
En la Parte 1 de esta serie, redactamos una arquitectura para una canalización MLOps de extremo a extremo para un caso de uso de inspección visual de calidad en el borde. Su arquitectura está diseñada para automatizar todo el proceso de aprendizaje automático (ML), desde el etiquetado de datos hasta el entrenamiento de modelos y la implementación en el borde. El enfoque en servicios administrados y sin servidor reduce la necesidad de operar la infraestructura para su canalización y le permite comenzar rápidamente.
En esta publicación, profundizamos en cómo se implementan las partes del proceso de etiquetado, construcción de modelos y capacitación. Si está particularmente interesado en el aspecto de implementación perimetral de la arquitectura, puede pasar a la Parte 3. También proporcionamos un documento adjunto repositorio de GitHub si desea implementarlo y pruébelo usted mismo.
Descripción general de la solución
El caso de uso de muestra utilizado para esta serie es una solución de inspección visual de calidad que puede detectar defectos en etiquetas metálicas, que podrían implementarse como parte de un proceso de fabricación. El siguiente diagrama muestra la arquitectura de alto nivel de la canalización MLOps que definimos al comienzo de esta serie. Si aún no lo has leído, te recomendamos echarle un vistazo. Parte 1.
Automatizar el etiquetado de datos
El etiquetado de datos es una tarea intrínsecamente laboriosa que involucra a humanos (etiquetadores) para etiquetar los datos. Etiquetar para nuestro caso de uso significa inspeccionar una imagen y dibujar cuadros delimitadores para cada defecto visible. Esto puede parecer sencillo, pero debemos ocuparnos de una serie de cosas para poder automatizarlo:
- Proporcionar una herramienta para que los etiquetadores dibujen cuadros delimitadores.
- Gestionar una plantilla de etiquetadoras
- Garantizar una buena calidad de la etiqueta
- Gestionar y versionar nuestros datos y etiquetas
- Orquestar todo el proceso
- Intégrelo en el sistema CI/CD
Podemos hacer todo esto con los servicios de AWS. Para facilitar el etiquetado y administrar nuestra fuerza laboral, utilizamos Amazon SageMaker Ground Truth, un servicio de etiquetado de datos que le permite crear y administrar sus propios flujos de trabajo y fuerza laboral de etiquetado de datos. Puede administrar su propia fuerza laboral privada de etiquetadores o utilizar el poder de etiquetadores externos a través de Turco mecánico amazónico o proveedores externos.
Además de eso, todo el proceso se puede configurar y administrar a través del SDK de AWS, que es lo que utilizamos para organizar nuestro flujo de trabajo de etiquetado como parte de nuestra canalización de CI/CD.
Los trabajos de etiquetado se utilizan para gestionar los flujos de trabajo de etiquetado. SageMaker Ground Truth proporciona plantillas listas para usar para muchos tipos diferentes de tareas de etiquetado, incluido el dibujo de cuadros delimitadores. Para obtener más detalles sobre cómo configurar un trabajo de etiquetado para tareas de cuadro delimitador, consulte Optimización del etiquetado de datos para la detección de objetos YOLO en Amazon SageMaker Ground Truth. Para nuestro caso de uso, adaptamos la plantilla de tareas para las tareas del cuadro delimitador y utilizamos anotadores humanos proporcionados por Mechanical Turk para etiquetar nuestras imágenes de forma predeterminada. La siguiente captura de pantalla muestra lo que ve un etiquetador cuando trabaja en una imagen.
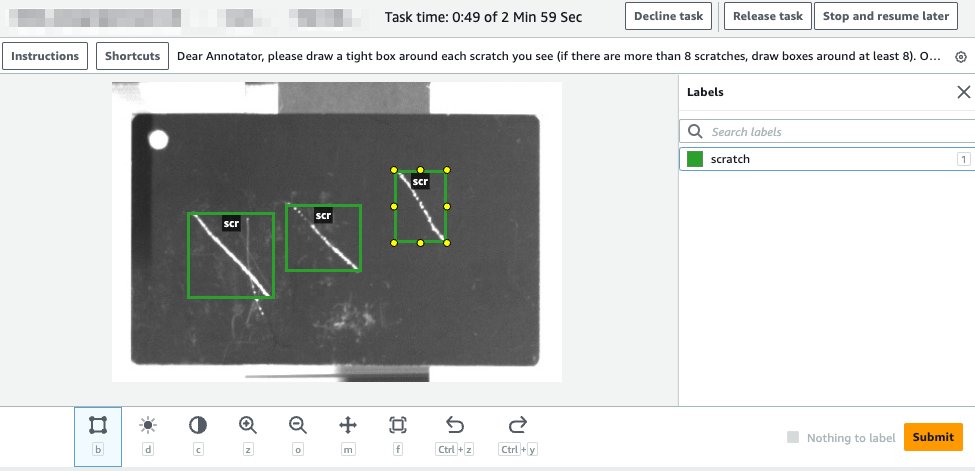
Hablemos a continuación de la calidad de las etiquetas. La calidad de nuestras etiquetas afectará la calidad de nuestro modelo ML. Al automatizar el etiquetado de imágenes con una fuerza laboral humana externa como Mechanical Turk, es un desafío garantizar una calidad de etiqueta buena y consistente debido a la falta de experiencia en el campo. A veces se requiere una fuerza laboral privada de expertos en el dominio. Sin embargo, en nuestra solución de muestra utilizamos Mechanical Turk para implementar el etiquetado automatizado de nuestras imágenes.
Hay muchas maneras de garantizar una buena calidad de las etiquetas. Para obtener más información sobre las mejores prácticas, consulte la charla de AWS re:Invent 2019, Cree conjuntos de datos de entrenamiento precisos con Amazon SageMaker Ground Truth. Como parte de esta solución de muestra, decidimos centrarnos en lo siguiente:
Finalmente, debemos pensar en cómo almacenar nuestras etiquetas para que puedan reutilizarse para el entrenamiento posterior y permitir la trazabilidad de los datos de entrenamiento del modelo utilizado. El resultado de un trabajo de etiquetado de SageMaker Ground Truth es un archivo en formato de líneas JSON que contiene las etiquetas y metadatos adicionales. Decidimos utilizar la tienda fuera de línea de Amazon SageMaker Feature Store para almacenar nuestras etiquetas. En comparación con simplemente almacenar las etiquetas en Amazon Simple Storage Service (Amazon S3), nos brinda algunas ventajas distintas:
- Almacena un historial completo de valores de características, combinado con consultas de un momento dado. Esto nos permite versionar fácilmente nuestro conjunto de datos y garantizar la trazabilidad.
- Como almacén de funciones central, promueve la reutilización y la visibilidad de nuestros datos.
Para obtener una introducción a SageMaker Feature Store, consulte Introducción a Amazon SageMaker Feature Store. SageMaker Feature Store admite el almacenamiento de funciones en formato tabular. En nuestro ejemplo, almacenamos las siguientes características para cada imagen etiquetada:
- La ubicación donde se almacena la imagen en Amazon S3
- Dimensiones de la imagen
- Las coordenadas del cuadro delimitador y los valores de clase.
- Una bandera de estado que indica si la etiqueta ha sido aprobada para su uso en capacitación.
- El nombre del trabajo de etiquetado utilizado para crear la etiqueta.
La siguiente captura de pantalla muestra cómo se vería una entrada típica en la tienda de funciones.

Con este formato, podemos consultar fácilmente el almacén de funciones y trabajar con herramientas familiares como Pandas para construir un conjunto de datos que se utilizará para el entrenamiento más adelante.
Orquestar el etiquetado de datos
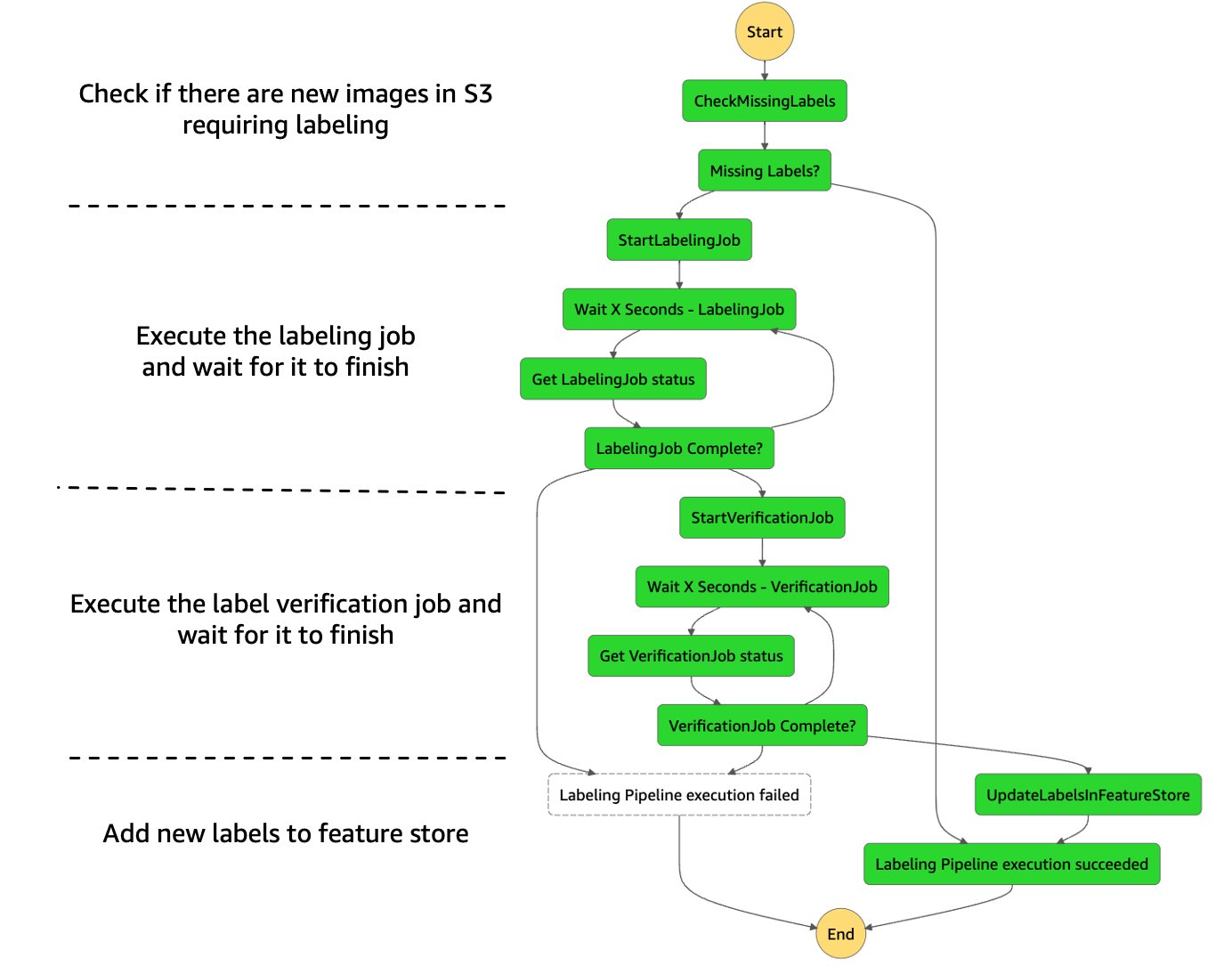
¡Finalmente, es hora de automatizar y orquestar cada uno de los pasos de nuestro proceso de etiquetado! Para ello utilizamos AWS Step Functions, un servicio de flujo de trabajo sin servidor que nos proporciona integraciones API para orquestar y visualizar rápidamente los pasos de nuestro flujo de trabajo. También utilizamos un conjunto de funciones de AWS Lambda para algunos de los pasos más complejos, específicamente los siguientes:
- Compruebe si hay imágenes nuevas que requieran etiquetado en Amazon S3
- Prepare los datos en el formato de entrada requerido y comience el trabajo de etiquetado.
- Prepare los datos en el formato de entrada requerido e inicie el trabajo de verificación de etiquetas
- Escriba el conjunto final de etiquetas en la tienda de funciones.
La siguiente figura muestra cómo se ve la máquina de estado de etiquetado completa de Step Functions.
Etiquetado: Despliegue de infraestructura e integración en CI/CD
El último paso es integrar el flujo de trabajo de Step Functions en nuestro sistema CI/CD y garantizar que implementamos la infraestructura necesaria. Para realizar esta tarea, utilizamos el kit de desarrollo en la nube de AWS (AWS CDK) para crear toda la infraestructura necesaria, como las funciones Lambda y el flujo de trabajo de Step Functions. Con CDK Pipelines, un módulo de AWS CDK, creamos una canalización en AWS CodePipeline que implementa cambios en nuestra infraestructura y activa una canalización adicional para iniciar el flujo de trabajo de Step Functions. La integración de Step Functions en CodePipeline facilita esta tarea. Usamos acciones de Amazon EventBridge y CodePipeline Source para asegurarnos de que la canalización se active según una programación, así como también cuando los cambios se envíen a git.
El siguiente diagrama muestra en detalle cómo se ve la arquitectura CI/CD para etiquetado.

Resumen de la automatización del etiquetado de datos
Ahora tenemos un proceso en funcionamiento para crear automáticamente etiquetas a partir de imágenes sin etiquetar de etiquetas metálicas utilizando SageMaker Ground Truth. Las imágenes se recogen de Amazon S3 y se introducen en un trabajo de etiquetado de SageMaker Ground Truth. Una vez etiquetadas las imágenes, realizamos un control de calidad mediante un trabajo de verificación de etiquetas. Finalmente, las etiquetas se almacenan en un grupo de funciones en SageMaker Feature Store. Si desea probar el ejemplo práctico usted mismo, consulte el documento adjunto repositorio de GitHub. ¡Veamos a continuación cómo automatizar la construcción de modelos!
Automatización de la construcción de modelos
De manera similar al etiquetado, echemos un vistazo en profundidad a nuestro proceso de creación de modelos. Como mínimo, necesitamos orquestar los siguientes pasos:
- Obtenga las últimas funciones de la tienda de funciones
- Prepare los datos para el entrenamiento del modelo.
- Entrenar el modelo
- Evaluar el rendimiento del modelo
- Versionar y almacenar el modelo.
- Aprobar el modelo para su implementación si el rendimiento es aceptable
El proceso de construcción del modelo suele estar dirigido por un científico de datos y es el resultado de una serie de experimentos realizados utilizando cuadernos o código Python. Podemos seguir un proceso simple de tres pasos para convertir un experimento en una canalización MLOps totalmente automatizada:
- Convierta el código de preprocesamiento, capacitación y evaluación existente en scripts de línea de comandos.
- Cree una definición de canalización de SageMaker para organizar la creación de modelos. Utilice los scripts creados en el paso uno como parte de los pasos de procesamiento y capacitación.
- Integre la canalización en su flujo de trabajo de CI/CD.
Este proceso de tres pasos es genérico y se puede utilizar para cualquier arquitectura de modelo y marco de aprendizaje automático de su elección. Sigámoslo y comencemos con el Paso 1 para crear los siguientes scripts:
- preproceso.py – Esto extrae imágenes etiquetadas de SageMaker Feature Store, divide el conjunto de datos y lo transforma al formato requerido para entrenar nuestro modelo, en nuestro caso el formato de entrada para YOLOv8
- tren.py – Esto entrena a un Modelo de detección de objetos Ultralytics YOLOv8 usando PyTorch para detectar rayones en imágenes de etiquetas metálicas
Orquestar la construcción de modelos
En el Paso 2, agrupamos estos scripts en trabajos de capacitación y procesamiento y definimos el proceso final de SageMaker, que se parece a la siguiente figura.
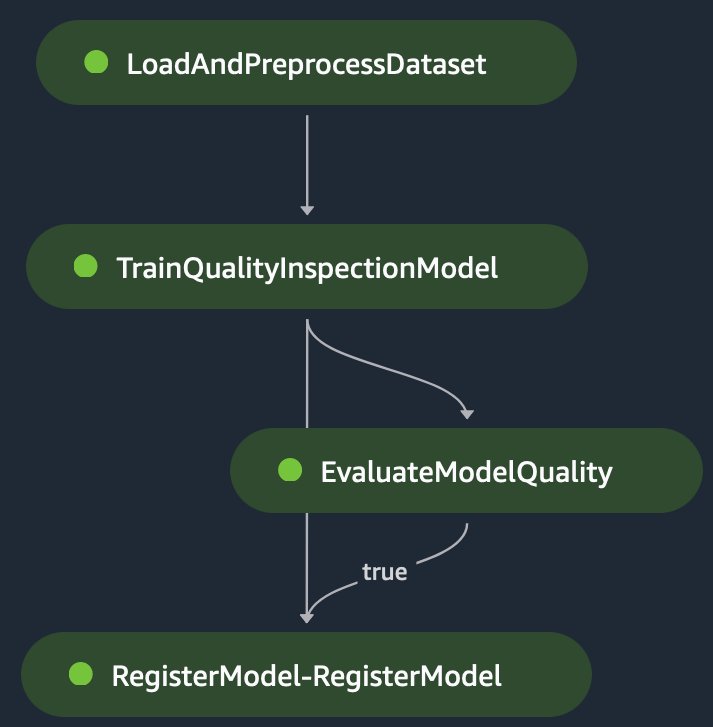
Consta de los siguientes pasos:
- Un ProcessingStep para cargar las últimas funciones de SageMaker Feature Store; dividir el conjunto de datos en conjuntos de entrenamiento, validación y prueba; y almacenar los conjuntos de datos como archivos tar para entrenamiento.
- Un TrainingStep para entrenar el modelo utilizando los conjuntos de datos de entrenamiento, validación y prueba y exportar la métrica de precisión promedio (mAP) media para el modelo.
- Un ConditionStep para evaluar si el valor de la métrica mAP del modelo entrenado está por encima de un umbral configurado. Si es así, se ejecuta un paso RegisterModel que registra el modelo entrenado en el Registro de modelos de SageMaker.
Si está interesado en el código detallado de la tubería, consulte la definición de tubería en nuestro repositorio de muestra.
Capacitación: Despliegue de infraestructura e integración en CI/CD
Ahora es el momento del Paso 3: integración en el flujo de trabajo de CI/CD. Nuestro proceso de CI/CD sigue el mismo patrón ilustrado en la sección de etiquetado anterior. Usamos AWS CDK para implementar las canalizaciones necesarias desde CodePipeline. La única diferencia es que utilizamos Amazon SageMaker Pipelines en lugar de Step Functions. La definición de canalización de SageMaker se construye y activa como parte de una acción de CodeBuild en CodePipeline.

Conclusión
Ahora tenemos un flujo de trabajo de entrenamiento de modelos y etiquetado totalmente automatizado utilizando SageMaker. Comenzamos creando scripts de línea de comando a partir del código del experimento. Luego utilizamos SageMaker Pipelines para orquestar cada uno de los pasos del flujo de trabajo de entrenamiento del modelo. Los scripts de línea de comando se integraron como parte de los pasos de capacitación y procesamiento. Al final del proceso, se versiona el modelo entrenado y se registra en el Registro de modelos de SageMaker.
Consulte la Parte 3 de esta serie, donde veremos más de cerca el paso final de nuestro flujo de trabajo MLOps. ¡Crearemos la canalización que compila e implementa el modelo en un dispositivo perimetral utilizando AWS IoT Greengrass!
Sobre los autores
 Michael Roth es un arquitecto de soluciones senior en AWS que brinda soporte a los clientes de fabricación en Alemania para resolver sus desafíos comerciales a través de la tecnología de AWS. Además del trabajo y la familia, le interesan los coches deportivos y le gusta el café italiano.
Michael Roth es un arquitecto de soluciones senior en AWS que brinda soporte a los clientes de fabricación en Alemania para resolver sus desafíos comerciales a través de la tecnología de AWS. Además del trabajo y la familia, le interesan los coches deportivos y le gusta el café italiano.
 Jörg Wöhrle es arquitecto de soluciones en AWS y trabaja con clientes de fabricación en Alemania. Apasionado por la automatización, Joerg trabajó como desarrollador de software, ingeniero de DevOps e ingeniero de confiabilidad del sitio en su vida anterior a AWS. Más allá de las nubes, es un corredor ambicioso y disfruta de tiempo de calidad con su familia. Entonces, si tienes un desafío de DevOps o quieres salir a correr: díselo.
Jörg Wöhrle es arquitecto de soluciones en AWS y trabaja con clientes de fabricación en Alemania. Apasionado por la automatización, Joerg trabajó como desarrollador de software, ingeniero de DevOps e ingeniero de confiabilidad del sitio en su vida anterior a AWS. Más allá de las nubes, es un corredor ambicioso y disfruta de tiempo de calidad con su familia. Entonces, si tienes un desafío de DevOps o quieres salir a correr: díselo.
 Johannes Langer es arquitecto senior de soluciones en AWS y trabaja con clientes empresariales en Alemania. A Johannes le apasiona aplicar el aprendizaje automático para resolver problemas empresariales reales. En su vida personal, a Johannes le gusta trabajar en proyectos de mejoras para el hogar y pasar tiempo al aire libre con su familia.
Johannes Langer es arquitecto senior de soluciones en AWS y trabaja con clientes empresariales en Alemania. A Johannes le apasiona aplicar el aprendizaje automático para resolver problemas empresariales reales. En su vida personal, a Johannes le gusta trabajar en proyectos de mejoras para el hogar y pasar tiempo al aire libre con su familia.






{kind=link}