
Introduction
I’m pretty sure most of you have already used ChatGPT. It’s great because you’ve taken the first step on a journey we’re about to embark on in this article! You see, when it comes to mastering any new technology, the first thing you need to do is use it. It’s like learning to swim by jumping into the water!
If you want to explore GenAI, pick a real-world problem and start building an app to solve it. At the heart of everything GenAI is a large language model (LLM), which some people call the fundamental model (FM).
You may have heard from consumers, tuners and model manufacturers. But wait, we’re about to break it down even more.
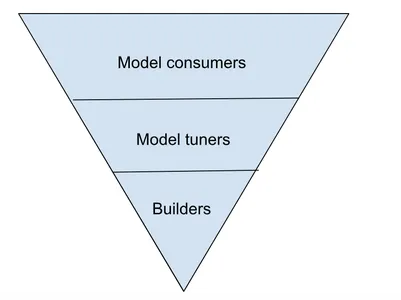
McKinsey sees it as takers, shapers, and makers that they mentioned in their GenAI Recognize session.

We’ll take a closer look at each of these layers in this article.
The proliferation of platforms as a use case
To delve even deeper into this, we will turn to a real-life example that will make everything very clear. In today’s technology landscape, it is a fact that most applications need to run on multiple platforms. However, here’s the catch: each platform has its unique interface and quirks. Expanding an application’s support for additional platforms and maintaining those applications cross-platform is equally challenging.
But that’s where GenAI comes in to save the day. It allows us to create a unified, easy-to-use interface for our applications, regardless of the platforms they serve. The magic ingredient? Large Language Models (LLM) transform this interface into a natural, intuitive language.
Linux, Windows and Mac commands
To make it more specific for even better understanding, let’s say we want to know what exact command to run for different scenarios on our machine, which can be Linux, Windows or Mac. The following diagram illustrates a scenario:
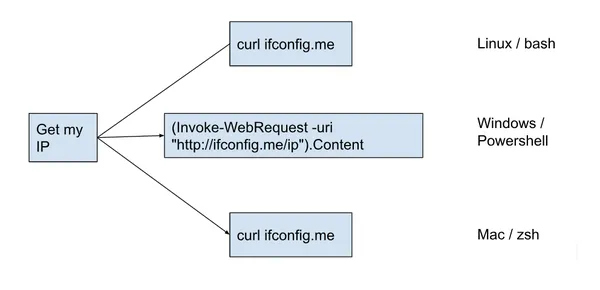
Value for the end user and application developer
As an end user, you don’t need to learn/know the commands for each of these platforms and you can do your things naturally and intuitively. As the application developer, you do not need to explicitly translate each of the application’s user-facing interfaces to each of the underlying supported platforms.
Reference architecture
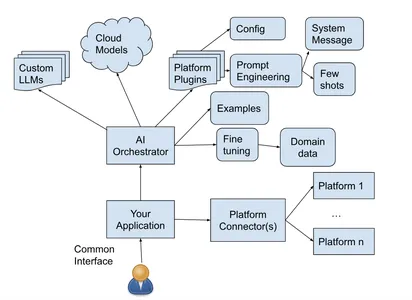
Several LLMs, including GPT3, GPT3.5, and GPT4, reside in the cloud, courtesy of various providers such as Open ai and Azure Open ai. They are easily accessible via various APIs such as completion, chat completion, etc.
ai orchestrators make this access even more seamless and consistent across models and providers. That’s why GenAI applications today often interact with ai orchestrators rather than interacting directly with the underlying providers and models. It then handles orchestration with configurable and/or possibly multiple providers and underlying models as required by the application.
You can have a plugin for each of the platforms your application wants to support for flexibility and modularity. We’ll delve into all the things we can do with these plugins and orchestrators in the following sections.
Finally, the application has connector(s) to interact with the platforms you want to support to execute the commands generated by GenAI.
Reference technologies
Setting
There are numerous in the settings themselves that you can adjust to achieve the desired results. Here is a typical config.json of a semantic kernel plugin:
{
"schema": 1,
"description": "My Application",
"type": "completion",
"completion": {
"max_tokens": 300,
"temperature": 0.0,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"stop_sequences": (
"++++++"
)
},
"input": {
"parameters": (
{
"name": "input",
"description": "Command Execution Scenario",
"defaultValue": ""
}
)
}
}The ‘type’ specifies the type of API you want to run on the underlying LLM. Here we are using the “completion” API. The “temperature” determines the variability or creativity of the model. For example, while chatting, you may want the ai to respond with different phrases at different times, even though they can all convey the same intention of keeping the conversation interesting. However, here we always want the same precise answer. Therefore, we are using the value of 0. Your result can consist of different sections with some predefined separators if you want only the first section, like the exact match command in our case, to be generated as a response that you use. “stop_sequences” like here. You define your input with all the parameters, only one in this case.
Quick engineering
Now let’s delve into the much talked about rapid engineering and how we can take advantage of it.
System messages
System messages tell the model exactly how we want it to behave. For example, the Linux bash plugin in our case might have something like the following at the beginning of its skprompt.txt.
You are a useful wizard that generates commands for Linux bash machines based on user input. Your response should contain ONLY the command and NO explanation. For all user input, it will only generate a response by considering Linux bash commands to find its solution.
Which specifies your system message.
Some shots, instructions and examples
It helps the model give the exact answer by giving it some sample questions and the corresponding answers it is looking for. It is also called incitement of some shots. For example, our Linux bash plugin might have something like the following in its skprompt.txt after the system prompt mentioned above:
Examples
User: Get my IP
Assistant: curl ifconfig.me
++++++
User: Get the weather in San Francisco
Assistant: curl wttr.in/SanFrancisco
++++++
User:"{{$input}}"
Assistant:You may want to fine-tune your system to choose the right examples/shots that get the desired result.
<h2 class="wp-block-heading" id="h-ai-orchestration”>ai Orchestration
We’ll put this configuration together and request engineering in our simple example and see how we can manage the ai orchestration in the semantic core.
import openai
import os
import argparse
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import AzureTextCompletion
parser = argparse.ArgumentParser(description='GANC')
parser.add_argument('platform', type=str,
help='A platform needs to be specified')
parser.add_argument('--verbose', action='store_true',
help='is verbose')
args = parser.parse_args()
kernel = sk.Kernel()
deployment, api_key, endpoint = sk.azure_openai_settings_from_dot_env()
kernel.add_text_completion_service("dv", AzureTextCompletion(deployment, endpoint, api_key))
platformFunctions = kernel.import_semantic_skill_from_directory("./", "platform_commands")
platformFunction = platformFunctions(args.platform)
user_query = input()
response = platformFunction(user_query)
print (respone)This Python script takes “platform” as a required argument. Select the correct plugin from the ‘platform_commands’ folder for the specified platform. It then takes the user’s query, invokes the function, and returns the response.
For your first use cases, you may want to experiment only this far, since LLMs already have a lot of intelligence. This simple setup and quick engineering alone can deliver results very close to the desired behavior, very quickly.
The following techniques are quite advanced at this point, require more effort and knowledge, and should be employed with return on investment in mind. The technology is still evolving and maturing in this space. At this time we will only take a cursory glance at them to check their integrity and our awareness of what awaits us.
Fine tuning
Tuning involves updating the weights of a previously trained language model on a new task and data set. Typically used for transfer learning, personalization, and domain specialization. There are several tools and techniques available for this. One way to do this is to use OpenAI’s CLI tools. You can give it your data and generate training data to make adjustments with commands like:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>You can then create a custom model using Azure ai Studio:

Provide the adjustment data you prepared earlier.
Custom LLMs
If you are brave enough to dig deeper and experiment, read on! We will see how to build our custom models.
Retraining
This is very similar to the adjustment we saw before. This is how we can do it using transformers:
from transformers import AutoTokenizer
# Prepare your data
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples("text"), padding="max_length", truncation=True)
# let's say my dataset is loaded into my_dataset
tokenized_datasets = my_dataset.map(tokenize_function, batched=True)
# load your model
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
# Train
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(output_dir="mydir")
trainer.train()
# save your model which can be loaded by pointing to the saved directory and used later
trainer.save_model()Training from scratch
Here you can start with some known model structures and train them from scratch. It will take a lot of time, resources and training data, although the model created is completely under your control.
New models
You can define the structure of your model, potentially improving existing models, and then follow the process above. Amazon’s Titan and Codewhisperer fall into this category.
Conclusion
GenAI has immense potential for various use cases. This article exemplified its application in cross-platform support and rapid solution creation. While skepticism surrounds GenAI, the path to harnessing its power is clear. However, the journey becomes complex when you delve deeper into model tuning and training.
Key takeaways:
- As you can see, GenAI is very fascinating and enables various use cases.
- We looked at one such use case and looked at how we could quickly start building a solution.
- Some wonder if GenAI is a bubble. You can choose your favorite use case and try it yourself by following the steps set out in this article to answer it yourself!
- The process can become complex and laborious very quickly as you begin to delve into territories such as tuning, training, and model building.
Frequent questions
A. I don’t think so. You can choose your favorite use case and try it yourself by following the steps set out in this article to answer it yourself!
A. There are end users, model consumers, model tuners and model builders.
The media shown in this article is not the property of Analytics Vidhya and is used at the author’s discretion.





