
Esta es la Parte 3 de nuestra serie donde diseñamos e implementamos una tubería MLOps para la inspección visual de calidad en el borde. En esta publicación, nos centramos en cómo automatizar la parte de implementación perimetral del proceso MLOps de un extremo a otro. Le mostramos cómo utilizar AWS IoT Greengrass para gestionar la inferencia de modelos en el borde y cómo automatizar el proceso utilizando AWS Step Functions y otros servicios de AWS.
Descripción general de la solución
En la Parte 1 de esta serie, presentamos una arquitectura para nuestro canal MLOps de extremo a extremo que automatiza todo el proceso de aprendizaje automático (ML), desde el etiquetado de datos hasta el entrenamiento de modelos y la implementación en el borde. En la Parte 2, mostramos cómo automatizar las partes del proceso de etiquetado y entrenamiento de modelos.
El caso de uso de muestra utilizado para esta serie es una solución de inspección visual de calidad que puede detectar defectos en etiquetas metálicas, que puede implementar como parte de un proceso de fabricación. El siguiente diagrama muestra la arquitectura de alto nivel de la canalización MLOps que definimos al comienzo de esta serie. Si aún no lo has leído, te recomendamos consultar la Parte 1.
Automatizar la implementación perimetral de un modelo de aprendizaje automático
Una vez entrenado y evaluado un modelo de ML, es necesario implementarlo en un sistema de producción para generar valor comercial mediante la realización de predicciones sobre los datos entrantes. Este proceso puede volverse complejo rápidamente en una configuración de borde donde los modelos deben implementarse y ejecutarse en dispositivos que a menudo están ubicados lejos del entorno de nube en el que se han entrenado los modelos. Los siguientes son algunos de los desafíos exclusivos del aprendizaje automático en el borde:
- Los modelos de aprendizaje automático a menudo necesitan optimizarse debido a limitaciones de recursos en los dispositivos perimetrales.
- Los dispositivos perimetrales no se pueden volver a implementar ni reemplazar como un servidor en la nube, por lo que necesita un proceso sólido de implementación de modelos y administración de dispositivos.
- La comunicación entre los dispositivos y la nube debe ser eficiente y segura porque a menudo atraviesa redes de bajo ancho de banda que no son confiables.
Veamos cómo podemos abordar estos desafíos con los servicios de AWS además de exportar el modelo en formato ONNX, lo que nos permite, por ejemplo, aplicar optimizaciones como la cuantificación para reducir el tamaño del modelo para dispositivos con restricciones. ONNX también proporciona tiempos de ejecución optimizados para las plataformas de hardware perimetrales más comunes.
Para dividir el proceso de implementación perimetral, necesitamos dos componentes:
- Un mecanismo de implementación para la entrega del modelo, que incluye el modelo en sí y cierta lógica de negocios para administrar e interactuar con el modelo.
- Un motor de flujo de trabajo que puede orquestar todo el proceso para hacerlo sólido y repetible.
En este ejemplo, utilizamos diferentes servicios de AWS para crear nuestro mecanismo de implementación de borde automatizado, que integra todos los componentes necesarios que analizamos.
En primer lugar, simulamos un dispositivo de borde. Para que le resulte sencillo seguir el flujo de trabajo de un extremo a otro, utilizamos una instancia de Amazon Elastic Compute Cloud (Amazon EC2) para simular un dispositivo perimetral instalando el software AWS IoT Greengrass Core en la instancia. También puede utilizar instancias EC2 para validar los diferentes componentes en un proceso de control de calidad antes de implementarlos en un dispositivo de producción perimetral real. AWS IoT Greengrass es un servicio de nube y tiempo de ejecución perimetral de código abierto de Internet de las cosas (IoT) que le ayuda a crear, implementar y administrar software de dispositivos perimetrales. AWS IoT Greengrass reduce el esfuerzo para crear, implementar y administrar software de dispositivos perimetrales de forma segura y escalable. Después de instalar el software AWS IoT Greengrass Core en su dispositivo, puede agregar o eliminar características y componentes, y administrar las aplicaciones de su dispositivo IoT mediante AWS IoT Greengrass. Ofrece una gran cantidad de componentes integrados para hacerle la vida más fácil, como los componentes StreamManager y MQTT Broker, que puede utilizar para comunicarse de forma segura con la nube y admitir el cifrado de extremo a extremo. Puede utilizar esas funciones para cargar resultados de inferencia e imágenes de manera eficiente.
En un entorno de producción, normalmente tendría una cámara industrial que entrega imágenes para las cuales el modelo ML debería producir predicciones. Para nuestra configuración, simulamos esta entrada de imagen cargando un ajuste preestablecido de imágenes en un directorio específico en el dispositivo perimetral. Luego usamos estas imágenes como entrada de inferencia para el modelo.
Dividimos el proceso general de implementación e inferencia en tres pasos consecutivos para implementar un modelo de aprendizaje automático entrenado en la nube en un entorno de borde y usarlo para predicciones:
- Preparar – Empaquetar el modelo entrenado para la implementación perimetral.
- Desplegar – Transferencia de componentes de modelo e inferencia desde la nube al dispositivo perimetral.
- Inferencia – Cargue el modelo y ejecute código de inferencia para predicciones de imágenes.
El siguiente diagrama de arquitectura muestra los detalles de este proceso de tres pasos y cómo lo implementamos con los servicios de AWS.
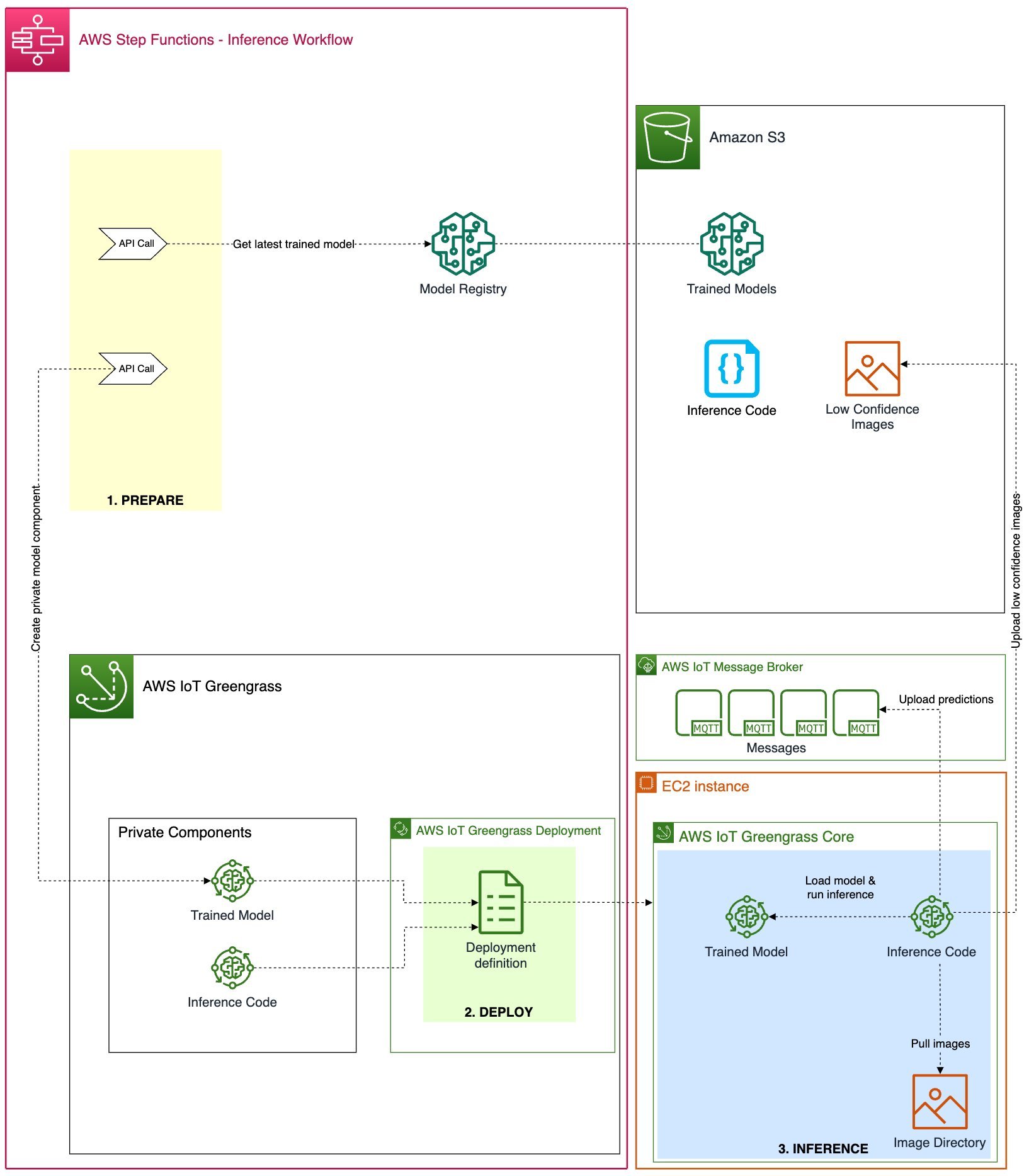
En las siguientes secciones, analizamos los detalles de cada paso y mostramos cómo integrar este proceso en una orquestación automatizada y repetible y un flujo de trabajo de CI/CD tanto para los modelos de ML como para el código de inferencia correspondiente.
Preparar
Los dispositivos perimetrales a menudo vienen con computación y memoria limitadas en comparación con un entorno de nube donde CPU y GPU potentes pueden ejecutar modelos de aprendizaje automático fácilmente. Diferentes técnicas de optimización de modelos le permiten adaptar un modelo a una plataforma de software o hardware específica para aumentar la velocidad de predicción sin perder precisión.
En este ejemplo, exportamos el modelo entrenado en el proceso de capacitación al formato ONNX para portabilidad, posibles optimizaciones, así como tiempos de ejecución de borde optimizados, y registramos el modelo en el Registro de modelos de Amazon SageMaker. En este paso, creamos un nuevo componente del modelo de Greengrass que incluye el último modelo registrado para su posterior implementación.
Desplegar
Un mecanismo de implementación seguro y confiable es clave al implementar un modelo desde la nube a un dispositivo perimetral. Debido a que AWS IoT Greengrass ya incorpora un sistema de implementación de borde sólido y seguro, lo utilizamos para nuestros fines de implementación. Antes de analizar nuestro proceso de implementación en detalle, hagamos un resumen rápido de cómo funcionan las implementaciones de AWS IoT Greengrass. En el núcleo del sistema de implementación de AWS IoT Greengrass se encuentran los componentes, que definen los módulos de software implementados en un dispositivo perimetral que ejecuta AWS IoT Greengrass Core. Estos pueden ser componentes privados que usted cree o componentes públicos proporcionados por AWS o la comunidad de Greengrass en general. Se pueden agrupar varios componentes como parte de una implementación. Una configuración de implementación define los componentes incluidos en una implementación y los dispositivos de destino de la implementación. Se puede definir en un archivo de configuración de implementación (JSON) o mediante la consola de AWS IoT Greengrass al crear una nueva implementación.
Creamos los siguientes dos componentes de Greengrass, que luego se implementan en el dispositivo perimetral mediante el proceso de implementación:
- Modelo empaquetado (componente privado) – Este componente contiene el modelo entrenado y ML en formato ONNX.
- Código de inferencia (componente privado) – Aparte del modelo ML en sí, necesitamos implementar cierta lógica de aplicación para manejar tareas como la preparación de datos, la comunicación con el modelo para la inferencia y el posprocesamiento de los resultados de la inferencia. En nuestro ejemplo, hemos desarrollado un componente privado basado en Python para manejar las siguientes tareas:
- Instale los componentes de tiempo de ejecución necesarios, como el paquete Ultralytics YOLOv8 Python.
- En lugar de tomar imágenes de la transmisión en vivo de una cámara, simulamos esto cargando imágenes preparadas desde un directorio específico y preparando los datos de la imagen de acuerdo con los requisitos de entrada del modelo.
- Realice llamadas de inferencia contra el modelo cargado con los datos de la imagen preparada.
- Verifique las predicciones y cargue los resultados de las inferencias en la nube.
Si desea tener una visión más profunda del código de inferencia que creamos, consulte el repositorio de GitHub.
Inferencia
El proceso de inferencia del modelo en el dispositivo perimetral comienza automáticamente una vez finalizada la implementación de los componentes antes mencionados. El componente de inferencia personalizado ejecuta periódicamente el modelo ML con imágenes de un directorio local. El resultado de la inferencia por imagen devuelta por el modelo es un tensor con el siguiente contenido:
- Puntuaciones de confianza – Qué tan seguro tiene el modelo con respecto a las detecciones
- Coordenadas del objeto – Las coordenadas del objeto borrador (x, y, ancho, alto) detectadas por el modelo en la imagen.
En nuestro caso, el componente de inferencia se encarga de enviar los resultados de la inferencia a un tema MQTT específico en AWS IoT donde se pueden leer para su posterior procesamiento. Estos mensajes se pueden ver a través del cliente de prueba MQTT en la consola de AWS IoT para su depuración. En un entorno de producción, puede decidir notificar automáticamente a otro sistema que se encarga de eliminar las etiquetas metálicas defectuosas de la línea de producción.
Orquestación
Como se vio en las secciones anteriores, se requieren varios pasos para preparar e implementar un modelo de aprendizaje automático, el código de inferencia correspondiente y el tiempo de ejecución o agente requerido en un dispositivo perimetral. Step Functions es un servicio totalmente administrado que le permite organizar estos pasos dedicados y diseñar el flujo de trabajo en forma de máquina de estados. La naturaleza sin servidor de este servicio y las capacidades nativas de Step Functions, como las integraciones de API de servicios de AWS, le permiten configurar rápidamente este flujo de trabajo. Las capacidades integradas, como los reintentos o el registro, son puntos importantes para crear orquestaciones sólidas. Para obtener más detalles sobre la definición de la máquina de estados en sí, consulte la repositorio de GitHub o consulte el gráfico de la máquina de estado en la consola de Step Functions después de implementar este ejemplo en su cuenta.
Implementación de infraestructura e integración en CI/CD
El proceso de CI/CD para integrar y construir todos los componentes de infraestructura necesarios sigue el mismo patrón ilustrado en Parte 1 de esta serie. Utilizamos el kit de desarrollo de la nube de AWS (AWS CDK) para implementar las canalizaciones necesarias desde AWS CodePipeline.

Aprendizajes
Hay varias formas de crear una arquitectura para un sistema de implementación perimetral del modelo de aprendizaje automático automatizado, sólido y seguro, que a menudo dependen en gran medida del caso de uso y otros requisitos. Sin embargo, aquí hay algunos aprendizajes que nos gustaría compartir con usted:
- Evalúe de antemano si los requisitos adicionales de recursos informáticos de AWS IoT Greengrass se ajustan a su caso, especialmente con dispositivos de borde restringidos.
- Establezca un mecanismo de implementación que integre un paso de verificación de los artefactos implementados antes de ejecutarlos en el dispositivo perimetral para garantizar que no se produzca ninguna manipulación durante la transmisión.
- Es una buena práctica mantener los componentes de implementación en AWS IoT Greengrass lo más modulares y autónomos posible para poder implementarlos de forma independiente. Por ejemplo, si tiene un módulo de código de inferencia relativamente pequeño pero un modelo de aprendizaje automático grande en términos de tamaño, no siempre querrá implementar ambos si solo el código de inferencia ha cambiado. Esto es especialmente importante cuando tiene un ancho de banda limitado o una conectividad de dispositivo perimetral de alto costo.
Conclusión
Con esto concluye nuestra serie de tres partes sobre la construcción de un canal MLOps de extremo a extremo para la inspección visual de calidad en el borde. Analizamos los desafíos adicionales que conlleva la implementación de un modelo de aprendizaje automático en el borde, como el empaquetado de modelos o la orquestación de implementación compleja. Implementamos el proceso de forma totalmente automatizada para poder poner nuestros modelos en producción de forma sólida, segura, repetible y rastreable. No dude en utilizar la arquitectura y la implementación desarrolladas en esta serie como punto de partida para su próximo proyecto habilitado para ML. Si tiene alguna pregunta sobre cómo diseñar y construir un sistema de este tipo para su entorno, comuníquese con nosotros. Para otros temas y casos de uso, consulte nuestros blogs sobre aprendizaje automático e IoT.
Sobre los autores
 Michael Roth es un arquitecto de soluciones senior en AWS que brinda soporte a los clientes de fabricación en Alemania para resolver sus desafíos comerciales a través de la tecnología de AWS. Además del trabajo y la familia, le interesan los coches deportivos y le gusta el café italiano.
Michael Roth es un arquitecto de soluciones senior en AWS que brinda soporte a los clientes de fabricación en Alemania para resolver sus desafíos comerciales a través de la tecnología de AWS. Además del trabajo y la familia, le interesan los coches deportivos y le gusta el café italiano.
 Jörg Wöhrle es arquitecto de soluciones en AWS y trabaja con clientes de fabricación en Alemania. Apasionado por la automatización, Joerg trabajó como desarrollador de software, ingeniero de DevOps e ingeniero de confiabilidad del sitio en su vida anterior a AWS. Más allá de las nubes, es un corredor ambicioso y disfruta de tiempo de calidad con su familia. Entonces, si tienes un desafío de DevOps o quieres salir a correr: díselo.
Jörg Wöhrle es arquitecto de soluciones en AWS y trabaja con clientes de fabricación en Alemania. Apasionado por la automatización, Joerg trabajó como desarrollador de software, ingeniero de DevOps e ingeniero de confiabilidad del sitio en su vida anterior a AWS. Más allá de las nubes, es un corredor ambicioso y disfruta de tiempo de calidad con su familia. Entonces, si tienes un desafío de DevOps o quieres salir a correr: díselo.
 Johannes Langer es arquitecto senior de soluciones en AWS y trabaja con clientes empresariales en Alemania. A Johannes le apasiona aplicar el aprendizaje automático para resolver problemas empresariales reales. En su vida personal, a Johannes le gusta trabajar en proyectos de mejoras para el hogar y pasar tiempo al aire libre con su familia.
Johannes Langer es arquitecto senior de soluciones en AWS y trabaja con clientes empresariales en Alemania. A Johannes le apasiona aplicar el aprendizaje automático para resolver problemas empresariales reales. En su vida personal, a Johannes le gusta trabajar en proyectos de mejoras para el hogar y pasar tiempo al aire libre con su familia.






{kind=link}