

Image by author
A few months ago we learned about Falcon LLM, founded by Technological Innovation Institute (TII), a company that is part of the Abu Dhabi government’s Advanced technology Research Council. A few months later, they have gotten even bigger and better, literally a lot bigger.
Falcon 180B is the largest open language model, with 180 billion parameters. Yes, that’s right, you read that right: 180 billion. It was trained with 3.5 billion tokens using TII’s RefinedWeb dataset. This represents the longest single epoch pre-training for an open model.
But we will not focus only on the size of the model, but also on the power and potential behind it. Falcon 180B is creating new standards with Large Language Models (LLM) when it comes to capabilities.
Models that are available:
The Falcon-180B Base model is a causal decoder only model. I would recommend using this model to further fit your own data.
The Falcon-180B-Chat model has similarities to the base version, but goes a little deeper by fine-tuning it using a combination of Ultrachat, Platypus, and Airoboros instruction (chat) data sets.
Training
Falcon 180B is an upgraded version of its predecessor Falcon 40B, with new capabilities such as multi-consultation care for improved scalability. The model used 4,096 GPUs in Amazon SageMaker and was trained with 3.5 billion tokens. This is equivalent to approximately 7,000,000 GPU hours. This means that Falcon 180B is 2.5 times faster than LLM like Llama 2 and was trained on 4 times more computing.
Wow that’s a lot.
Data
The dataset used for Falcon 180B was predominantly (85%) sourced from RefinedWeb, as well as trained on a combination of selected data such as white papers, conversations, and some code elements.
Reference point
The part you all want to know: how is the Falcon 180B doing among its competitors?
Falcon 180B is currently the best openly published LLM to date (September 2023). It has been shown to outperform OpenAI’s Llama 2 70B and GPT-3.5 in MMLU. It is usually between GPT 3.5 and GPT 4.
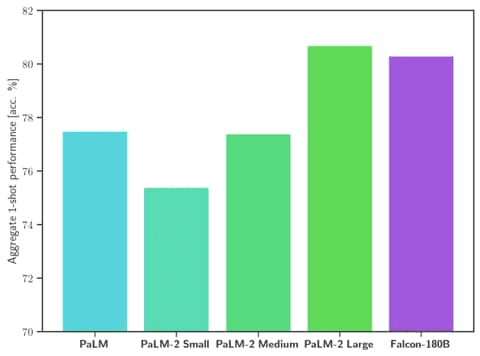
Image by HuggingFace Falcon 180B
Falcon 180B was ranked 68.74 on Hugging Face’s leaderboard, making it the highest scoring openly released pre-trained LLM, where it surpassed Meta’s LLaMA 2 which was at 67.35.
For developers and natural language processing (NLP) enthusiasts, Falcon 180B is available in the Hugging Face ecosystem, starting with Transformers version 4.33.
However, as you can imagine, due to the size of the model, you will have to take into account the hardware requirements. To better understand the hardware requirements, HuggingFace performed the necessary testing to run the model in different use cases, as shown in the image below:
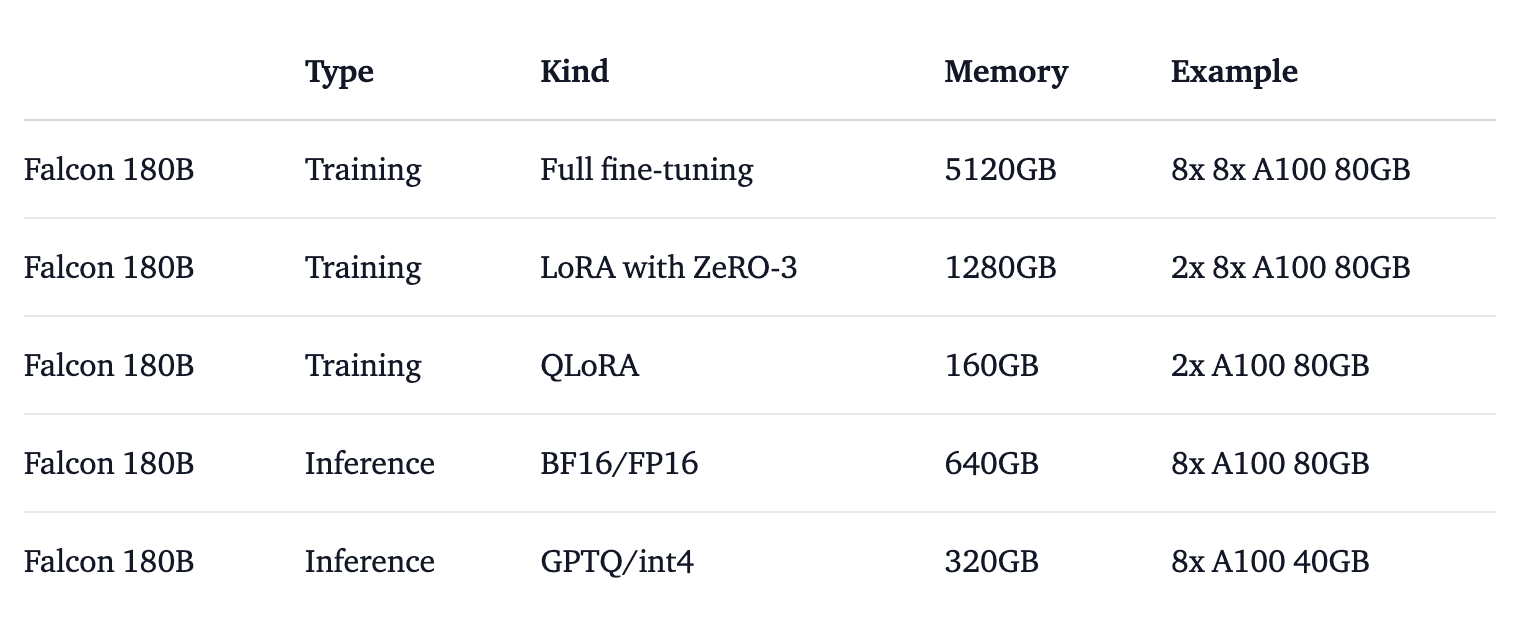
Image by HuggingFace Falcon 180B
If you want to try it out and play with it, you can try the Falcon 180B through the demo by clicking this link: Falcon 180B Demonstration.
Falcon 180B vs. ChatGPT
The model has some important hardware requirements that are not easily accessible to everyone. However, based on other people’s findings when testing both Falcon 180Bs against ChatGPT by asking them the same questions, ChatGPT took the win.
It worked well in code generation, however, it needs a boost in text extraction and summarization.
If you’ve had a chance to try it, let us know what your findings were compared to other LLMs. Is the Falcon 180B worth all the hype around it, as it is currently the largest publicly available model on the Hugging Face model center?
Well, it seems to be, as you have shown, at the top of the charts for open access models, and models like PaLM-2, a run for their money. We will know sooner or later.
nisha arya is a data scientist, freelance technical writer, and community manager at KDnuggets. She is particularly interested in providing professional data science advice or tutorials and theory-based insights into data science. She also wants to explore the different ways in which artificial intelligence can benefit the longevity of human life. A great student looking to expand her technological knowledge and writing skills, while she helps guide others.
nisha arya is a data scientist and freelance technical writer. She is particularly interested in providing professional data science advice or tutorials and theory-based insights into data science. She also wants to explore the different ways in which artificial intelligence can benefit the longevity of human life. A great student looking to expand her technological knowledge and writing skills, while she helps guide others.






{kind=link}