
“Apple,” and immediately, the image of an apple popped right into your head. And as fascinating as it is how our brains work, Generative AI has ushered the same level of creativity and power, enabling machines to produce what we call original content. Lately, there have emerged impressive text-to-image models that create highly realistic images. You may feed “apple” into the model and obtain all kinds of images of apples.
However, making these models generate exactly what we want with just text prompts can be extremely challenging. It usually requires careful crafting of the right prompts. An alternative way to do this is to utilize picture prompts. While the current set of techniques for directly refining models from pre-existing ones is successful, they demand substantial computational power and lack compatibility with different base models, text prompts, and structural adjustments.
Recent advances in controllable image generation highlight concerns with the cross-attention modules of text-to-image diffusion models. These modules use weights tailored for projecting key and value data in the cross-attention layer of the pre-trained diffusion model, primarily optimized for text features. Consequently, merging image and text features in this layer mainly aligns image features with text features. However, this can disregard image-specific details, leading to broader control during generation (e.g., managing image style) when utilizing a reference image.
In the above image, we can notice that the examples on the right show the results of image variations, multimodal generation, and inpainting with image prompt, while the left examples show the results of controllable generation with image prompt and additional structural conditions.
Researchers have introduced an effective image prompt adapter called IP-Adapter to tackle challenges posed by current methods. IP-Adapter uses a separate approach to handle text and image features. In the UNet of the diffusion model, researchers have added an extra cross-attention layer specifically for image features. During training, the new cross-attention layer’s settings are adjusted, leaving the original UNet model unchanged. This adapter is efficient yet powerful: even with only 22 million parameters, an IP adapter can generate images as good as a fully fine-tuned image prompt model derived from the text-to-image diffusion model.
The findings have proved the IP-Adapter is reusable and flexible. IP-Adapter trained on the base diffusion model can be generalized to other custom models fine-tuned from the same base diffusion model. Moreover, the IP-Adapter is compatible with other controllable adapters such as ControlNet, allowing for an easy combination of image prompts with structure controls. Thanks to the separate cross-attention strategy, the image prompt can work alongside the text prompt, creating multimodal images.
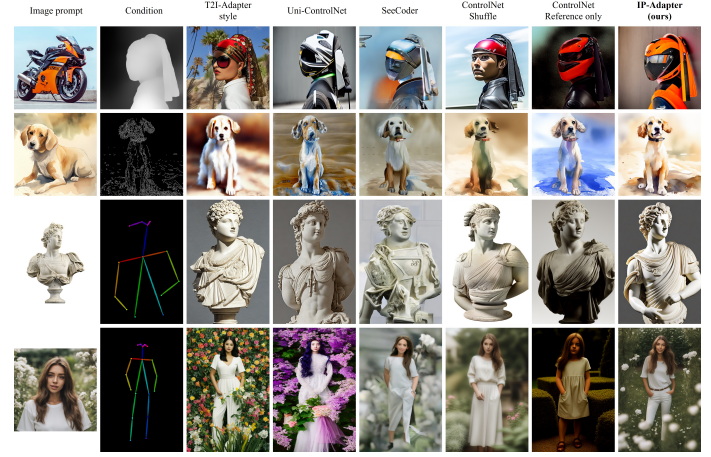
The above image demonstrates the comparison of the IP-Adapter with other methods on different structural conditions. Despite the effectiveness of the IP-Adapter, it can only generate images that resemble the reference images in content and style. In other words, it cannot synthesize images that are highly consistent with the subject of a given image like some existing methods, e.g., Textual Inversion and DreamBooth. In the future, researchers aim to develop more powerful image prompt adapters to enhance consistency.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
➡️ Hostinger AI Website Builder: User-Friendly Drag-and-Drop Editor. Try Now (Sponsored)
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.





{kind=link}