
Introduction
In today’s data-driven world, machine learning is playing an increasingly prominent role in various industries. Explainable ai aims to make machine learning models more transparent to clients, patients, or loan applicants, helping build trust and social acceptance of these systems. Now, different models require different explanation methods, depending on the audience. This article discusses the importance and applications of Explainable ai (XAI) as well as the various approaches to demystify black box models.
Learning Objectives:
- Recognize the importance and applications of Explainable ai (XAI) in enhancing transparency and trust in machine learning.
- Differentiate between global and local approaches to XAI and understand their use cases.
- Explore key XAI techniques such as LIME, SHapley Additive Explanations, and counterfactual explanations for model transparency and interoperability.
<h2 class="wp-block-heading" id="h-what-is-explainable-ai“>What is Explainable ai?
The use of machine learning in decision-making is now an integral part of every industry, company, and organization. These decisions impact a wide range of stakeholders, including business owners, managers, end-users, domain experts, regulators, and data scientists. It is therefore vital that we understand how these models make decisions.
Regulators have become increasingly interested in machine learning, particularly in highly regulated sectors where decisions carry significant consequences. Transparency is crucial in fields like finance, healthcare, crime, and insurance, where it’s important to know how and why a particular decision was made.
Explainable ai aims to make machine learning models more transparent to all of these stakeholders. It also assists data scientists in understanding their work better. However, XAI is not always necessary, and we must use it wisely. In some scenarios, overly complex explanations may lead to distrust or confusion.
Types of Explainability
Explainable ai comes in various flavors, each catering to different use cases and stakeholders. We need different methods to explain ai models to business owners, managers, users, domain experts, regulators, and data scientists. Depending on the stakeholders’ needs, we might require different explanation methods. The rise of regulators in the ai field, proposing requirements and regulations, has made explainability even more crucial in strictly regulated industries like finance, healthcare, and criminal justice. Machine learning models in these areas must be able to provide transparency to clients, patients, or loan applicants.
Explainable ai encompasses various methods and techniques, categorized into several types:
- Ad-hoc/Intrinsic Methods: These methods restrict the complexity of the model before training. They involve selecting specific algorithms and limiting the number of features.
- Post-hoc Methods: These methods are applied after a model is trained. They are more versatile in explaining black-box models.
- Model-Specific vs. Model-Agnostic: Some methods are specific to certain types of black-box models, while others can be applied universally.
- Local vs. Global Methods: Local methods provide explanations for individual instances or data points, while global methods offer insights into overall model behavior across the dataset.
<h2 class="wp-block-heading" id="h-importance-of-explainable-ai“>Importance of Explainable ai
Explainable ai is crucial for building trust and acceptance of machine learning models. It helps end-users understand why a particular decision was made. It also fosters transparency, detects biases, improves robustness and reliability, aids data scientists in understanding their models, and helps in gaining trust in machine learning systems.
However, explainability is not always necessary and can sometimes lead to distrust, especially when complex and opaque processes are uncovered. It’s essential to choose the right level of explainability for the context.
Challenges and Considerations in Explainability
Explainable ai comes with its set of challenges. One of the major challenges is the need to balance between accuracy and transparency. Sometimes, achieving high accuracy with complete transparency is not feasible. Additionally, selecting the right explanation method for a specific model can be challenging. It’s crucial to avoid revealing sensitive information or creating explanations that can be exploited.
<h2 class="wp-block-heading" id="h-model-development-in-explainable-ai“>Model Development in Explainable ai
The quest for explainability often involves striking a balance between model accuracy and transparency. While models like decision trees are intrinsically explainable, they might sacrifice accuracy. On the other hand, highly accurate models, like deep neural networks, often lack transparency. Explainable ai aims to offer reasonably high accuracy while providing interpretability. It fills the gap between accuracy and transparency in a machine learning model.
Different Approaches to Explainability
Explainable ai can be approached in various forms. The approach taken influences the type of inferences gained and how the insights are explained. Therefore, the approach depends on the scale of the project and the use case. We will now look into some of these approaches such as global, local, counterfactual explanations, visualization, etc.
Global Approaches
Explainable ai can be approached from a global perspective. Global explanations focus on providing insights into the overall behavior of a model for an entire dataset. The important aspect here is to understand the general behavior of the model across different input instances. Decision trees and linear models often fall under this category, offering a high-level explanation of how features influence predictions.
Local Approaches
In contrast to global approaches, local explainability focuses on individual instances or data points. Local explanations aim to provide insight into why a specific prediction was made for a particular input. They offer a more detailed, case-specific view of model decisions. Techniques like LIME (Local Interpretable Model-agnostic Explanations) fall under this category, enabling us to understand why a model made a specific prediction for a particular input.
Counterfactual Explanations
Now, let’s explore the world of counterfactual explanations. Counterfactual explanations are all about understanding how changes and adjustments in input features can lead to different model outputs. It’s like asking, “What if I had different values for these features?”
Consider a scenario where someone’s loan application is rejected, and they want to know how to change their circumstances to get approval. Counterfactual explanations provide actionable insights. They show how altering specific features can lead to a desired outcome. This approach is incredibly valuable in decision-making processes and can help individuals understand how to achieve their goals.
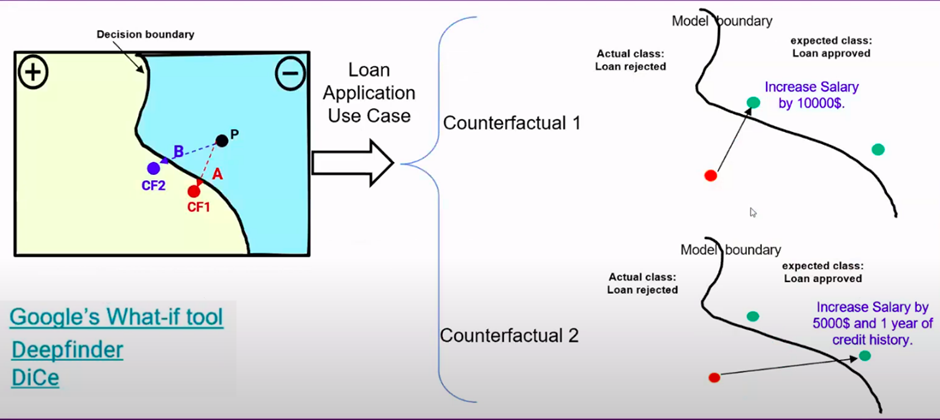
However, the challenge with counterfactual explanations is that there can be multiple valid counterfactuals for a single instance. Selecting the most appropriate one can be tricky. Overall, counterfactual explanations provide a unique perspective on interpretability, helping us understand how changes in input features can impact the model’s predictions.
Visualization Approaches
Visualization is an effective way to provide explanations in Explainable ai. Two common visualization methods are Partial Dependence Plots (PDPs) and Individual Conditional Expectation (ICE) Plots.
Partial Dependence Plots
PDPs provide a visual representation of how one or two features affect the model’s predictions. They show the average marginal effect of a feature on the target variable. PDPs are easy to comprehend, making them ideal for explaining machine learning models to various stakeholders.
Individual Conditional Expectation Plots
Individual Conditional Expectation (ICE) plots offer a more detailed view of how feature variations affect individual instances. They uncover heterogeneous effects that are often missed by PDPs. ICE plots provide a distribution of model predictions for each instance, offering a nuanced understanding of a model’s behavior.
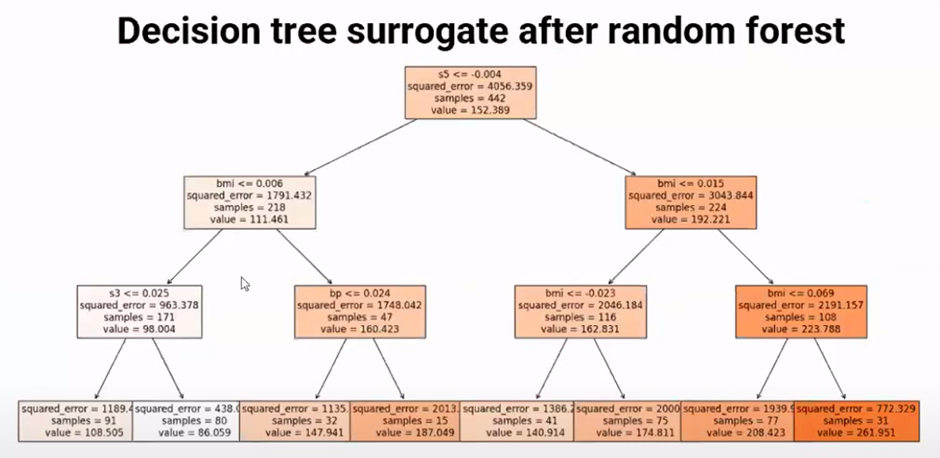
Global Surrogate Models
Global surrogate models provide an alternate approach to understanding complex black-box models. These models are built on top of the predictions made by black-box models. They offer a more interpretable and understandable representation of the model’s behavior. Decision trees are commonly used as surrogate models to explain the predictions of black-box models.
Feature Importance Analysis
Feature importance analysis is a critical part of Explainable ai, providing insights into which features have the most significant impact on model predictions. Permutation-based feature importance analysis is a technique to assess the importance of each feature. It measures the increase in a model’s prediction error when a specific feature is randomly shuffled. This allows us to understand the role of each feature in the model’s decision-making process.
Contrastive Explanation and Pertinent Negatives
Finally, we have a contrastive explanation, which offers a unique approach to model interpretability. It focuses on explaining decisions by highlighting what features are missing. Pertinent Negatives, a subset of contrastive explanations, help us understand the importance of absent features in classification.
Think of it this way: if someone has the symptoms of cough, cold, and fever but no sputum and chills, it could be pneumonia or the flu. But when sputum and chills are absent, it’s almost certainly the flu. Pertinent Negatives help us make more accurate diagnoses by considering the importance of missing features.
These explanations are particularly valuable when you want to understand the impact of the absence of certain features on model predictions. They provide a different perspective on interpretability and can help uncover the hidden factors that influence decisions.
<h2 class="wp-block-heading" id="h-advanced-approaches-to-explainable-ai“>Advanced Approaches to Explainable ai
By now, you’ve probably gained a good understanding of the various ways to approach explainable ai. Now, apart from those mentioned above, there are a few more advanced approaches, specific to certain tasks. Let’s have a look at some of them.
LIME: Demystifying Local Explanations
Local Interpretable Model-Agnostic Explanations (LIME) is a local approach that provides model-agnostic explanations for individual predictions. What makes it stand out is its ability to work with a wide range of data types, including tabular, text, and images, and it can handle both classification and regression tasks.

So, how does LIME work? Imagine you have a complex, “black box” model, and you want to understand why it made a specific prediction for a particular instance. LIME takes the instance you’re interested in, perturbs the data around it by generating new data points, and observes the predictions made by your model for these new samples. This process helps LIME approximate how the model behaves locally around the instance of interest.
Next, LIME creates an interpretable model using the new data. But here’s the twist: the interpretable model gives more weight to the data points that are closer to the instance you’re explaining. This means that the data points generated nearby are considered more heavily when building the interpretable model.
The result is a local explanation for the prediction of your “black box” model. This explanation is not only human-friendly but also model-agnostic, meaning it can be applied to any machine learning model. However, LIME does have its challenges. The definition of the neighborhood around an instance is not always clear, and the manual selection of features can be tricky. The sampling process can also be improved to make LIME even more effective.
SHapley Additive Explanations: The Power of Collaboration
Now, let’s dive into SHapley Additive Explanations. This approach is rooted in cooperative game theory. It is all about calculating the individual contribution or utility of features in a team, just like how game theory calculates the importance of each player in a cooperative game.
Consider a team of four people who won a prize in a chess game. They want to fairly distribute the prize among them based on their contributions. To calculate this, they explore various combinations of the players and estimate the utility for each player in every combination. This helps determine how much each player contributed to the overall success.
SHapley Additive Explanations apply the same principle to machine learning models. Instead of players, we have features, and instead of the prize, we have predictions. This approach calculates the marginal value of each feature on a specific instance and compares it to the average prediction across the dataset.
The beauty of SHapley values is that they provide an instance-based approach and work for both classification and regression problems. Whether you’re dealing with tabular, text, or image data, SHapley Additive Explanations can help you understand the importance of different features. However, one drawback is that it can be computationally intensive due to the vast number of combinations it explores. To mitigate this, you can use sampling on a subset of the data to speed up the process.
Layer-wise Relevance Propagation: Peeling Back the Layers
Layer-wise Relevance Propagation, or LRP, is a technique primarily used for image data. It helps us understand which pixels in an image have the most influence on a model’s classification decision. LRP operates by computing the relevance of each layer and neuron in a neural network. This process reveals the most influential pixels and helps us visualize what the model “sees” in an image.
Let’s consider a neural network that classifies images. LRP starts from the model’s output and works its way backward. It estimates the relevance of each neuron and layer in the network, checking the contribution of each neuron to the final classification. The result is a heatmap that highlights the pixels that had the most influence on the model’s decision.
One challenge with LRP-generated heatmaps is that they can be noisy and similar, making it difficult to pinpoint the exact influential pixels. However, LRP is a valuable tool for understanding how neural networks make image classification decisions.
Conclusion
Explainable ai (XAI) is a vital component in the realm of artificial intelligence and machine learning. It clarifies the intricate inner workings of ai models, ensuring transparency and trust. We explored various facets of XAI, from its importance to specific techniques like LIME, SHapley Additive Explanations, counterfactual explanations, LRP, and contrastive explanations. These methods empower users to understand, question, and fine-tune machine learning models for different contexts.
Key Takeaways:
- Explainable ai offers diverse methods, such as global and local approaches, counterfactual explanations, and feature importance analysis, catering to various stakeholders and industries.
- XAI enhances trust in machine learning systems through transparency, bias detection, and reliability improvement. Striking the right transparency-complexity balance is essential.
- Techniques like LIME, SHapley Additive Explanations, LRP, and contrastive explanations provide insights into model behavior and foster interpretability, aiding ai system comprehension.
Frequently Asked Questions
Ans. Explainable ai fosters trust, detects biases, and enhances transparency in machine learning systems, promoting their acceptance and reliability.
Ans. Global approaches provide insights into an entire dataset, while local approaches focus on individual instances, offering case-specific explanations.
Ans. LIME perturbs data around an instance, creates an interpretable model, and provides local, model-agnostic explanations. SHapley Additive Explanations calculate feature importance based on cooperative game theory, aiding interpretability for both classification and regression problems.
About the Author: Dr. Farha Anjum Khan
Dr. Farha Anjum Khan is a seasoned data scientist and Lead Technical Architect at Continental. Dr. Khan has an extensive six-year career in data science. Her journey began with academic pursuits in experimental nuclear and particle physics, where she gained invaluable experience at prestigious institutions in Germany. Her passion for data, algorithms, and artificial intelligence led her to bridge the gap between technology and responsible ai, making her an expert in XAI.
DataHour Page: ai-demystifying-the-black-box-models” target=”_blank” rel=”noopener”>https://community.analyticsvidhya.com/c/datahour/explainable-ai-demystifying-the-black-box-models
LinkedIn: https://www.linkedin.com/in/dr-farha-anjum-khan-617b0813/






{kind=link}