
Introducción
La introducción a herramientas como LangChain y LangFlow ha facilitado las cosas a la hora de crear aplicaciones con modelos de lenguaje grandes. Aunque crear aplicaciones y elegir diferentes modelos de lenguaje grande se ha vuelto más fácil, la parte de carga de datos, donde los datos provienen de varias fuentes, todavía requiere mucho tiempo para los desarrolladores mientras desarrollan aplicaciones impulsadas por LLM, ya que los desarrolladores necesitan convertir datos de estas diversas fuentes en texto plano antes de inyectarlos en tiendas de vectores. Aquí es donde entra en juego Embedchain, que simplifica la carga de datos de cualquier tipo y comienza a consultar el LLM al instante. En este artículo, exploraremos cómo empezar con embedchain.
Objetivos de aprendizaje
- Comprender la importancia de la cadena integrada para simplificar el proceso de gestión y consulta de datos para modelos de lenguajes grandes (LLM)
- Aprenda cómo integrar y cargar de manera efectiva datos no estructurados en la cadena integrada, lo que permite a los desarrolladores trabajar con varias fuentes de datos sin problemas.
- Conocer los diferentes modelos de lenguajes grandes y almacenes de vectores soportados por embedchain
- Descubra cómo agregar varias fuentes de datos, como páginas web y videos, al almacén de vectores, entendiendo así la ingesta de datos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué es la cadena integrada?
Embedchain es una biblioteca de Python/Javascript, con la que un desarrollador puede conectar múltiples fuentes de datos con modelos de lenguaje grandes sin problemas. Embedchain nos permite cargar, indexar y recuperar datos no estructurados. Los datos no estructurados pueden ser de cualquier tipo, como un texto, una URL a un sitio web/vídeo de YouTube, una imagen, etc.
Emdechain simplifica la carga de estos datos no estructurados con un solo comando, creando así incrustaciones de vectores para ellos y comenzando a consultar instantáneamente los datos con el LLM conectado. Detrás de escena, embedchain se encarga de cargar los datos desde la fuente, fragmentarlos, luego crear incrustaciones de vectores para ellos y finalmente almacenarlos en un almacén de vectores.
Creando la primera aplicación con Embedchain
En esta sección, instalaremos el paquete embedchain y crearemos una aplicación con él. El primer paso sería utilizar el comando pip para instalar el paquete como se muestra a continuación:
!pip install embedchain
!pip install embedchain(huggingface-hub)- La primera declaración instalará el paquete Python embedchain
- La siguiente línea instalará huggingface-hub, este paquete Python es necesario si queremos utilizar cualquier modelo proporcionado por hugging-face
Ahora crearemos una variable de entorno para almacenar el token API de inferencia de Hugging Face como se muestra a continuación. Podemos obtener el token API de Inference iniciando sesión en el sitio web de Hugging Face y luego generando un token.
import os
os.environ("HUGGINGFACE_ACCESS_TOKEN") = "Hugging Face Inferenece API Token"La biblioteca embedchain utilizará el token proporcionado anteriormente para inferir los modelos de caras abrazadas. A continuación, debemos crear un archivo YAML definiendo el modelo que queremos utilizar de huggingface. Un archivo YAML puede considerarse como un simple almacén clave-valor donde definimos las configuraciones para nuestras aplicaciones LLM. Estas configuraciones pueden incluir qué modelo LLM vamos a usar o qué modelo de incrustación vamos a usar (para obtener más información sobre el archivo YAML, haga clic en aquí). A continuación se muestra un archivo YAML de ejemplo.
config = """
llm:
provider: huggingface
config:
model: 'google/flan-t5-xxl'
temperature: 0.7
max_tokens: 1000
top_p: 0.8
embedder:
provider: huggingface
config:
model: 'sentence-transformers/all-mpnet-base-v2'
"""
with open('huggingface_model.yaml', 'w') as file:
file.write(config)- Estamos creando un archivo YAML desde el propio Python y almacenándolo en el archivo llamado abrazandocara_modelo.yaml.
- En este archivo YAML, definimos los parámetros de nuestro modelo e incluso el modelo de incrustación que se utiliza.
- En lo anterior, hemos especificado el proveedor como huggingface y flan-t5 modelo con diferentes configuraciones/parámetros que incluyen el temperatura del modelo, el tokens_max(es decir, la longitud de salida), e incluso la arriba_p valor.
- Para el modelo de incrustación, estamos utilizando un modelo de incrustación popular de huggingface llamado todo-mpnet-base-v2que será responsable de crear vectores de incrustación para nuestro modelo.
Configuración YAML
A continuación, crearemos una aplicación con el archivo de configuración YAML anterior.
from embedchain import Pipeline as App
app = App.from_config(yaml_path="huggingface_model.yaml")- Aquí importamos el objeto Pipeline como una aplicación desde la cadena integrada. El objeto Pipeline es responsable de crear aplicaciones LLM con diferentes configuraciones como las que hemos definido anteriormente.
- La aplicación creará un LLM con los modelos especificados en el archivo YAML. A esto aplicaciónpodemos introducir datos de diferentes fuentes de datos y, en la misma aplicación, podemos llamar al método de consulta para consultar el LLM sobre los datos proporcionados.
- Ahora, agreguemos algunos datos.
app.add("https://en.wikipedia.org/wiki/Alphabet_Inc.")- El aplicación.add() El método tomará datos y los agregará al almacén de vectores.
- Embedchain se encarga de recopilar los datos de la página web, crearlos en fragmentos y luego crear las incrustaciones de los datos.
- Luego, los datos se almacenarán en una base de datos vectorial. La base de datos predeterminada utilizada en embedchain es chromadb.
- En este ejemplo, agregamos la página Wikipedia de Alphabet, la empresa matriz de Google, a la aplicación.
Consultemos nuestra aplicación según los datos cargados:
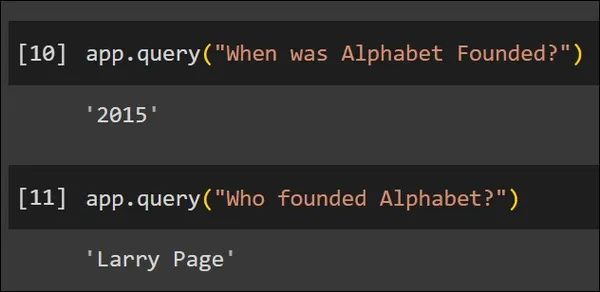
En la imagen de arriba, usando el consulta() método, le hemos pedido a nuestro Aplicación es decir, el modelo flan-t5 dos preguntas relacionadas con los datos que se agregaron al Aplicación. El modelo pudo responderlas correctamente. De esta manera, podemos agregar múltiples fuentes de datos al modelo pasándolas al agregar() método e internamente se procesarán y se crearán las incrustaciones para ellos, y finalmente se agregarán al almacén de vectores. Luego podemos consultar los datos con el consulta() método.
Configuración de una aplicación con un modelo y una tienda de vectores diferentes
En el ejemplo anterior, hemos visto cómo preparar una aplicación que agrega un sitio web como datos y el modelo Hugging Face como modelo de lenguaje grande subyacente para la aplicación. En esta sección, veremos cómo podemos usar otros modelos y otras bases de datos vectoriales para ver qué tan flexible puede ser la cadena integrada. Para este ejemplo, usaremos Zilliz Cloud como nuestra base de datos vectorial, por lo tanto, necesitamos descargar el cliente Python respectivo como se muestra a continuación:
!pip install --upgrade embedchain(milvus)
!pip install pytube- Lo anterior descargará el paquete Pymilvus Python con el que podremos interactuar con Zilliz Cloud.
- La biblioteca de pytube nos permitirá convertir vídeos de YouTube a texto para que puedan almacenarse en Vector Store.
- A continuación, podemos crear una cuenta gratuita con Zilliz Cloud. Después de crear la cuenta gratuita, vaya al panel de Zilliz Cloud y cree un clúster.
Después de crear el Clúster podemos obtener las credenciales para conectarnos a él como se muestra a continuación:
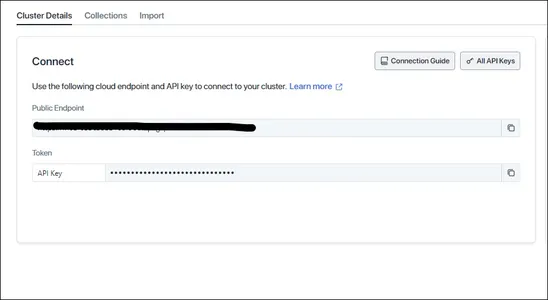
Clave API de OpenAI
Copie el punto final público y el token y guárdelos en otro lugar, ya que serán necesarios para conectarse a Zilliz Cloud Vector Store. Y ahora, para el modelo de lenguaje grande, esta vez usaremos el modelo OpenAI GPT. Por lo tanto, también necesitaremos la clave API de OpenAI para seguir adelante. Después de obtener todas las claves, cree las variables de entorno como se muestra a continuación:
os.environ("OPENAI_API_KEY")="Your OpenAI API Key"
os.environ("ZILLIZ_CLOUD_TOKEN")= "Your Zilliz Cloud Token"
os.environ("ZILLIZ_CLOUD_URI")= "Your Zilliz Cloud Public Endpoint"Lo anterior almacenará todas las credenciales requeridas en Zilliz Cloud y OpenAI como variables de entorno. Ahora es el momento de definir nuestra aplicación, lo cual se puede hacer de la siguiente manera:
from embedchain.vectordb.zilliz import ZillizVectorDB
app = App(db=ZillizVectorDB())
app.add("https://www.youtube.com/watch?v=ZnEgvGPMRXA")- Aquí primero importamos el ZillizVectorDB clase proporcionada por la cadena de inserción.
- Luego, al crear nuestra nueva aplicación, pasaremos el ZillizVectorDB() hacia base de datos variable dentro de la función App().
- Como no hemos especificado ningún LLM, el LLM predeterminado se elige como OpenAI GPT 3.5.
- Ahora nuestra aplicación está definida con OpenAI como LLM y Zilliz como Vector Store.
- A continuación, agregamos un video de YouTube a nuestra aplicación usando el agregar() método.
- Agregar un video de YouTube es tan simple como pasar la URL a agregar() función, toda la conversión de video a texto es abstraída por la cadena de inserción, lo que la hace simple.
Nube Zilliz
Ahora, el video primero se convierte en texto, luego se creará en fragmentos y el modelo de incrustación OpenAI lo convertirá en incrustaciones vectoriales. Estas incorporaciones luego se almacenarán dentro de Zilliz Cloud. Si vamos a Zilliz Cloud y revisamos dentro de nuestro clúster, podemos encontrar una nueva recopilación llamada “embedchain_store”, donde se almacenan todos los datos que agregamos a nuestra app:
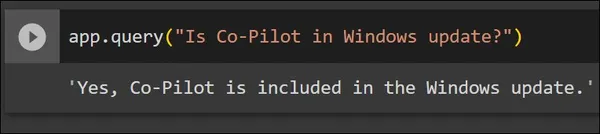
Como podemos ver, se creó una nueva colección bajo el nombre “embedchain_store”y esta colección contiene los datos que hemos agregado en el paso anterior. Ahora consultaremos nuestra aplicación.
El video que se agregó a la aplicación trata sobre la nueva actualización de Windows 11. En la imagen de arriba, le hacemos a la aplicación una pregunta que se mencionó en el video. Y la aplicación responde correctamente a la pregunta. En estos dos ejemplos, hemos visto cómo utilizar diferentes modelos de lenguaje grande y diferentes bases de datos con embedchain y también hemos subido datos de diferentes tipos, es decir, una página web y un vídeo de YouTube.
LLM y tiendas de vectores compatibles con Embedchain
Embedchain ha crecido mucho desde su lanzamiento al brindar soporte para una gran variedad de modelos de lenguajes grandes y bases de datos vectoriales. Los modelos de lenguaje grande admitidos se pueden ver a continuación:
- Modelos de cara abrazada
- AbiertoAI
- Azure abierto ai
- antrópico
- llama2
- Adherirse
- JinaChat
- IA de vértice
- GPT4Todos
Además de admitir una amplia gama de modelos de lenguaje grandes, la cadena integrada también brinda soporte a muchas bases de datos vectoriales que se pueden ver en la siguiente lista:
- cromadb
- Búsqueda elástica
- Abrir búsqueda
- Zilliz
- Piña
- Weaviate
- Cuadrante
- LanzaDB
Aparte de estos, en el futuro la cadena integrada agregará soporte para más modelos de lenguaje grandes y bases de datos vectoriales.
Conclusión
Al crear aplicaciones con grandes modelos de lenguaje, el principal desafío será el manejo de datos, es decir, datos provenientes de diferentes fuentes de datos. Eventualmente, todas las fuentes de datos deben convertirse a un solo tipo antes de convertirse en incrustaciones. Y cada fuente de datos tiene su propia forma de manejarlos, como si existieran bibliotecas separadas para manejar videos, otras para manejar sitios web, etc. Entonces, hemos analizado una solución para este desafío con el paquete Embedchain Python, que hace todo el trabajo pesado por nosotros, permitiéndonos integrar datos de cualquier fuente de datos sin preocuparnos por la conversión subyacente.
Conclusiones clave
Algunas de las conclusiones clave de este artículo incluyen:
- Embedchain admite un gran conjunto de modelos de lenguajes grandes, lo que nos permite trabajar con cualquiera de ellos.
- Además, Embedchain se integra con muchas tiendas Vector populares.
- Un simple agregar() El método se puede utilizar para almacenar datos de cualquier tipo en el almacén de vectores.
- Embedchain facilita el cambio entre LLM y Vector DB y proporciona métodos simples para agregar y consultar los datos.
Preguntas frecuentes
R. Embedchain es una herramienta de Python que permite a los usuarios agregar datos de cualquier tipo y almacenarlos en una tienda de vectores, lo que nos permite consultarlos con cualquier modelo de lenguaje grande.
R. Se puede proporcionar una base de datos vectorial de nuestra elección a la aplicación que estamos desarrollando a través del archivo config.yaml o directamente al aplicación() clase pasando la base de datos al “base de datos”parámetro dentro del aplicación() clase.
R. Sí, en el caso de utilizar bases de datos vectoriales locales como chromadb, cuando realizamos una agregar() método, los datos se convertirán en incrustaciones de vectores y luego se almacenarán en una base de datos de vectores como chromadb que se conservará localmente en la carpeta “base de datos”.
R. No, no lo es. Podemos configurar nuestra aplicación pasando directamente las configuraciones al aplicación() variables o en su lugar use un config.yaml para generar una aplicación a partir del archivo YAML. El archivo Config.yaml será útil para replicar los resultados cuando queramos compartir la configuración de nuestra aplicación con alguien más, pero no es obligatorio usar uno.
R. Embedchain admite datos provenientes de diferentes fuentes de datos que incluyen CSV, JSON, Notion, archivos mdx, docx, páginas web, videos de YouTube, archivos PDF y muchos más. Embedchain abstrae la forma en que maneja todas estas fuentes de datos, lo que nos facilita agregar cualquier dato.
Referencias
Para obtener más información sobre la cadena integrada y su arquitectura, consulte su página de documentación oficial y el repositorio de Github.
- https://docs.embedchain.ai
- https://github.com/embedchain/embedchain
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.






{kind=link}