 NEWSLETTER
NEWSLETTER

Image by author
In a world where data is the new oil, understanding the nuances of a career in data science is more important than ever. Whether you’re a data enthusiast or a veteran exploring opportunities, using SQL can give you insight into the data science job market.
I hope you are eager to know which one data science job titles are the most attractive or which offer the highest salaries. Or maybe you’re wondering how experience levels are related. average salaries in data science?
In this article, we cover all of those questions (and more) as we delve deeper into the data science job market. Let us begin!
The data set we will use in this article is designed to shed light on salary patterns in the field of data science from 2021 to 2023. By highlighting elements such as work history, job titles, and corporate locations, it offers insights crucial on wage dispersion in the sector.
This article will find an answer to the following questions:
- What is the average salary like at different levels of experience?
- What are the most common job titles in data science?
- How does the salary distribution vary depending on the size of the company?
- Where are data science jobs primarily located geographically?
- Which jobs offer the best salaries in data science?
You can download this data from the Kaggle.
1. What is the average salary like at different experience levels?
In this SQL query, we find the average salary for different experience levels. The GROUP BY clause groups the data by experience level and the AVG function calculates the average salary for each group.
This helps understand how experience in the field influences earning potential, which is essential for you when planning your career paths in data science. Let’s look at the code.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;Now let’s visualize this result using Python.
Here is the code.
# Import required libraries for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# Set up the style for the graphs
sns.set(style="whitegrid")
# Initialize the list for storing graphs
graphs = ()
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Average Salary by Experience Level')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()Now let’s compare entry-level and experienced and mid-level and senior-level salaries.
Let’s start with the basic and experienced level. Here is the code.
# Filter the data for Entry_Level and Experienced levels
entry_experienced = df(df('experience_level').isin(('Entry_Level', 'Experienced')))
# Filter the data for Mid-Level and Senior levels
mid_senior = df(df('experience_level').isin(('Mid-Level', 'Senior')))
# Plotting the Entry_Level vs Experienced graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Entry_Level vs Experienced')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Here is the graph.
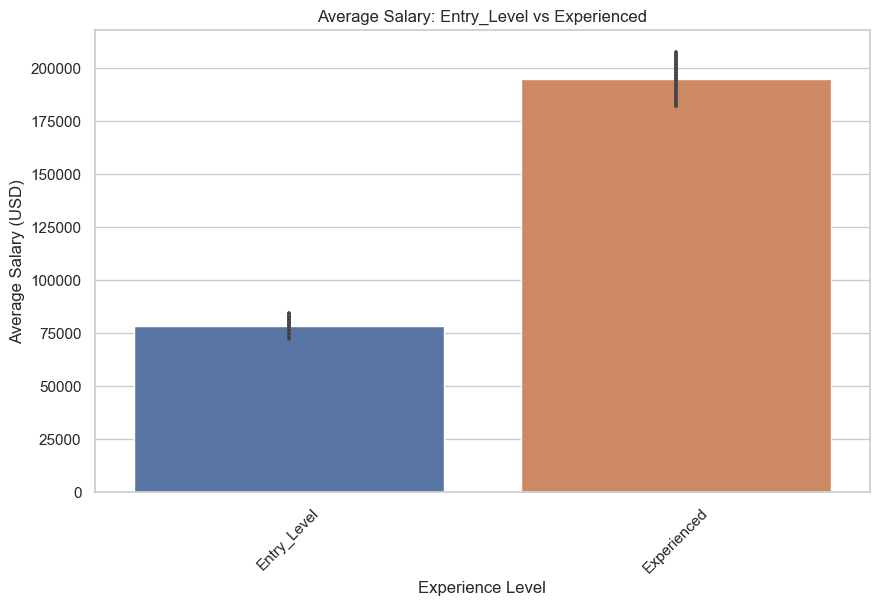
Now let’s draw, middle and higher level. Here is the code.
# Plotting the Mid-Level vs Senior graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Mid-Level vs Senior')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
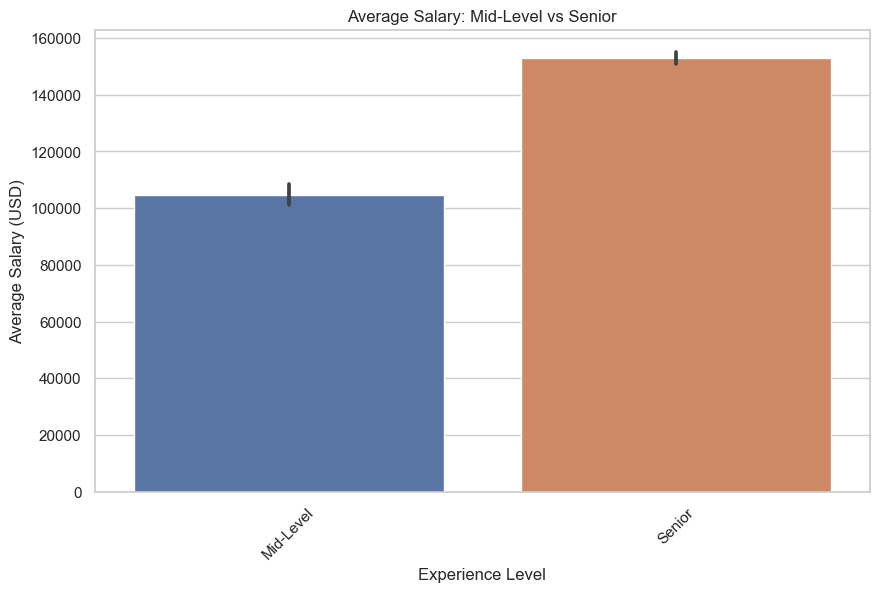
2. What are the most common job titles in data science?
Here, we extract the 10 most common data science jobs. The COUNT function counts the number of occurrences of each job title and the results are sorted in descending order to get the most common titles at the top.
This information gives you an idea of job market demand and will guide you in identifying potential roles you can pursue. Let’s look at the code.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;Ok, it’s time to visualize this query using Python.
Here is the code.
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df('job_title').value_counts().index(:10))
plt.title('Most Common Job Titles in Data Science')
plt.xlabel('Job Count')
plt.ylabel('Job Title')
graphs.append(plt.gcf())
plt.show()Let’s look at the graph.
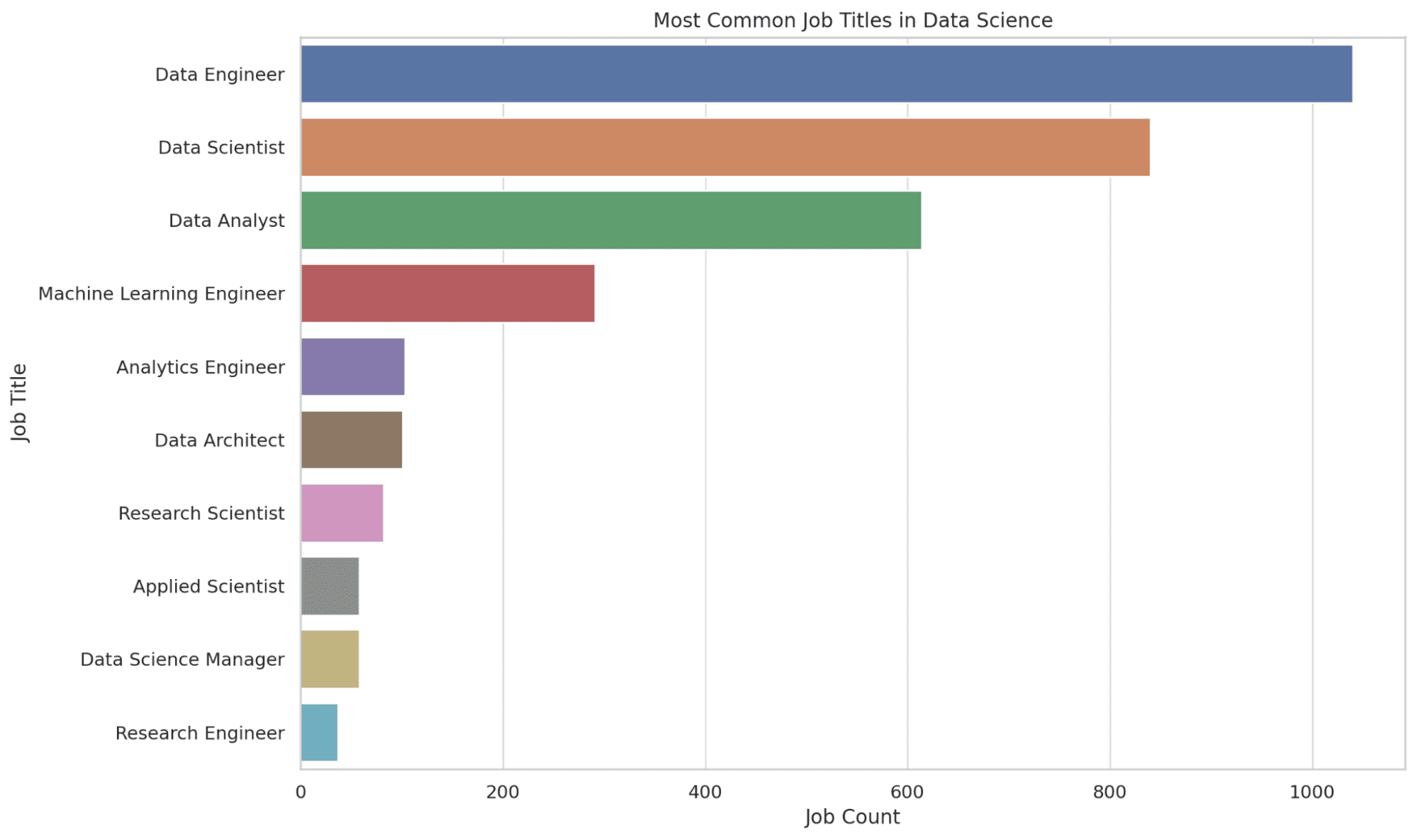
3. How does the salary distribution vary depending on the size of the company?
In this query, we extract the average, minimum, and maximum salaries for each company size group. Using aggregate functions like AVG, MIN, and MAX helps provide a comprehensive view of the salary landscape relative to the size of a company.
This data is essential as it helps you understand the potential earnings you can expect depending on the size of the company you want to join. Let’s look at the code.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;Now let’s visualize this query using Python.
Here is the code.
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=('Small', 'Medium', 'Large'))
plt.title('Salary Distribution by Company Size')
plt.xlabel('Company Size')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()Here is the result.
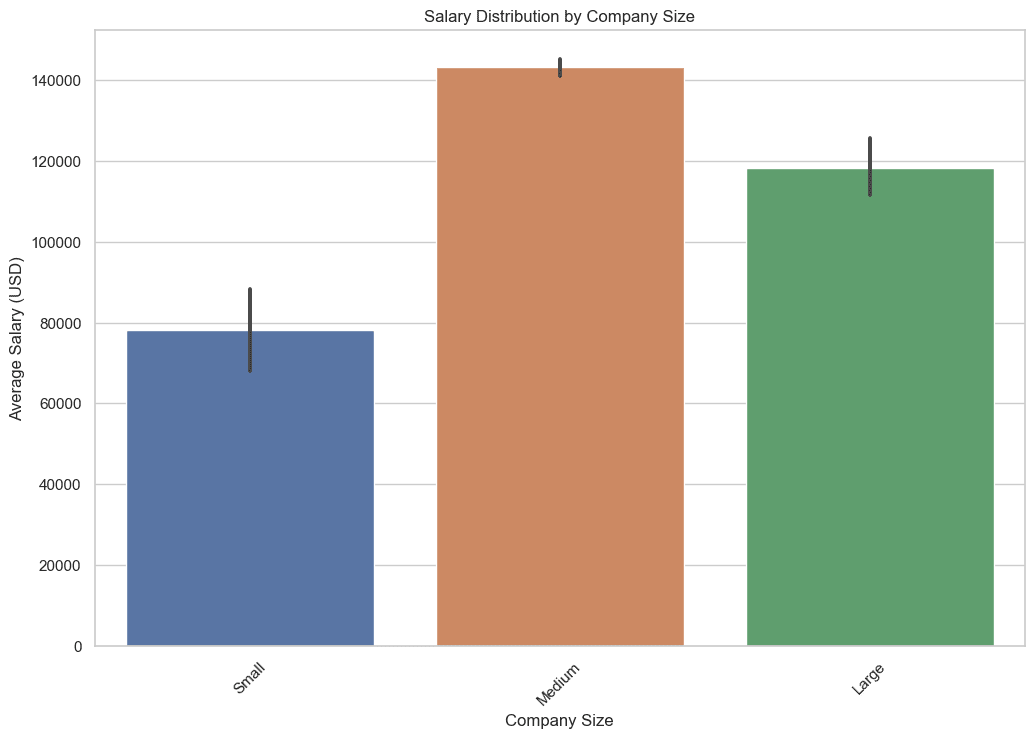
4. Where are data science jobs primarily located geographically?
Here, we identify the top 10 locations that offer the most data science job opportunities. We use the COUNT function to determine the number of job openings in each location, arranging them in descending order to highlight areas with the most opportunities.
Having this information provides readers with knowledge of the geographic areas that are hubs for data science functions, aiding in potential relocation decisions. Let’s look at the code.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;Now let’s create graphs from the above code, with Python.
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df('company_location').value_counts().index(:10))
plt.title('Geographical Distribution of Data Science Jobs')
plt.xlabel('Job Count')
plt.ylabel('Company Location')
graphs.append(plt.gcf())
plt.show()Let’s look at the graph below.
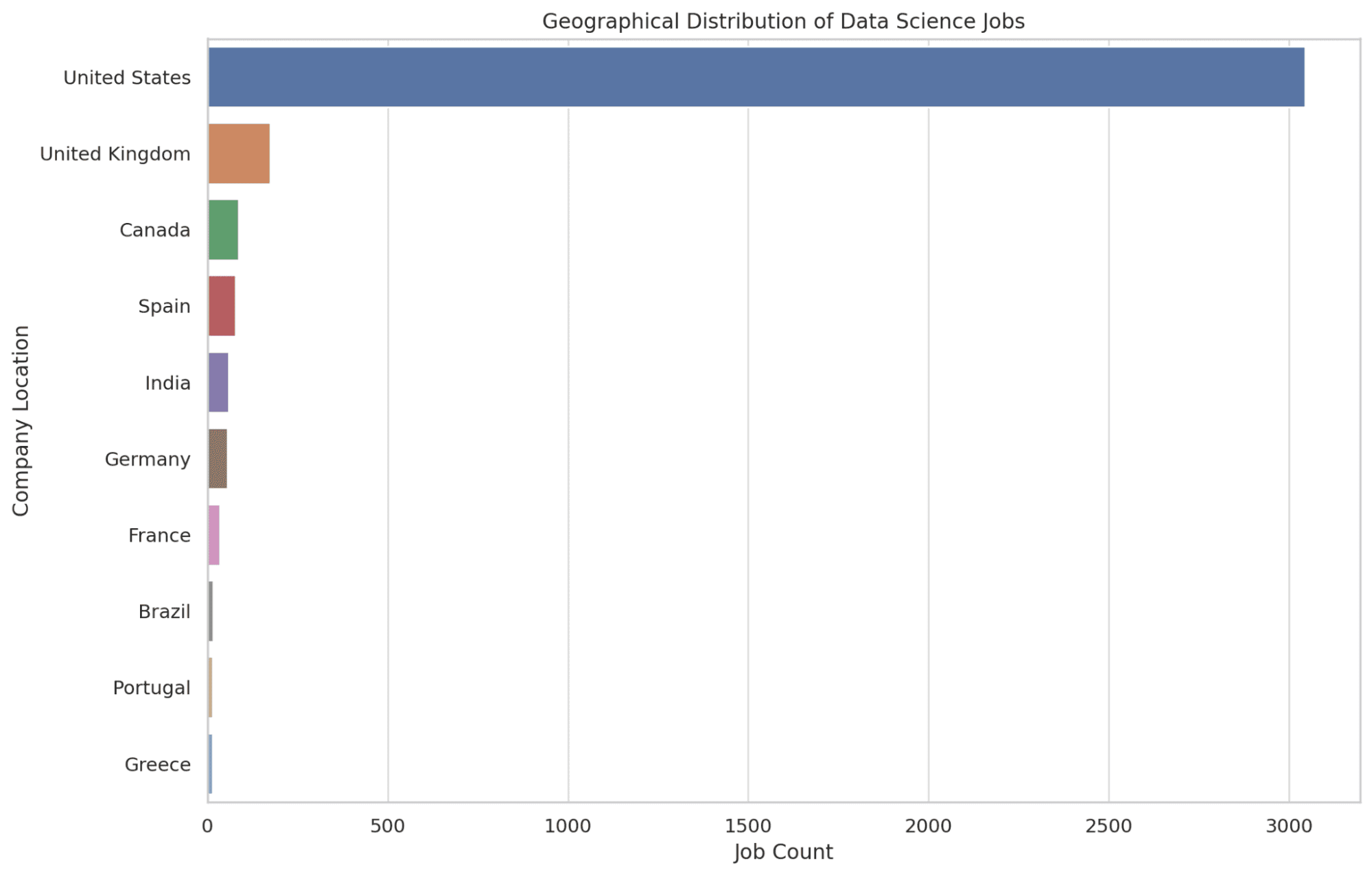
5. Which jobs offer the best salaries in data science?
Here, we identify the 10 highest-paying jobs in the data science sector. Using AVG, we calculate the average salary for each job, ranking them in descending order by average salary to highlight the most lucrative positions.
You can aspire to what you can aspire to in your career path by looking at this data. Let us proceed to understand how readers can create a Python visualization for this data.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;Here is the result.
(We can’t use photos here, because we added 4 photos above and left one as a thumbnail. Do we have a chance to use a table like the following to demonstrate the result?)
| Range | Job title | Average salary (USD) |
| 1 | Data Science technology Leader | 375,000.00 |
| 2 | Cloud Data Architect | 250,000.00 |
| 3 | Data leader | 212,500.00 |
| 4 | Data Analysis Leader | 211,254.50 |
| 5 | Principal Data Scientist | 198,171.13 |
| 6 | Data Science Director | 195,140.73 |
| 7 | Principal Data Engineer | 192,500.00 |
| 8 | Machine Learning Software Engineer | 192,420.00 |
| 9 | Data science manager | 191,278.78 |
| 10 | Applied Scientist | 190,264.48 |
This time, let’s try to create a graph yourself.
Tips: You can use the following message in ChatGPT to generate Pythonic code for this graph:
<SQL Query here>
Create a Python graph to visualize the top 10 highest-paying job titles in Data Science, similar to the insights gathered from the given SQL query above.As we conclude our journey through the various terrains of the professional world of data science, we hope that SQL will prove to be a reliable guide that helps you uncover gems of knowledge that support your professional decisions.
I hope you now feel more prepared, not only to chart your career path, but also to use SQL to transform raw data into powerful narratives. So, here’s to taking a step into a future full of opportunities, with data as your compass and SQL as your guiding force!
Thank you for reading!
Nate Rosidi He is a data scientist and in product strategy. He is also an adjunct professor of analysis and is the founder of StrataScratch, a platform that helps data scientists prepare for their interviews with real questions from top companies. Connect with him on Twitter: StrataScratch either LinkedIn.






{kind=link}