
Hoy, nos complace anunciar que los modelos básicos de Code Llama, desarrollados por Meta, están disponibles para que los clientes a través de Amazon SageMaker JumpStart los implementen con un solo clic para ejecutar inferencias. Code Llama es un modelo de lenguaje grande (LLM) de última generación capaz de generar código y lenguaje natural sobre el código a partir de indicaciones de código y lenguaje natural. Code Llama es gratuito para investigación y uso comercial. Puede probar este modelo con SageMaker JumpStart, un centro de aprendizaje automático (ML) que brinda acceso a algoritmos, modelos y soluciones de ML para que pueda comenzar rápidamente con ML. En esta publicación, explicamos cómo descubrir e implementar el modelo Code Llama a través de SageMaker JumpStart.
¿Qué es el Código Llama?
Code Llama es un modelo lanzado por ai.meta.com/” target=”_blank” rel=”noopener”>Meta que está construido sobre Llama 2 y es un modelo de última generación diseñado para mejorar la productividad de las tareas de programación de los desarrolladores ayudándoles a crear código bien documentado y de alta calidad. Los modelos muestran un rendimiento de última generación en Python, C++, Java, PHP, C#, TypeScript y Bash, y tienen el potencial de ahorrar tiempo a los desarrolladores y hacer que los flujos de trabajo del software sean más eficientes. Viene en tres variantes, diseñadas para cubrir una amplia variedad de aplicaciones: el modelo fundamental (Code Llama), un modelo especializado en Python (Code Llama-Python) y un modelo de seguimiento de instrucciones para comprender instrucciones en lenguaje natural (Code Llama-Instruct). ). Todas las variantes de Code Llama vienen en tres tamaños: parámetros 7B, 13B y 34B. Las variantes de instrucción y base 7B y 13B admiten el relleno según el contenido circundante, lo que las hace ideales para aplicaciones de asistente de código.
Los modelos se diseñaron utilizando Llama 2 como base y luego se entrenaron con 500 mil millones de tokens de datos de código, con la versión especializada de Python entrenada con 100 mil millones de tokens incrementales. Los modelos Code Llama proporcionan generaciones estables con hasta 100.000 tokens de contexto. Todos los modelos están entrenados en secuencias de 16.000 tokens y muestran mejoras en entradas con hasta 100.000 tokens.
El modelo está disponible bajo el mismo Licencia comunitaria como Llama 2.
¿Qué es SageMaker JumpStart?
Con SageMaker JumpStart, los profesionales del aprendizaje automático pueden elegir entre una lista cada vez mayor de modelos básicos de mejor rendimiento. Los profesionales del aprendizaje automático pueden implementar modelos básicos en instancias dedicadas de Amazon SageMaker dentro de un entorno aislado de red y personalizar modelos utilizando SageMaker para el entrenamiento y la implementación de modelos.
Ahora puede descubrir e implementar modelos de Code Llama con unos pocos clics en Amazon SageMaker Studio o mediante programación a través del SDK de Python de SageMaker, lo que le permite obtener el rendimiento del modelo y controles MLOps con funciones de SageMaker como Amazon SageMaker Pipelines, Amazon SageMaker Debugger o registros de contenedores. . El modelo se implementa en un entorno seguro de AWS y bajo los controles de su VPC, lo que ayuda a garantizar la seguridad de los datos. Los modelos Code Llama son detectables y se pueden implementar en las regiones de EE. UU. Este (Norte de Virginia), EE. UU. Oeste (Oregón) y Europa (Irlanda).
Los clientes deben aceptar el EULA para implementar el modelo Visa SageMaker SDK.
Descubre modelos
Puede acceder a los modelos básicos de Code Llama a través de SageMaker JumpStart en la interfaz de usuario de SageMaker Studio y el SDK de SageMaker Python. En esta sección, repasamos cómo descubrir los modelos en SageMaker Studio.
SageMaker Studio es un entorno de desarrollo integrado (IDE) que proporciona una única interfaz visual basada en web donde puede acceder a herramientas diseñadas específicamente para realizar todos los pasos de desarrollo de ML, desde la preparación de datos hasta la creación, el entrenamiento y la implementación de sus modelos de ML. Para obtener más detalles sobre cómo comenzar y configurar SageMaker Studio, consulte Amazon SageMaker Studio.
En SageMaker Studio, puede acceder a SageMaker JumpStart, que contiene modelos, cuadernos y soluciones prediseñadas previamente entrenados, en Soluciones prediseñadas y automatizadas.
En la página de inicio de SageMaker JumpStart, puede buscar soluciones, modelos, cuadernos y otros recursos. Puedes encontrar los modelos de Code Llama en el Modelos básicos: generación de texto carrusel.
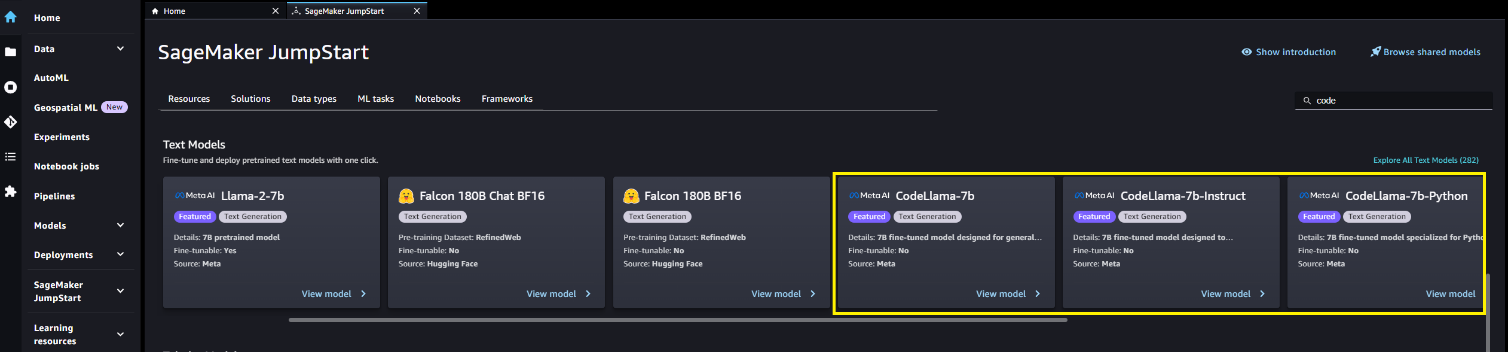
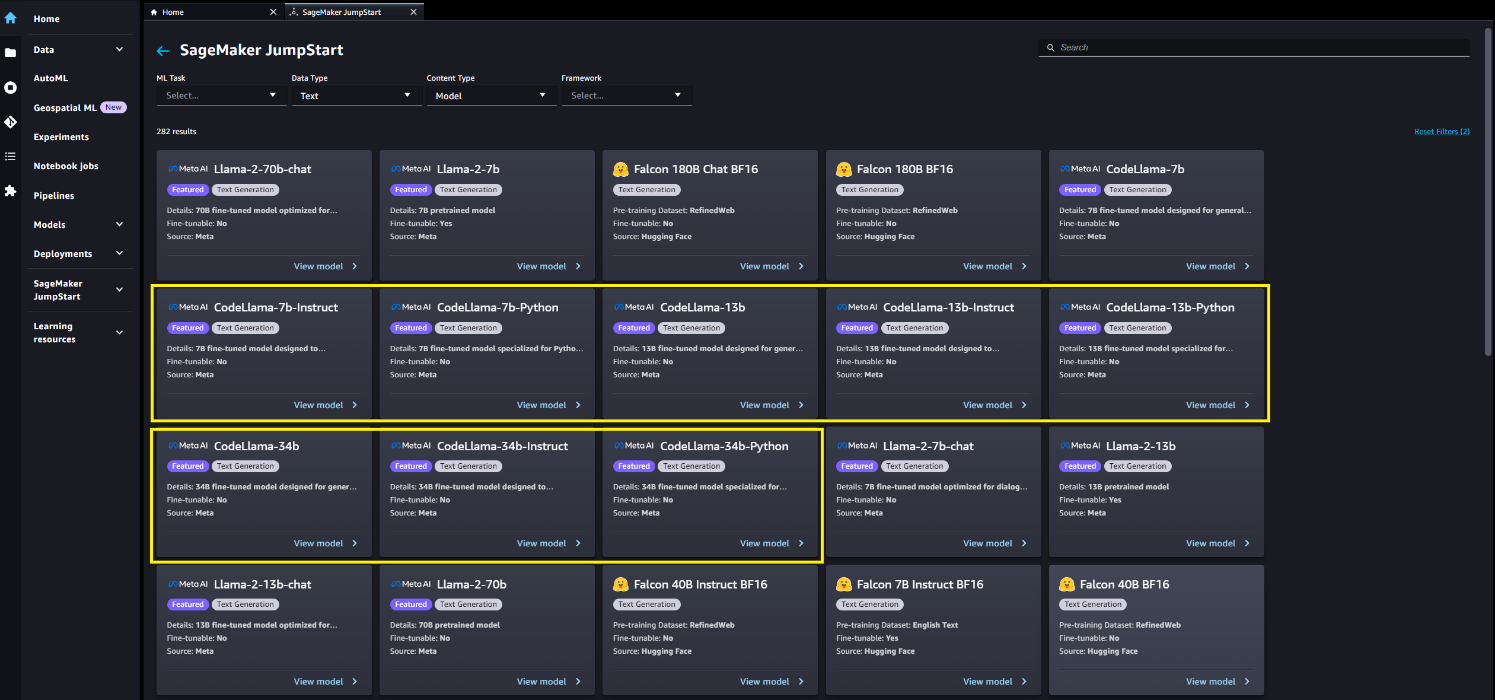
También puede encontrar otras variantes de modelos eligiendo Explora todos los modelos de generación de texto o buscando Code Llama.
Puede elegir la tarjeta de modelo para ver detalles sobre el modelo, como la licencia, los datos utilizados para entrenar y cómo utilizarlo. También encontrarás dos botones, Desplegar y Cuaderno abiertoque te ayudará a utilizar el modelo.
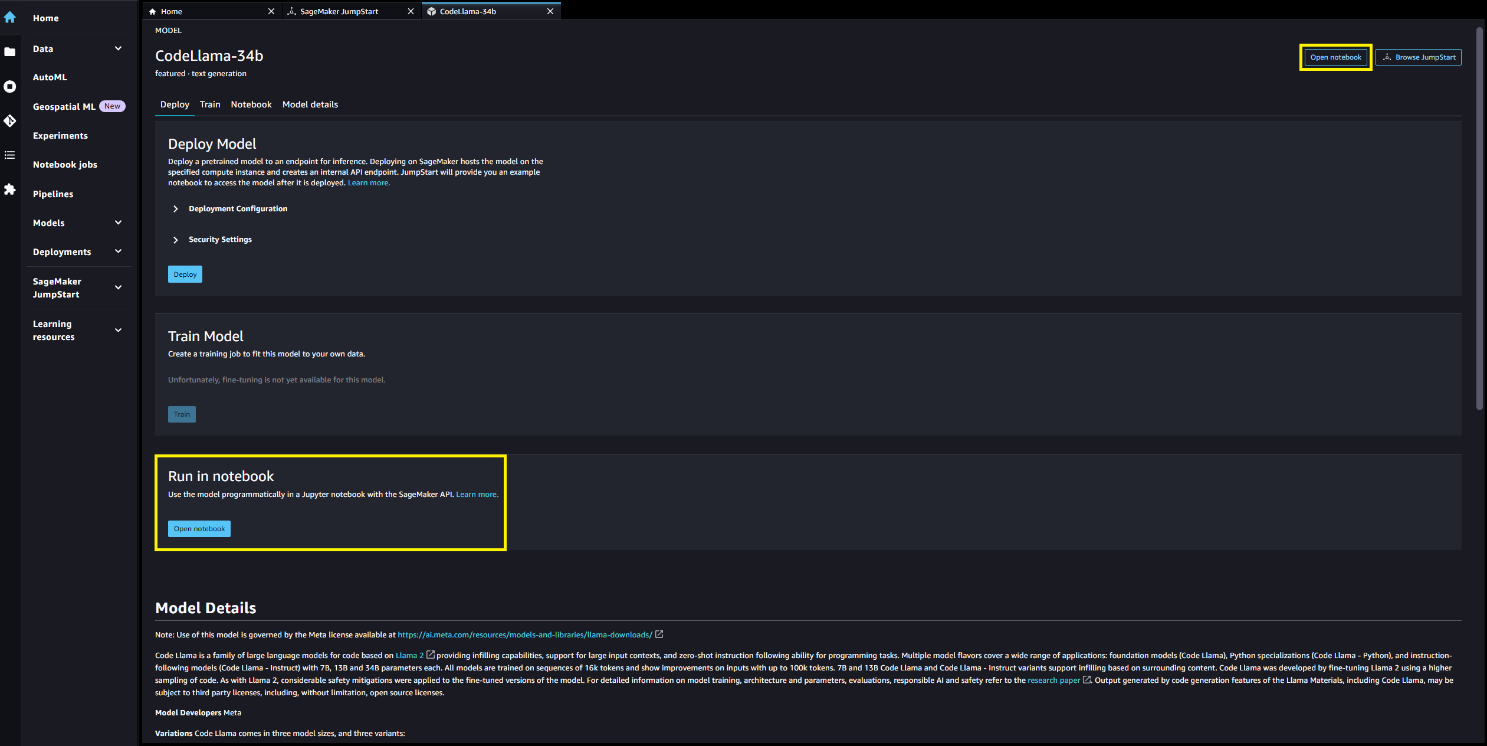
Desplegar
cuando tu eliges Desplegar y reconoce los términos, comenzará el despliegue. Alternativamente, puede implementar a través del cuaderno de ejemplo eligiendo Cuaderno abierto. El cuaderno de ejemplo que proporciona orientación integral sobre cómo implementar el modelo para inferencia y limpieza de recursos.
Para implementar usando el portátil, comenzamos seleccionando un modelo apropiado, especificado por el model_id. Puede implementar cualquiera de los modelos seleccionados en SageMaker con el siguiente código:
Esto implementa el modelo en SageMaker con configuraciones predeterminadas, incluido el tipo de instancia predeterminado y las configuraciones de VPC predeterminadas. Puede cambiar estas configuraciones especificando valores no predeterminados en JumpStartModelo. Una vez implementado, puede ejecutar inferencia contra el punto final implementado a través del predictor de SageMaker:
Tenga en cuenta que, de forma predeterminada, accept_eula se establece en false. Necesitas configurar accept_eula=true para invocar el punto final con éxito. Al hacerlo, acepta el acuerdo de licencia de usuario y la política de uso aceptable como se mencionó anteriormente. Tú también puedes ai.meta.com/resources/models-and-libraries/llama-downloads/” target=”_blank” rel=”noopener”>descargar el acuerdo de licencia.
Custom_attributes Los que se utilizan para aprobar el EULA son pares clave/valor. La clave y el valor están separados por = y los pares están separados por ;. Si el usuario pasa la misma clave más de una vez, el último valor se conserva y se pasa al controlador del script (en este caso, se utiliza para la lógica condicional). Por ejemplo, si accept_eula=false; accept_eula=true se pasa al servidor, luego accept_eula=true se guarda y se pasa al controlador del script.
Los parámetros de inferencia controlan el proceso de generación de texto en el punto final. El control máximo de nuevos tokens se refiere al tamaño de la salida generada por el modelo. Tenga en cuenta que esto no es lo mismo que el número de palabras porque el vocabulario del modelo no es el mismo que el vocabulario del idioma inglés y cada token puede no ser una palabra del idioma inglés. La temperatura controla la aleatoriedad en la salida. Una temperatura más alta da como resultado resultados más creativos y alucinados. Todos los parámetros de inferencia son opcionales.
La siguiente tabla enumera todos los modelos de Code Llama disponibles en SageMaker JumpStart junto con los ID de modelo, los tipos de instancias predeterminados y los tokens máximos admitidos (suma del número de tokens de entrada y el número de tokens generados para todas las solicitudes simultáneas) admitidos para cada uno de estos modelos.
| Nombre del modelo | ID del modelo | Tipo de instancia predeterminado | Fichas máximas admitidas |
| CódigoLlama-7b | meta-generación de texto-llama-codellama-7b | ml.g5.2xgrande | 10000 |
| CodeLlama-7b-Instrucción | meta-generación de texto-llama-codellama-7b-instruct | ml.g5.2xgrande | 10000 |
| CódigoLlama-7b-Python | meta-generación de texto-llama-codellama-7b-python | ml.g5.2xgrande | 10000 |
| CódigoLlama-13b | meta-generación de texto-llama-codellama-13b | ml.g5.12xgrande | 32000 |
| CodeLlama-13b-Instrucción | meta-generación de texto-llama-codellama-13b-instruct | ml.g5.12xgrande | 32000 |
| CódigoLlama-13b-Python | meta-generación de texto-llama-codellama-13b-python | ml.g5.12xgrande | 32000 |
| CódigoLlama-34b | meta-generación de texto-llama-codellama-34b | ml.g5.48xgrande | 48000 |
| CodeLlama-34b-Instrucción | meta-generación de texto-llama-codellama-34b-instruct | ml.g5.48xgrande | 48000 |
| CódigoLlama-34b-Python | meta-generación de texto-llama-codellama-34b-python | ml.g5.48xgrande | 48000 |
Si bien los modelos de Code Llama se entrenaron en una longitud de contexto de 16.000 tokens, los modelos informaron un buen rendimiento en ventanas de contexto aún más grandes. La columna de tokens máximos admitidos en la tabla anterior es el límite superior en la ventana de contexto admitida en el tipo de instancia predeterminado. Dado que el modelo Code Llama 7B solo puede admitir 10 000 tokens en una instancia ml.g5.2xlarge, recomendamos implementar una versión del modelo 13B o 34B si se requieren contextos más grandes para su aplicación.
De forma predeterminada, todos los modelos funcionan para tareas de generación de código. Tanto el modelo base como el de instrucción responden a tareas de relleno, aunque el modelo base tuvo resultados de mejor calidad para la mayoría de las consultas de muestra. Por último, solo los modelos de instrucción funcionan en tareas de instrucción. La siguiente tabla ilustra qué modelos tuvieron un buen rendimiento (Bueno) y un rendimiento moderado (Moderado) en consultas de ejemplo en los cuadernos de demostración.
| . | Codigo de GENERACION | Relleno de código | Instrucciones de código |
| CódigoLlama-7b | Bien | Bien | N / A |
| CodeLlama-7b-Instrucción | Bien | Moderado | Bien |
| CódigoLlama-7b-Python | Bien | N / A | N / A |
| CódigoLlama-13b | Bien | Bien | N / A |
| CodeLlama-13b-Instrucción | Bien | Moderado | Bien |
| CódigoLlama-13b-Python | Bien | N / A | N / A |
| CódigoLlama-34b | Bien | N / A | N / A |
| CodeLlama-34b-Instrucción | Bien | N / A | Bien |
| CódigoLlama-34b-Python | Bien | N / A | N / A |
Codigo de GENERACION
Los siguientes ejemplos se ejecutaron en el modelo CodeLlama-34b-Instruct con parámetros de carga útil "parameters": {"max_new_tokens": 256, "temperature": 0.2, "top_p": 0.9}:
Relleno de código
El relleno de código implica devolver el código generado dado el contexto circundante. Esto difiere de la tarea de generación de código porque, además de un segmento de código de prefijo, el modelo también cuenta con un sufijo de segmento de código. Se utilizaron tokens especiales durante el ajuste fino para marcar el comienzo del prefijo (<PRE>), el comienzo del sufijo (<SUF>), y el comienzo de la mitad (<MID>). Las secuencias de entrada al modelo deben estar en uno de los siguientes formatos:
- prefijo-sufijo-medio –
<PRE> {prefix} <SUF>{suffix} <MID> - sufijo-prefijo-medio –
<PRE> <SUF>{suffix} <MID> {prefix}
Los siguientes ejemplos utilizan el formato prefijo-sufijo-medio en el modelo CodeLlama-7b con carga útil parameters {"max_new_tokens": 256, "temperature": 0.05, "top_p": 0.9}:
Instrucciones de código
Meta también proporcionó una variante de Code Llama adaptada a las instrucciones. Las consultas de ejemplo en esta sección solo se pueden aplicar a estos modelos Code Llama ajustados por instrucciones, que son los modelos con un sufijo de instrucción de ID de modelo. El formato de instrucciones de Code Llama es el mismo que el formato de mensaje de chat de Llama-2, que detallamos en Los modelos básicos de Llama 2 ahora están disponibles en SageMaker JumpStart.
Un mensaje de usuario simple puede verse como el siguiente:
También puede agregar un mensaje del sistema con la siguiente sintaxis:
Finalmente, puede tener una interacción conversacional con el modelo al incluir todas las indicaciones del usuario anteriores y las respuestas del asistente en la entrada:
Estos ejemplos se ejecutaron en el modelo CodeLlama-13b-Instruct con parámetros de carga útil “parámetros”: {"max_new_tokens": 512, "temperature": 0.2, "top_p": 0.9}:
Limpiar
Una vez que haya terminado de ejecutar el cuaderno, asegúrese de eliminar todos los recursos que creó en el proceso para que se detenga su facturación. Utilice el siguiente código:
Conclusión
En esta publicación, le mostramos cómo comenzar con los modelos Code Llama en SageMaker Studio e implementar el modelo para generar código y lenguaje natural sobre código a partir de indicaciones de código y lenguaje natural. Dado que los modelos básicos están previamente entrenados, pueden ayudar a reducir los costos de capacitación e infraestructura y permitir la personalización para su caso de uso. Visite SageMaker JumpStart en SageMaker Studio ahora para comenzar.
Recursos
Sobre los autores
 Gabriel Synnaeve es director de investigación en el equipo de Facebook ai Research (FAIR) en Meta. Antes de Meta, Gabriel fue becario postdoctoral en el equipo de Emmanuel Dupoux en la École Normale Supérieure de París, trabajando en ingeniería inversa en la adquisición del lenguaje en bebés. Gabriel recibió su doctorado en modelado bayesiano aplicado a la IA de juegos de estrategia en tiempo real de la Universidad de Grenoble.
Gabriel Synnaeve es director de investigación en el equipo de Facebook ai Research (FAIR) en Meta. Antes de Meta, Gabriel fue becario postdoctoral en el equipo de Emmanuel Dupoux en la École Normale Supérieure de París, trabajando en ingeniería inversa en la adquisición del lenguaje en bebés. Gabriel recibió su doctorado en modelado bayesiano aplicado a la IA de juegos de estrategia en tiempo real de la Universidad de Grenoble.
 No Jamil es ingeniero asociado RL, IA generativa en Meta.
No Jamil es ingeniero asociado RL, IA generativa en Meta.
 Dr. kyle ulrich es un científico aplicado del equipo JumpStart de Amazon SageMaker. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión por computadora, series temporales, procesos bayesianos no paramétricos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
Dr. kyle ulrich es un científico aplicado del equipo JumpStart de Amazon SageMaker. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión por computadora, series temporales, procesos bayesianos no paramétricos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
 Dr. Ashish Khaitan Es científico aplicado sénior en Amazon SageMaker JumpStart y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado numerosos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
Dr. Ashish Khaitan Es científico aplicado sénior en Amazon SageMaker JumpStart y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado numerosos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
 Vivek Singh es gerente de producto de SageMaker JumpStart. Se centra en permitir que los clientes incorporen SageMaker JumpStart para simplificar y acelerar su recorrido de aprendizaje automático para crear aplicaciones de IA generativa.
Vivek Singh es gerente de producto de SageMaker JumpStart. Se centra en permitir que los clientes incorporen SageMaker JumpStart para simplificar y acelerar su recorrido de aprendizaje automático para crear aplicaciones de IA generativa.






{kind=link}