add_content(text:str, chatbot:Chatbot, file: str)->Chatbot:
# Check if both file and text are provided
if file and text:
# Concatenate the existing chatbot content with new text and file content
chatbot = chatbot + ((text, None), ((file,), None))
# Check if only text is provided
elif text and not file:
# Concatenate the existing chatbot content with a new text
chatbot += ((text, None))
# Check if only the file is provided
elif file and not text:
# Concatenate the existing chatbot content with a new file content
chatbot += (((file,), None))
else:
# Raise an error if neither text nor file is provided
raise gr.Error("Enter a valid text or a file")
# Return the updated chatbot content
return chatbot
La función recibe el texto, el chatbot y la ruta del archivo. El chatbot es una lista de listas de tuplas. El primer miembro de la tupla es la consulta del usuario y el segundo es la respuesta del chatbot. Para enviar archivos multimedia, reemplazamos la cadena con otra tupla. El primer miembro de esta tupla es la ruta del archivo o URL y el segundo es el texto alternativo. Esta es la convención para mostrar medios en la interfaz de usuario del chat en Gradio.
Ahora, crearemos una clase con métodos para manejar las respuestas de la API de Gemini.
from typing import Union, ByteString
from gradio import Part, GenerationConfig, GenerativeModel
class GeminiGenerator:
"""Multi-modal generator class for Gemini models"""
def _convert_part(self, part: Union(str, ByteString, Part)) -> Part:
# Convert different types of parts (str, ByteString, Part) to Part objects
if isinstance(part, str):
return Part.from_text(part)
elif isinstance(part, ByteString):
return Part.from_data(part.data, part.mime_type)
elif isinstance(part, Part):
return part
else:
msg = f"Unsupported type {type(part)} for part {part}"
raise ValueError(msg)
def _check_file(self, file):
# Check if file is provided
if file:
return True
return False
def run(self, history, text: str, file: str, model: str, stream: bool, temperature: float,
stop_sequence: str, top_k: int, top_p: float):
# Configure generation parameters
generation_config = GenerationConfig(
temperature=temperature,
top_k=top_k,
top_p=top_p,
stop_sequences=stop_sequence
)
self.client = GenerativeModel(model_name=model, generation_config=generation_config,)
# Generate content based on input parameters
if text and self._check_file(file):
# Convert text and file to Part objects and generate content
contents = (self._convert_part(part) for part in (text, file))
response = self.client.generate_content(contents=contents, stream=stream)
elif text:
# Convert text to a Part object and generate content
content = self._convert_part(text))
response = self.client.generate_content(contents=content, stream=stream)
elif self._check_file(file):
# Convert file to a Part object and generate content
content = self._convert_part(file)
response = self.client.generate_content(contents=content, stream=stream)
# Check if streaming is True
if stream:
# Update history and yield responses for streaming
history(-1)(-1) = ""
for resp in response:
history(-1)(-1) += resp.candidates(0).content.parts(0).text
yield "", gr.File(value=None), history
else:
# Append the generated content to the chatbot history
history.append((None, response.candidates(0).content.parts(0).text))
return " ", gr.File(value=None), history
En el fragmento de código anterior, hemos definido una clase GeminiGenerator. run() inicia un cliente con un nombre de modelo y una configuración de generación. Luego, obtenemos respuestas de los modelos Gemini en función de los datos proporcionados. _convert_part() convierte los datos en un objeto Part. Generate_content() requiere que los datos sean una cadena, una imagen o una pieza. Aquí, convertimos cada dato a Parte para mantener la homogeneidad.
Ahora, inicie un objeto con la clase.
gemini-generator = GeminiGenerator()Necesitamos definir la función reset_parameter. Esto restablece los parámetros a los valores predeterminados.
def reset() -> List(Component):
return (
gr.Dropdown(value = "gemini-pro",choices=("gemini-pro", "gemini-pro-vision"),
label="Model",
info="Choose a model", interactive=True),
gr.Radio(label="Streaming", choices=(True, False), value=True, interactive=True,
info="Stream while responses are generated"),
gr.Slider(value= 0.6,maximum=1.0, label="Temparature", interactive=True),
gr.Textbox(label="Token limit", value=2048),
gr.Textbox(label="stop Sequence",
info="Stops generation when the string is encountered."),
gr.Slider(
value=40,
label="Top-k",
interactive=True,
info="""Top-k changes how the model selects tokens for output: lower = less
random, higher = more diverse. Defaults to 40."""
),
gr.Slider(
value=8,
label="Top-p",
interactive=True,
info="""Top-p changes how the model selects tokens for output.
Tokens are selected from most probable to least until
the sum of their probabilities equals the top-p value"""
)
)Aquí, simplemente devolvemos los valores predeterminados. Esto restablece los parámetros.
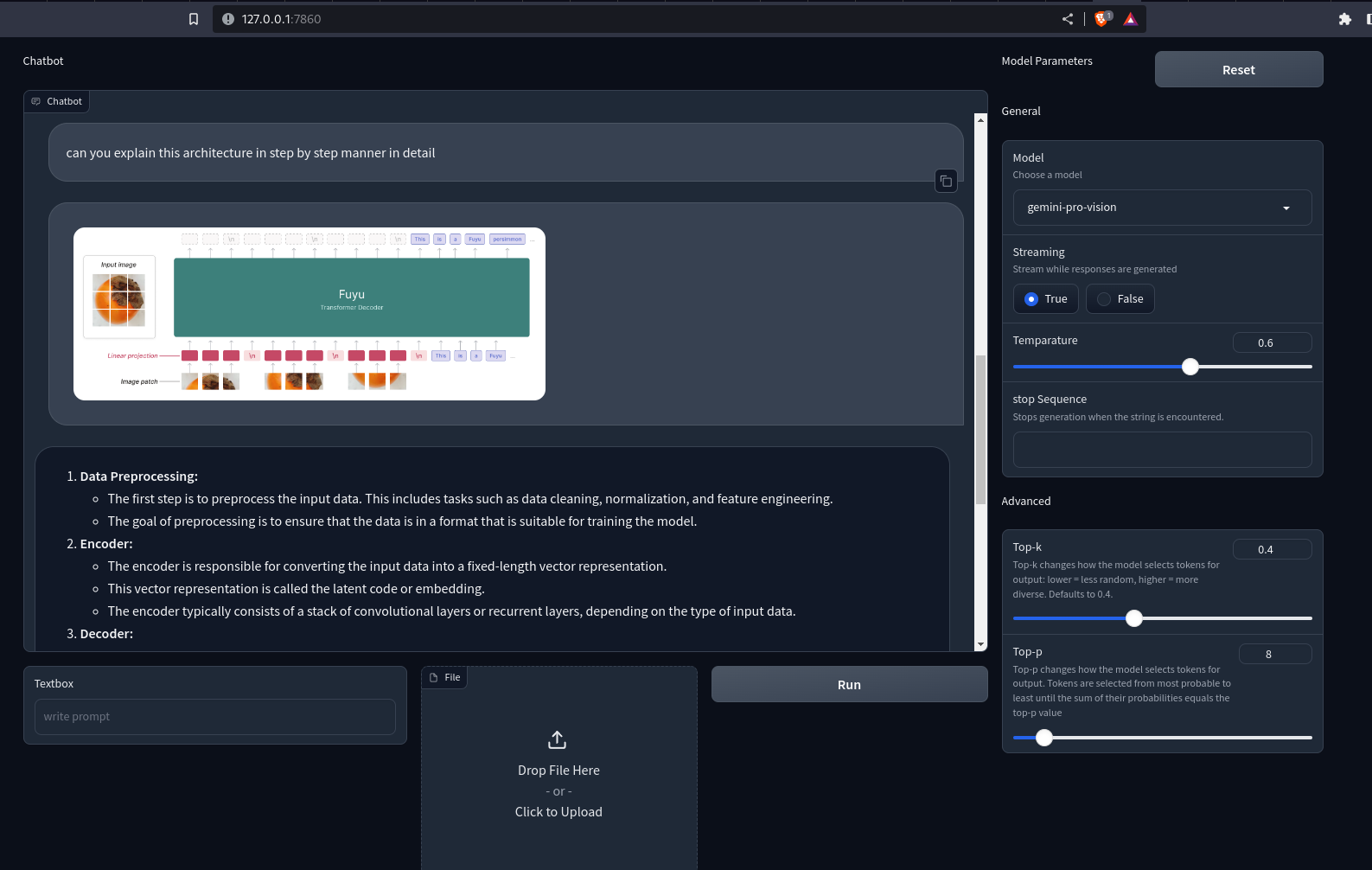
Ahora recarga la aplicación en localhost. Ahora puede enviar consultas de texto e imágenes/videos a los modelos Gemini. Las respuestas se mostrarán en el chatbot. Si la transmisión se establece en Verdadero, los fragmentos de respuesta se representarán progresivamente de uno en uno.
Producción
Aquí está el repositorio de GitHub para la aplicación Gradio: sunilkumardash9/chatbot-multimodal
Conclusión
¡Espero que hayas disfrutado creando un bot de control de calidad con Gemini y Gradio!
El modelo multimodal de Google puede resultar útil para varios casos de uso. Un chatbot personalizado impulsado por él es uno de esos casos de uso. Podemos ampliar la aplicación para incluir diferentes funciones, como agregar otros modelos como GPT-4 y otros modelos de código abierto. Entonces, en lugar de saltar de un sitio web a otro, puede tener su propio agregador de LLM. De manera similar, podemos ampliar la aplicación para admitir RAG multimodal, narración de video, extracción de entidades visuales, etc.
Conclusiones clave
- Gemini es una familia de modelos con tres clases de modelos. Ultra, Pro y Nano.
- Los modelos se han entrenado conjuntamente en múltiples modalidades para lograr una comprensión multimodal de última generación.
- Si bien el Ultra es el modelo más capaz, Google solo ha hecho públicos los modelos Pro.
- Se puede acceder a Gemini Pro y a los modelos de visión desde Google Cloud VertexAI o Google ai Studio.
- Gradio es una herramienta Python de código abierto para crear demostraciones web rápidas de aplicaciones de aprendizaje automático.
- Usamos la API de bloques de Gradio y otras funciones para crear un bot de control de calidad interactivo utilizando modelos Gemini.
Preguntas frecuentes
R. Si bien Google afirma que Gemini Ultra es un mejor modelo, aún no se ha hecho público. Los modelos disponibles públicamente de Gemini son más similares al gpt-3.5-turbo en rendimiento bruto que al GPT-4.
R. Se puede acceder a los modelos Gemini Pro y Gemini Pro Vision de forma gratuita en Google ai Studio para desarrolladores con 60 solicitudes por minuto.
A. Un chatbot que puede procesar y comprender diferentes modalidades de datos, como textos, imágenes, audio, videos, etc.
R. Es una herramienta Python de código abierto que le permite compartir rápidamente modelos de aprendizaje automático con cualquier persona.
R. Gradio Interface es una clase poderosa y de alto nivel que permite la creación rápida de una interfaz gráfica de usuario (GUI) basada en web con solo unas pocas líneas de código.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.