
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio. With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines, the ML workflow orchestration feature of Amazon SageMaker. Furthermore, you can create a multi-step ML workflow with multiple dependent notebooks using these APIs.
SageMaker Pipelines is a native workflow orchestration tool for building ML pipelines that take advantage of direct SageMaker integration. Each SageMaker pipeline is composed of steps, which correspond to individual tasks such as processing, training, or data processing using Amazon EMR. SageMaker notebook jobs are now available as a built-in step type in SageMaker pipelines. You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Additionally, you can stitch multiple dependent notebooks together to create a workflow in the form of Directed Acyclic Graphs (DAGs). You can then run these notebooks jobs or DAGs, and manage and visualize them using SageMaker Studio.
Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs. These jobs can be run immediately or on a recurring time schedule without the need for data workers to refactor code as Python modules. Some common use cases for doing this include:
- Running long running-notebooks in the background
- Regularly running model inference to generate reports
- Scaling up from preparing small sample datasets to working with petabyte-scale big data
- Retraining and deploying models on some cadence
- Scheduling jobs for model quality or data drift monitoring
- Exploring the parameter space for better models
Although this functionality makes it straightforward for data workers to automate standalone notebooks, ML workflows are often comprised of several notebooks, each performing a specific task with complex dependencies. For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Furthermore, data scientists might want to trigger this entire workflow on a recurring schedule to update the model based on new data. To enable you to easily automate your notebooks and create such complex workflows, SageMaker notebook jobs are now available as a step in SageMaker Pipelines. In this post, we show how you can solve the following use cases with a few lines of code:
- Programmatically run a standalone notebook immediately or on a recurring schedule
- Create multi-step workflows of notebooks as DAGs for continuous integration and continuous delivery (CI/CD) purposes that can be managed via the SageMaker Studio UI
Solution overview
The following diagram illustrates our solution architecture. You can use the SageMaker Python SDK to run a single notebook job or a workflow. This feature creates a SageMaker training job to run the notebook.
In the following sections, we walk through a sample ML use case and showcase the steps to create a workflow of notebook jobs, passing parameters between different notebook steps, scheduling your workflow, and monitoring it via SageMaker Studio.
For our ML problem in this example, we are building a sentiment analysis model, which is a type of text classification task. The most common applications of sentiment analysis include social media monitoring, customer support management, and analyzing customer feedback. The dataset being used in this example is the Stanford Sentiment Treebank (SST2) dataset, which consists of movie reviews along with an integer (0 or 1) that indicates the positive or negative sentiment of the review.
The following is an example of a data.csv file corresponding to the SST2 dataset, and shows values in its first two columns. Note that the file shouldn’t have any header.
| Column 1 | Column 2 |
| 0 | hide new secretions from the parental units |
| 0 | contains no wit , only labored gags |
| 1 | that loves its characters and communicates something rather beautiful about human nature |
| 0 | remains utterly satisfied to remain the same throughout |
| 0 | on the worst revenge-of-the-nerds clichés the filmmakers could dredge up |
| 0 | that ‘s far too tragic to merit such superficial treatment |
| 1 | demonstrates that the director of such hollywood blockbusters as patriot games can still turn out a small , personal film with an emotional wallop . |
In this ML example, we must perform several tasks:
- Perform feature engineering to prepare this dataset in a format our model can understand.
- Post-feature engineering, run a training step that uses Transformers.
- Set up batch inference with the fine-tuned model to help predict the sentiment for new reviews that come in.
- Set up a data monitoring step so that we can regularly monitor our new data for any drift in quality that might require us to retrain the model weights.
With this launch of a notebook job as a step in SageMaker pipelines, we can orchestrate this workflow, which consists of three distinct steps. Each step of the workflow is developed in a different notebook, which are then converted into independent notebook jobs steps and connected as a pipeline:
- Preprocessing – Download the public SST2 dataset from Amazon Simple Storage Service (Amazon S3) and create a CSV file for the notebook in Step 2 to run. The SST2 dataset is a text classification dataset with two labels (0 and 1) and a column of text to categorize.
- Training – Take the shaped CSV file and run fine-tuning with BERT for text classification utilizing Transformers libraries. We use a test data preparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model.
- Transform and monitor – Perform batch inference and set up data quality with model monitoring to have a baseline dataset suggestion.
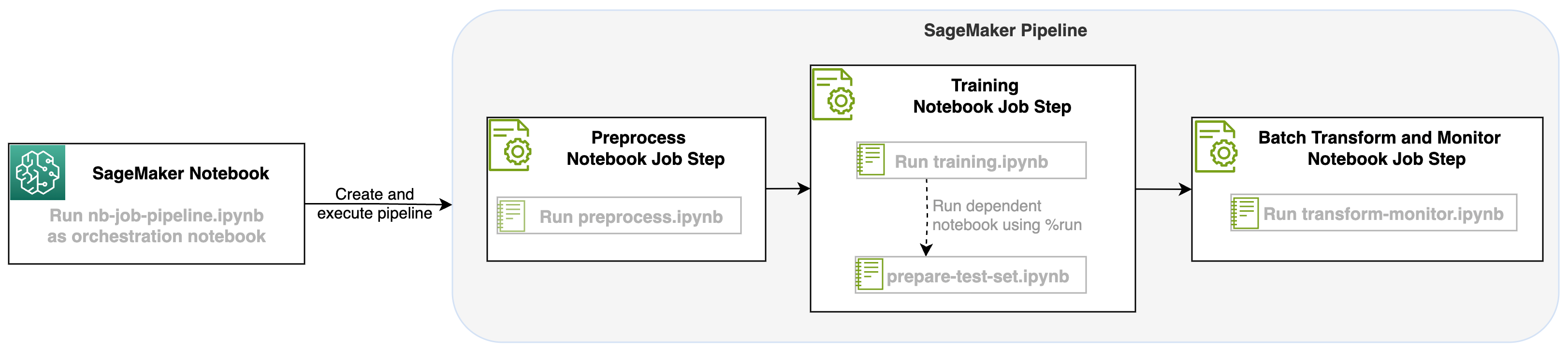
Run the notebooks
The sample code for this solution is available on GitHub.
Creating a SageMaker notebook job step is similar to creating other SageMaker Pipeline steps. In this notebook example, we use the SageMaker Python SDK to orchestrate the workflow. To create a notebook step in SageMaker Pipelines, you can define the following parameters:
- Input notebook – The name of the notebook that this notebook step will be orchestrating. Here you can pass in the local path to the input notebook. Optionally, if this notebook has other notebooks it’s running, you can pass these in the
AdditionalDependenciesparameter for the notebook job step. - Image URI – The Docker image behind the notebook job step. This can be the predefined images that SageMaker already provides or a custom image that you have defined and pushed to Amazon Elastic Container Registry (Amazon ECR). Refer to the considerations section at the end of this post for supported images.
- Kernel name – The name of the kernel that you are using on SageMaker Studio. This kernel spec is registered in the image that you have provided.
- Instance type (optional) – The Amazon Elastic Compute Cloud (Amazon EC2) instance type behind the notebook job that you have defined and will be running.
- Parameters (optional) – Parameters you can pass in that will be accessible for your notebook. These can be defined in key-value pairs. Additionally, these parameters can be modified between various notebook job runs or pipeline runs.
Our example has a total of five notebooks:
- nb-job-pipeline.ipynb – This is our main notebook where we define our pipeline and workflow.
- preprocess.ipynb – This notebook is the first step in our workflow and contains the code that will pull the public AWS dataset and create a CSV file out of it.
- training.ipynb – This notebook is the second step in our workflow and contains code to take the CSV from the previous step and conduct local training and fine-tuning. This step also has a dependency from the
prepare-test-set.ipynbnotebook to pull down a test dataset for sample inference with the fine-tuned model. - prepare-test-set.ipynb – This notebook creates a test dataset that our training notebook will use in the second pipeline step and use for sample inference with the fine-tuned model.
- transform-monitor.ipynb – This notebook is the third step in our workflow and takes the base BERT model and runs a SageMaker batch transform job, while also setting up data quality with model monitoring.
Next, we walk through the main notebook nb-job-pipeline.ipynb, which combines all the sub-notebooks into a pipeline and runs the end-to-end workflow. Note that although the following example only runs the notebook one time, you can also schedule the pipeline to run the notebook repeatedly. Refer to SageMaker documentation for detailed instructions.
For our first notebook job step, we pass in a parameter with a default S3 bucket. We can use this bucket to dump any artifacts we want available for our other pipeline steps. For the first notebook (preprocess.ipynb), we pull down the AWS public SST2 train dataset and create a training CSV file out of it that we push to this S3 bucket. See the following code:
We can then convert this notebook in a NotebookJobStep with the following code in our main notebook:
Now that we have a sample CSV file, we can start training our model in our training notebook. Our training notebook takes in the same parameter with the S3 bucket and pulls down the training dataset from that location. Then we perform fine-tuning by using the Transformers trainer object with the following code snippet:
After fine-tuning, we want to run some batch inference to see how the model is performing. This is done using a separate notebook (prepare-test-set.ipynb) in the same local path that creates a test dataset to perform inference on using our trained model. We can run the additional notebook in our training notebook with the following magic cell:
We define this extra notebook dependency in the AdditionalDependencies parameter in our second notebook job step:
We must also specify that the training notebook job step (Step 2) depends on the Preprocess notebook job step (Step 1) by using the add_depends_on API call as follows:
Our last step, will take the BERT model run a SageMaker Batch Transform, while also setting up Data Capture and Quality via SageMaker Model Monitor. Note that this is different from using the built-in Transform or Capture steps via Pipelines. Our notebook for this step will execute those same APIs, but will be tracked as a Notebook Job Step. This step is dependent on the Training Job Step that we previously defined, so we also capture that with the depends_on flag.
After the various steps of our workflow have been defined, we can create and run the end-to-end pipeline:
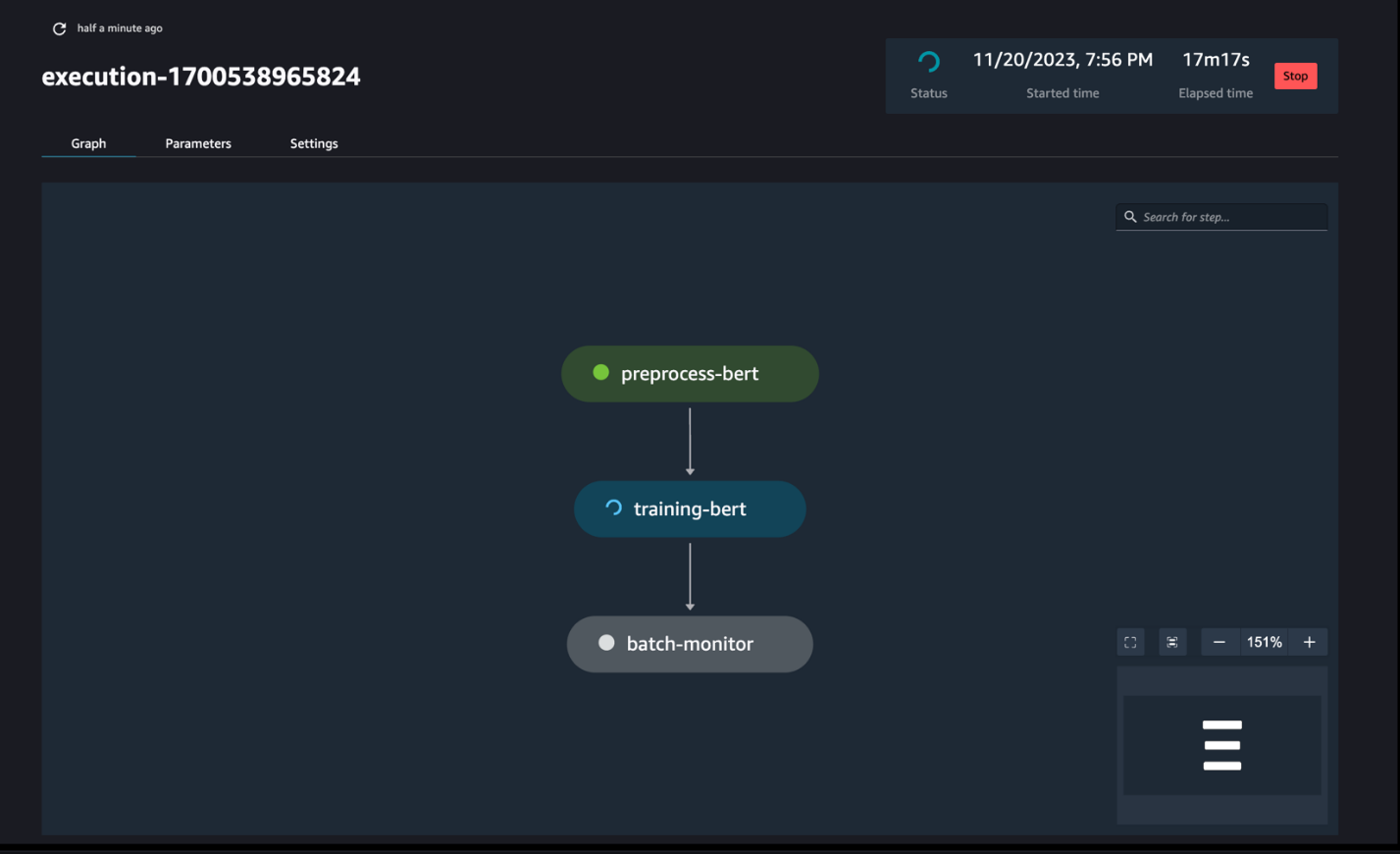
Monitor the pipeline runs
You can track and monitor the notebook step runs via the SageMaker Pipelines DAG, as seen in the following screenshot.
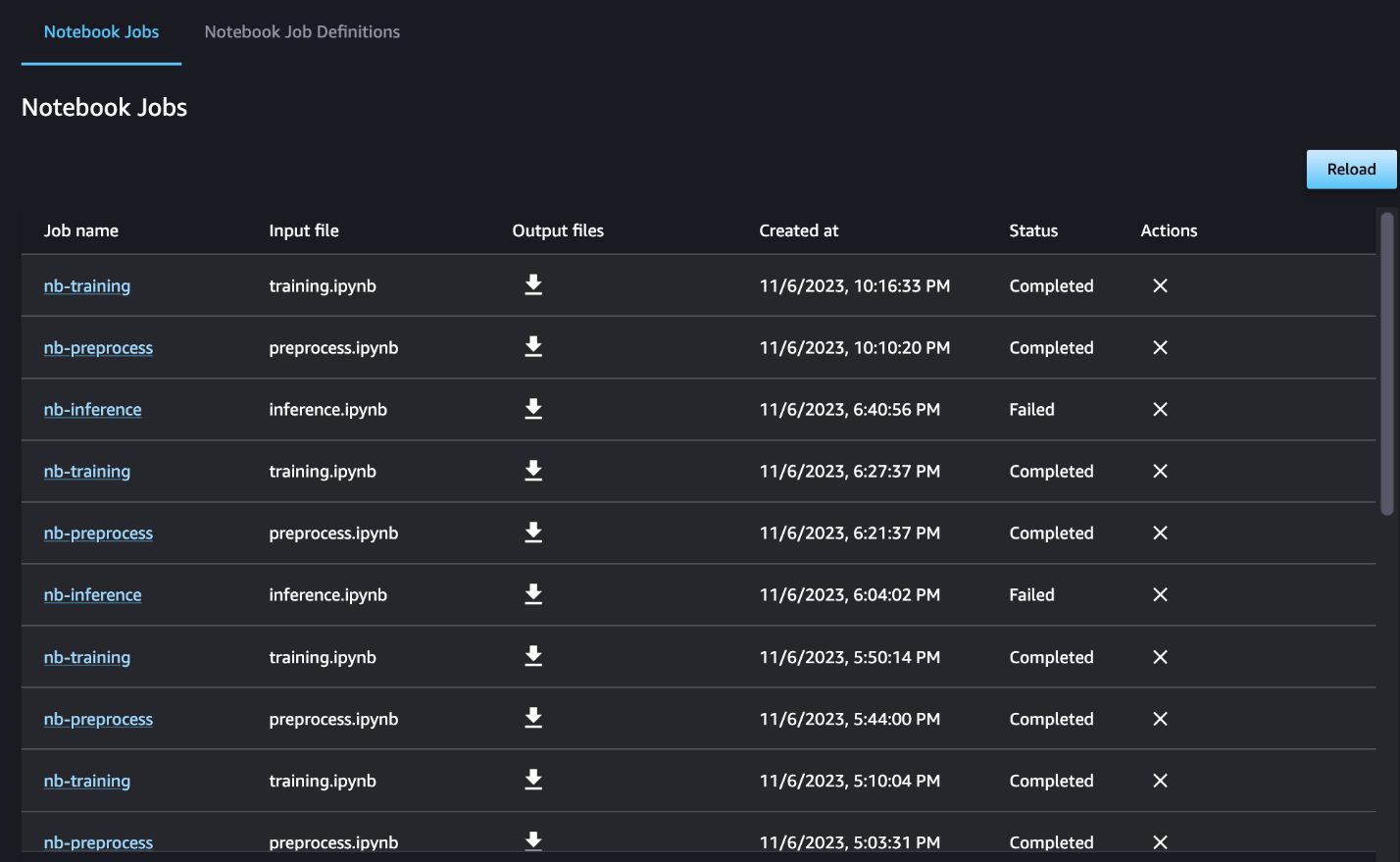
You can also optionally monitor the individual notebook runs on the notebook job dashboard and toggle the output files that have been created via the SageMaker Studio UI. When using this functionality outside of SageMaker Studio, you can define the users who can track the run status on the notebook job dashboard by using tags. For more details about tags to include, see View your notebook jobs and download outputs in the Studio UI dashboard.
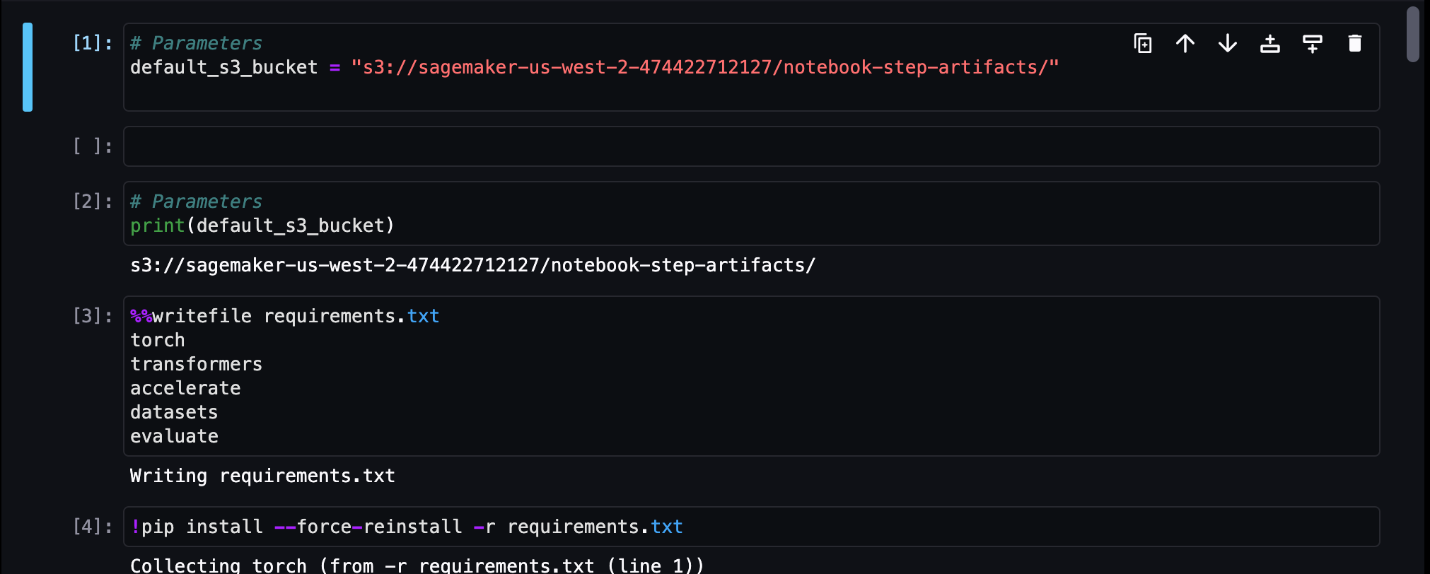
For this example, we output the resulting notebook jobs to a directory called outputs in your local path with your pipeline run code. As shown in the following screenshot, here you can see the output of your input notebook and also any parameters you defined for that step.
Clean up
If you followed along with our example, be sure to delete the created pipeline, notebook jobs and the s3 data downloaded by the sample notebooks.
Considerations
The following are some important considerations for this feature:
- SDK constraints – The notebook job step can only be created via the SageMaker Python SDK.
- Image constraints –The notebook job step supports the following images:
Conclusion
With this launch, data workers can now programmatically run their notebooks with a few lines of code using the SageMaker Python SDK. Additionally, you can create complex multi-step workflows using your notebooks, significantly reducing the time needed to move from a notebook to a CI/CD pipeline. After creating the pipeline, you can use SageMaker Studio to view and run DAGs for your pipelines and manage and compare the runs. Whether you’re scheduling end-to-end ML workflows or a part of it, we encourage you to try notebook-based workflows.
About the authors
 Anchit Gupta is a Senior Product Manager for Amazon SageMaker Studio. She focuses on enabling interactive data science and data engineering workflows from within the SageMaker Studio IDE. In her spare time, she enjoys cooking, playing board/card games, and reading.
Anchit Gupta is a Senior Product Manager for Amazon SageMaker Studio. She focuses on enabling interactive data science and data engineering workflows from within the SageMaker Studio IDE. In her spare time, she enjoys cooking, playing board/card games, and reading.
 Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their ai/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their ai/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
 Edward Sun is a Senior SDE working for SageMaker Studio at Amazon Web Services. He is focused on building interactive ML solution and simplifying the customer experience to integrate SageMaker Studio with popular technologies in data engineering and ML ecosystem. In his spare time, Edward is big fan of camping, hiking and fishing and enjoys the time spending with his family.
Edward Sun is a Senior SDE working for SageMaker Studio at Amazon Web Services. He is focused on building interactive ML solution and simplifying the customer experience to integrate SageMaker Studio with popular technologies in data engineering and ML ecosystem. In his spare time, Edward is big fan of camping, hiking and fishing and enjoys the time spending with his family.






{kind=link}