
Generative ai models have the potential to revolutionize business operations, but companies must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of ai-generated content.
The Retrieval Augmented Generation (RAG) framework augments cues with external data from multiple sources, such as document repositories, databases, or APIs, to make basic models effective for domain-specific tasks. This post introduces the capabilities of the RAG model and highlights the transformative potential of MongoDB Atlas with its vector search functionality.
MongoDB Atlas is an integrated set of data services that accelerates and simplifies the development of data-driven applications. Its vector data warehouse integrates seamlessly with operational data warehouse, eliminating the need for a separate database. This integration enables powerful semantic search capabilities through Vector Searcha fast way to create semantic search and ai-powered applications.
Amazon SageMaker enables businesses to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pretrained models and data to help you get started with machine learning. You can access, customize, and deploy pre-trained models and data through the SageMaker JumpStart home page in Amazon SageMaker Studio with just a few clicks.
Amazon Lex is a conversational interface that helps businesses create chatbots and voice robots that engage in natural, realistic interactions. By integrating Amazon Lex with generative ai, businesses can create a holistic ecosystem where user input is seamlessly transformed into coherent, contextually relevant responses.
Solution Overview
The following diagram illustrates the architecture of the solution.
In the following sections, we explain the steps to implement this solution and its components.
Set up a MongoDB cluster
To create a free tier MongoDB Atlas cluster, follow the instructions at Create a cluster. Configure the database access and network access.
Implement the SageMaker embedding model
You can choose the embedding model (ALL MiniLM L6 v2) in the SageMaker JumpStart Models, Laptops, Solutions page.
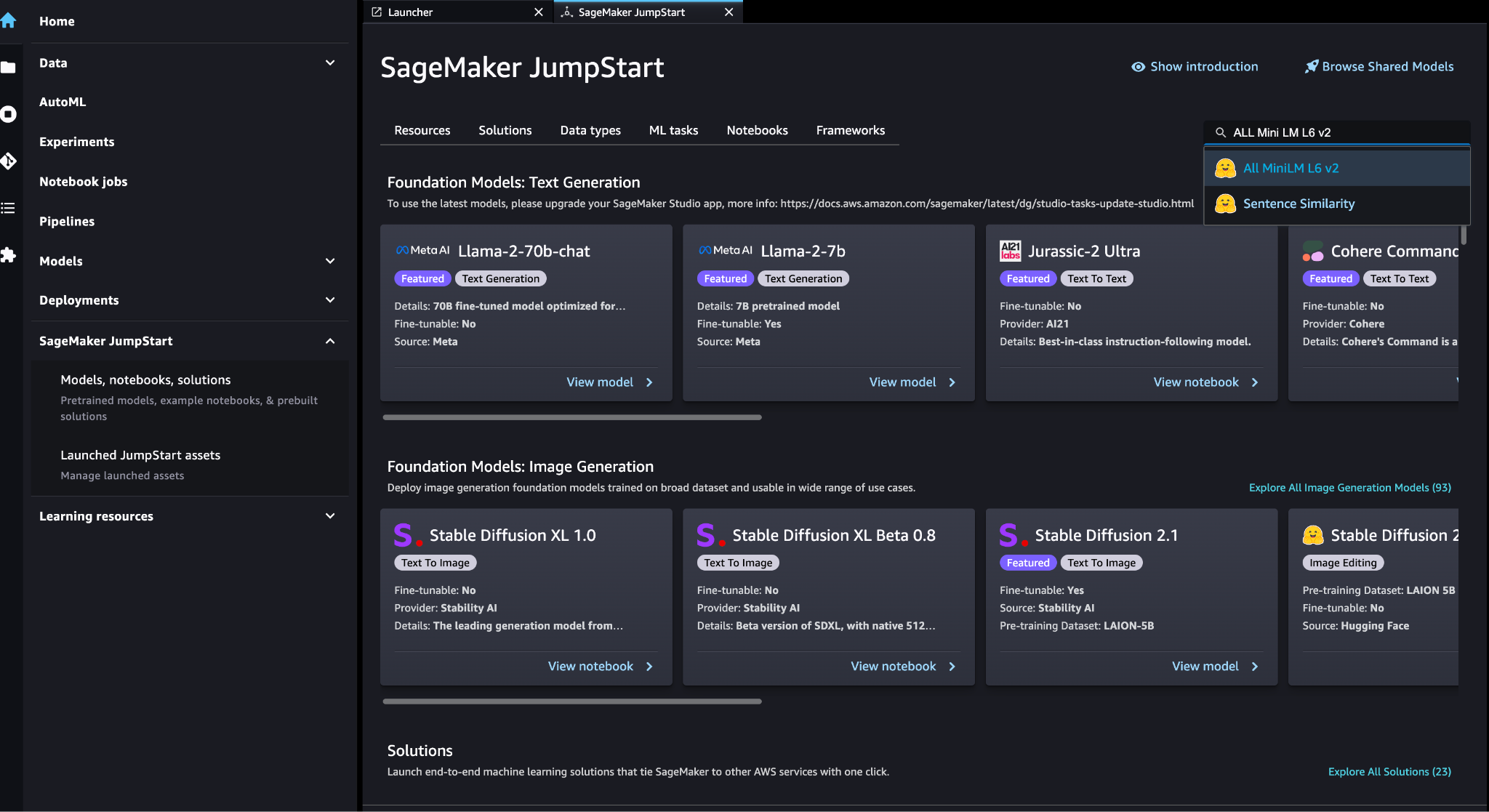
Choose Deploy to display the model.
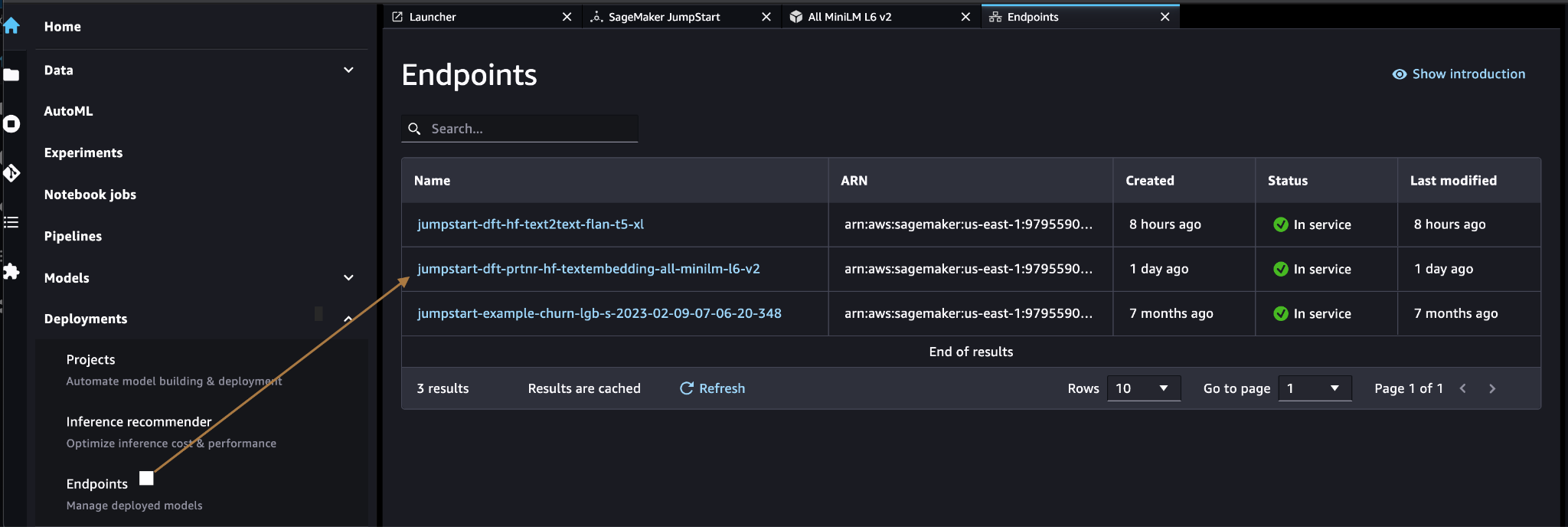
Verify that the model was deployed correctly and verify that the endpoint was created.
Vector embedding
ai-applications-vector-search-open-source-models/#what-are-vector-embeddings-” target=”_blank” rel=”noopener”>Vector embedding is a process of converting a text or image into a vector representation. Using the following code, we can generate vector embeds with SageMaker JumpStart and update the collection with the vector created for each document:
payload = {"text_inputs": (document(field_name_to_be_vectorized))}
query_response = query_endpoint_with_json_payload(json.dumps(payload).encode('utf-8'))
embeddings = parse_response_multiple_texts(query_response)
# update the document
update = {'$set': {vector_field_name : embeddings(0)}}
collection.update_one(query, update)The code above shows how to update a single object in a collection. To update all objects follow the instructions.
MongoDB vector data store
MongoDB Atlas Vector Search is a new feature that allows you to store and search vector data in MongoDB. Vector data is a type of data that represents a point in a high-dimensional space. This type of data is often used in machine learning and artificial intelligence applications. MongoDB Atlas Vector Search uses a technique called k-nearest neighbors (k-NN) to find similar vectors. k-NN works by finding the k vectors most similar to a given vector. The most similar vectors are those that are closest to the given vector in terms of Euclidean distance.
Storing vector data alongside operational data can improve performance by reducing the need to move data between different storage systems. This is especially beneficial for applications that require real-time access to vector data.
Create a vector search index
The next step is to create a MongoDB Vector Search Index in the vector field you created in the previous step. MongoDB uses the knnVector type to index vector embeddings. The vector field must be represented as an array of numbers (BSON int32, int64, or double data types only).
Refer to Review knnVector type limitations For more information about the limitations of the knnVector guy.
The following code is an example index definition:
{
"mappings": {
"dynamic": true,
"fields": {
"egVector": {
"dimensions": 384,
"similarity": "euclidean",
"type": "knnVector"
}
}
}
}
Note that the dimension must match the dimension of the embedding model.
Query the vector data store
You can query the vector data store using the Vector Search Aggregation Pipeline. Use the vector search index and perform a semantic search in the vector data store.
The following code is an example search definition:
{
$search: {
"index": "<index name>", // optional, defaults to "default"
"knnBeta": {
"vector": (<array-of-numbers>),
"path": "<field-to-search>",
"filter": {<filter-specification>},
"k": <number>,
"score": {<options>}
}
}
}
Implement the SageMaker Large Language Model
SageMaker JumpStart base models are pre-trained large language models (LLMs) that are used to solve a variety of natural language processing (NLP) tasks, such as text summarization, question answering, and natural language inference. . They are available in a variety of sizes and configurations. In this solution, we use the Hugging Face FLAN-T5-XL model.
Find model FLAN-T5-XL in SageMaker JumpStart.
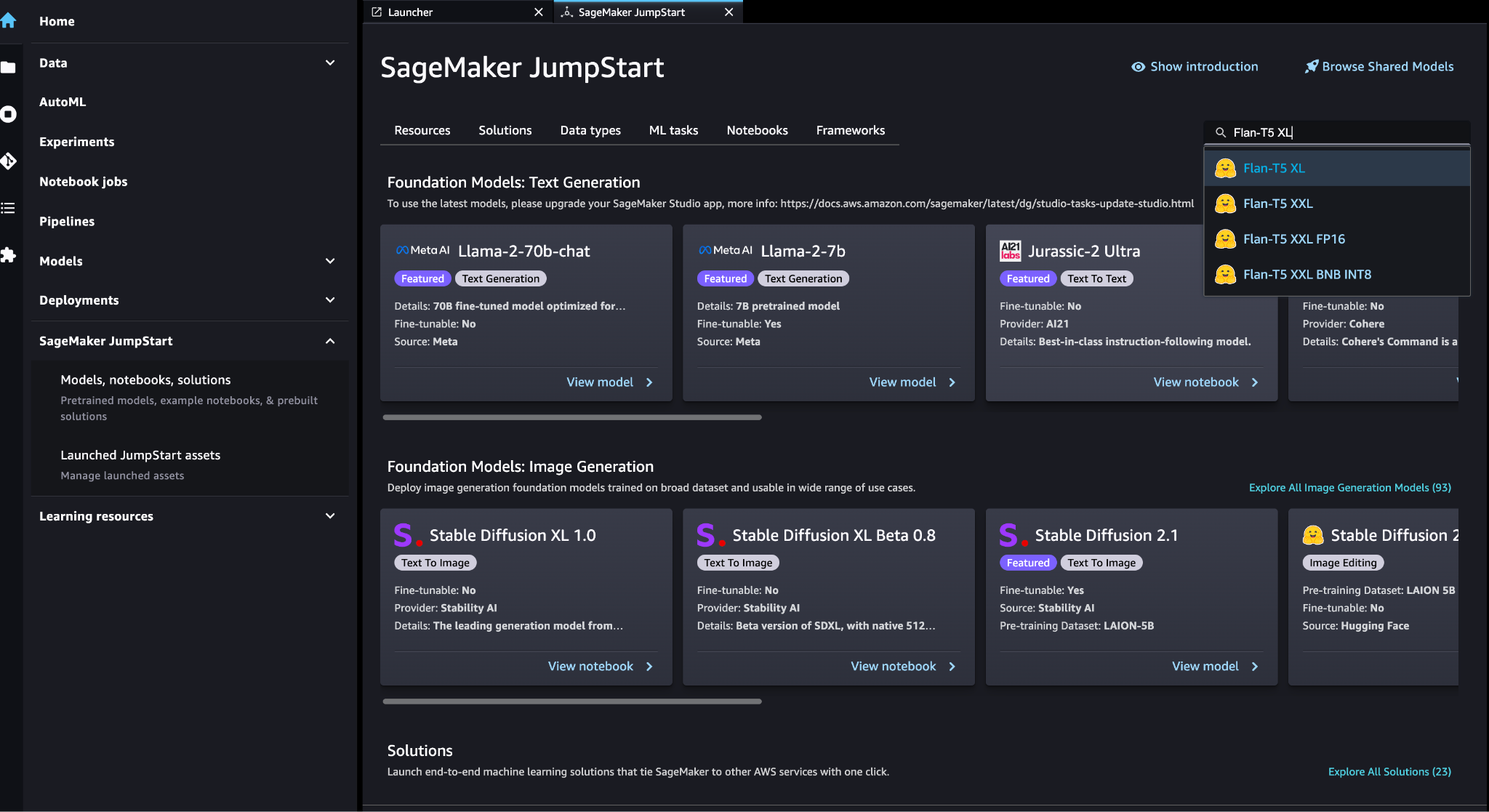
Choose Deploy to configure the FLAN-T5-XL model.
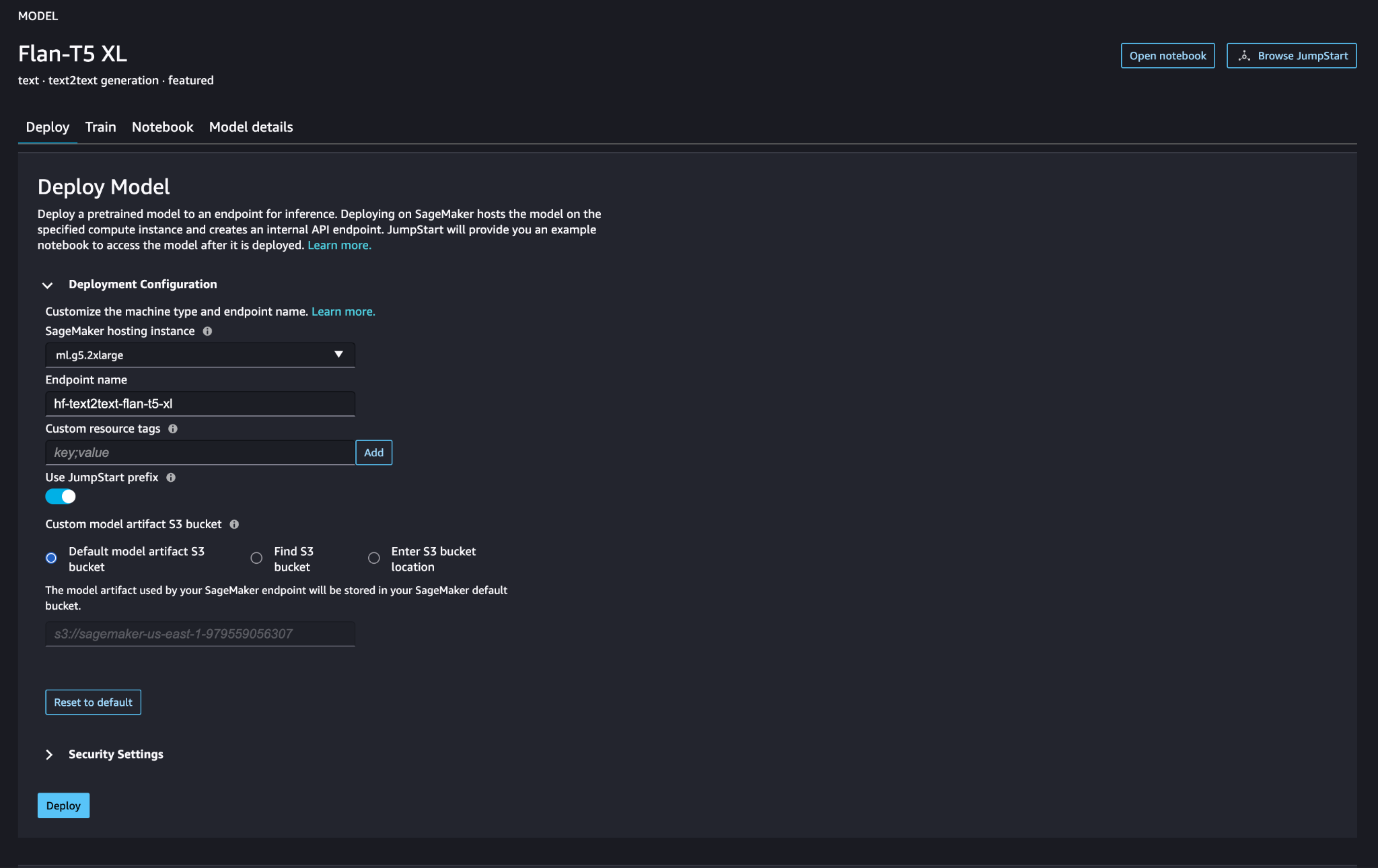
Verify that the model has been deployed correctly and that the endpoint is active.
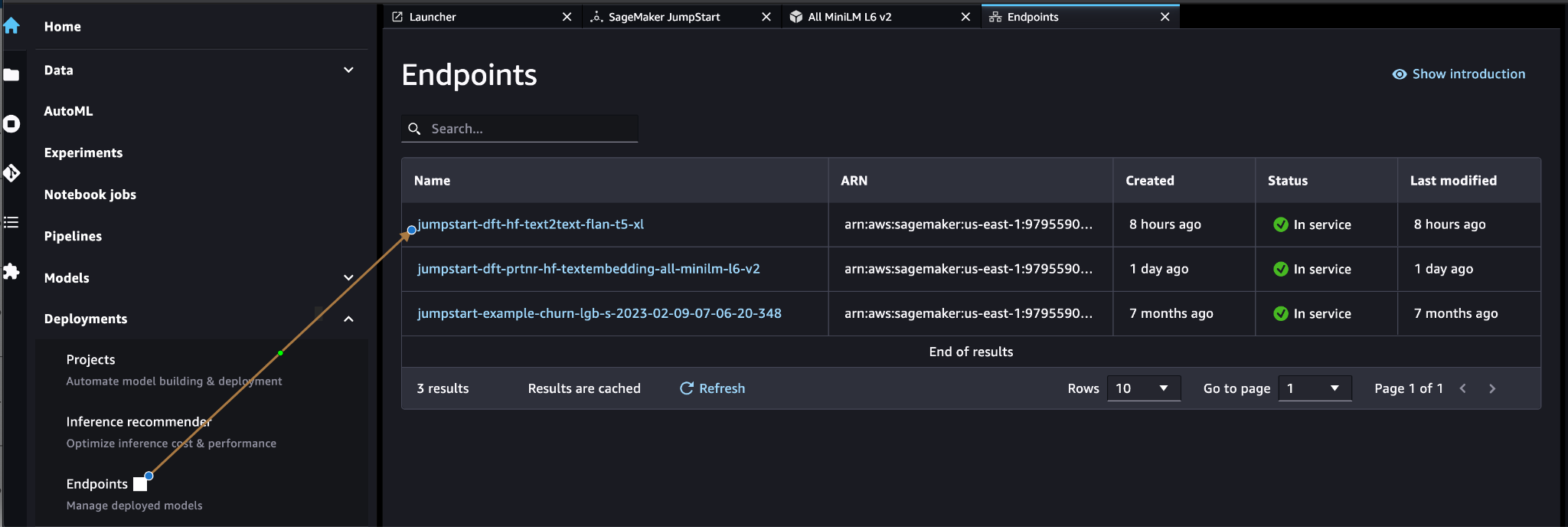
Create an Amazon Lex bot
To create an Amazon Lex bot, complete the following steps:
- In the Amazon Lex console, choose create robot.
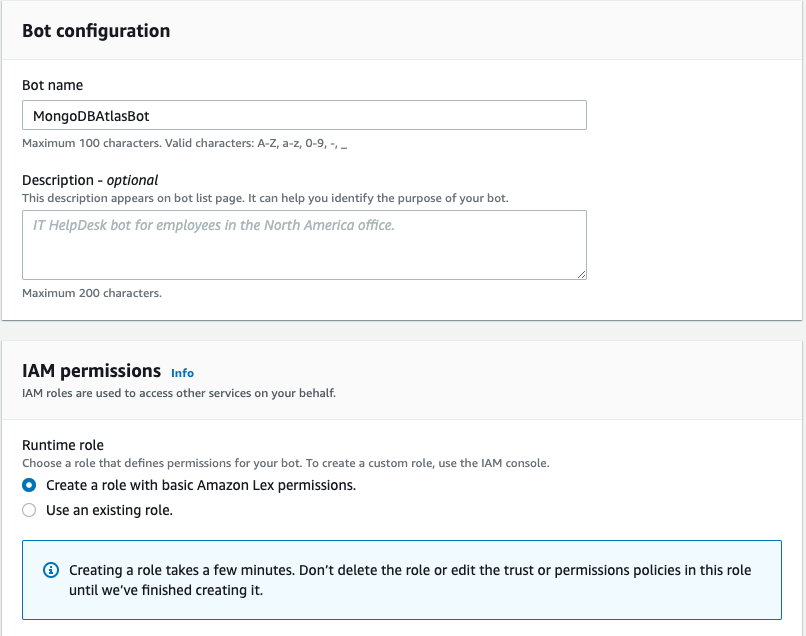
- For Robot nameenter a name.
- For runtime roleselect Create a role with basic Amazon Lex permissions.
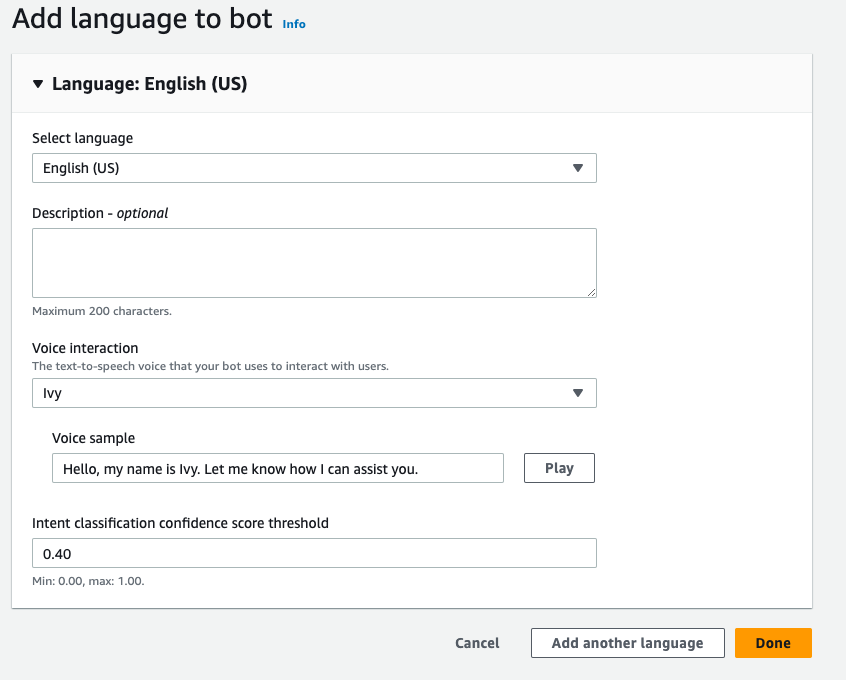
- Specify your language settings and then choose Made.
- Add a sample sentence in the
NewIntentUI and choose Save intent.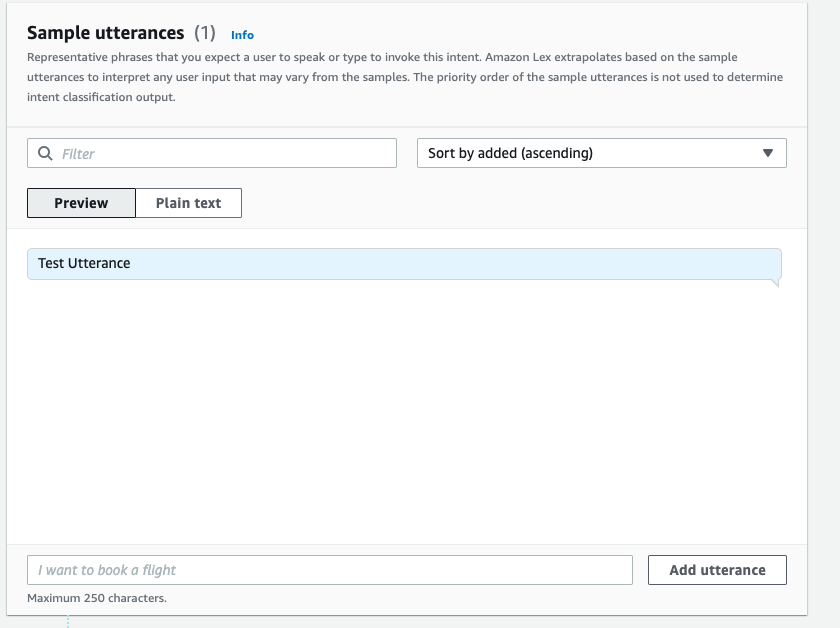
- Navigate to the
FallbackIntentwhich was created for you by default and toggle Asset in it Compliance section.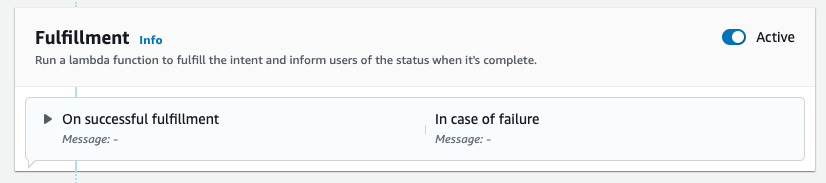
- Choose Build and after the build is successful, choose Proof.
- Before taking the test, choose the gear icon.
- Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. To create the lambda function follow this steps.
- You can now interact with the LLM.
Clean
To clean up your resources, complete the following steps:
- Remove Amazon Lex bot.
- Delete the Lambda function.
- Delete the LLM SageMaker endpoint.
- Remove the SageMaker endpoint from the embed model.
- Delete the MongoDB Atlas cluster.
Conclusion
In the post, we show how to create a simple bot that uses MongoDB Atlas semantic search and integrates with a SageMaker JumpStart model. This bot allows you to quickly prototype user interaction with different LLMs in SageMaker Jumpstart while combining them with context originating from MongoDB Atlas.
As always, AWS welcomes feedback. Leave your comments and questions in the comments section.
About the authors

Igor Alekseev He is a Senior Partner Solutions Architect at AWS in the data and analytics domain. In his role, Igor works with strategic partners helping them build complex architectures optimized for AWS. Before joining AWS, as a Data/Solutions Architect, he implemented many projects in the Big Data domain, including several data lakes in the Hadoop ecosystem. As a data engineer, he was involved in applying ai/ML to fraud detection and office automation.
 Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he works with AWS to create technical integrations and reference architectures for AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies. He is passionate about providing technical solutions to clients working with multiple global systems integrators (GSIs) across multiple geographies.
Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he works with AWS to create technical integrations and reference architectures for AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies. He is passionate about providing technical solutions to clients working with multiple global systems integrators (GSIs) across multiple geographies.






{kind=link}