
AI language models are becoming an essential part of our lives. We’ve been using Google for decades to access information, but now we’re slowly switching to ChatGPT. It provides concise answers, clear explanations, and is generally quicker to find the information we’re looking for.
These models learn from the data we produce over the years. As a result, we transfer our biases to the AI models, and this is a topic of debate in the domain. One particular bias that has drawn attention is the gender bias in the distribution of pronouns, where models tend to prefer gender pronouns such as “he” or “she” depending on context.
Addressing this gender bias is crucial to ensuring a fair and inclusive language generation. For example, if the sentence begins “The CEO believes that…”, the model continues with heand if you replace the CEO with the nursethe next token becomes she. This example serves as an interesting case study for examining biases and exploring methods to mitigate them.
It turns out that context plays a crucial role in shaping these biases. by replacement CEO with a profession stereotypically associated with a different gender, we can actually change the observed bias. But here is the challenge: achieving consistent debiasing across all the different contexts where CEO appears is not an easy task. We want interventions that work reliably and predictably, regardless of the specific situation. After all, interpretability and control are key when it comes to understanding and improving linguistic models. Unfortunately, current Transformer models, while impressive performers, don’t meet these criteria. Its contextual representations introduce all kinds of complex and non-linear effects that depend on the context in question.
So how can we overcome these challenges? How can we address the bias we introduced into the large language models? Should we improve the transformers or should we come up with new structures? The answer is Knapsack language models.
LM backpack addresses the challenge of debiasing pronoun distributions by taking advantage of non-contextual representations known as sense vectors. These vectors capture different aspects of a word’s meaning and its role in various contexts, giving words multiple personalities.
In LM backpack, the predictions are log-linear combinations of non-contextual representations, called sense vectors. Each word in the vocabulary is represented by multiple meaning vectors, encoding different learned aspects of the word’s potential roles in different contexts.
These sense vectors are specialized and can be predictively useful in specific contexts. The weighted sum of sense vectors for words in a sequence forms the Backpack representation of each word, with the weights determined by a contextualization function that operates on the entire sequence. By harnessing these sensory vectors, Backpack Models enable precise interventions that behave predictably in all contexts.
This means that we can make non-contextual changes to the model that constantly influence its behavior. Compared with transformer models, Backpack Models offer a more transparent and manageable interface. They provide precise interventions that are easier to understand and control. Besides, Backpack the models do not compromise on performance either. In fact, they achieve results on par with Transformers while offering enhanced performance.
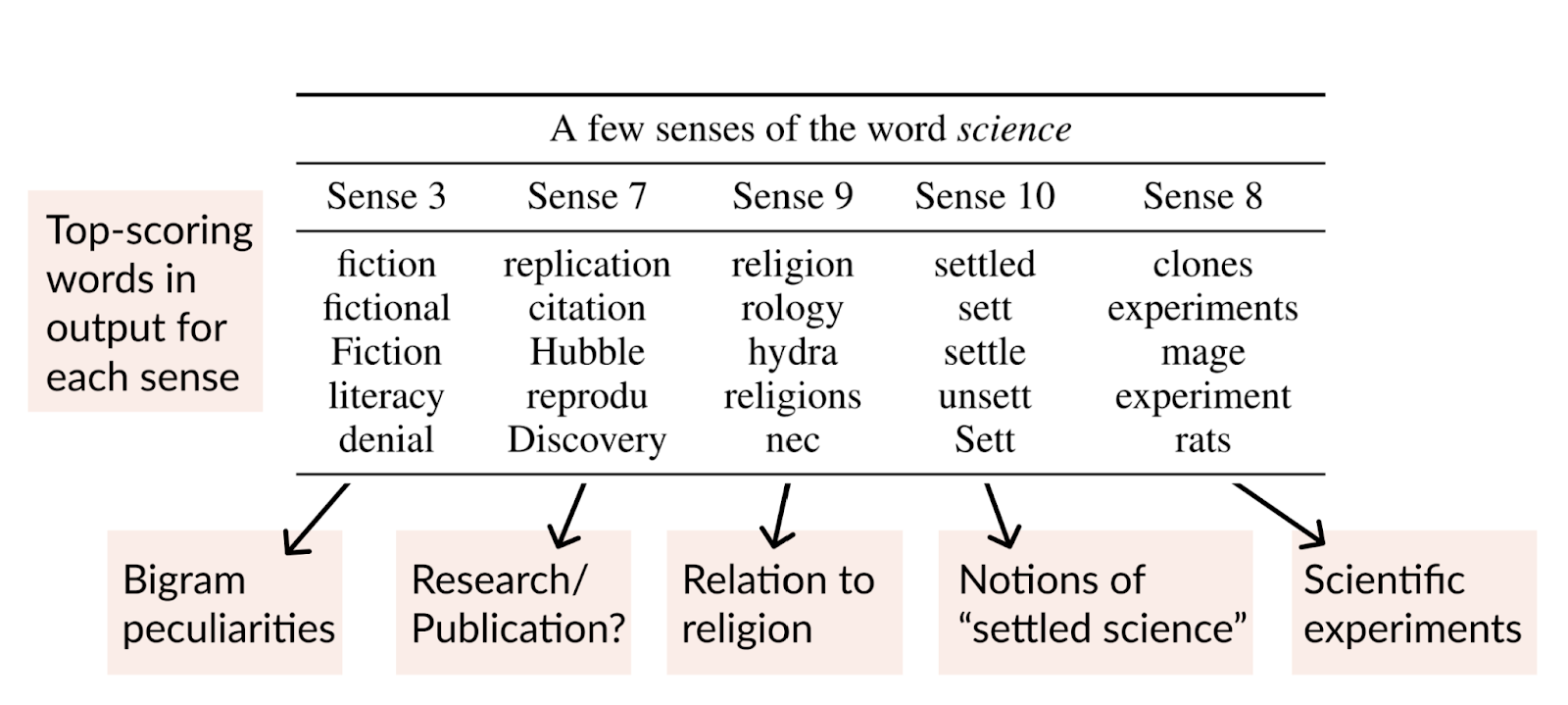
Direction of vectors in Backpack The models encode rich notions of word meaning, outperforming the word embeddings of state-of-the-art Transformer models in lexical similarity tasks. In addition, interventions on sensory vectors, such as the reduction of gender bias in professional words, demonstrate the control mechanism offered by Backpack models. By reducing the sense vector associated with gender bias, significant reductions in contextual prediction disparities can be achieved in constrained settings.
review the Paper and Project. Don’t forget to join our 24k+ ML SubReddit, discord channel, and electronic newsletter, where we share the latest AI research news, exciting AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us at [email protected]
featured tools Of AI Tools Club
🚀 Check out 100 AI tools at AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. She wrote her M.Sc. thesis on denoising images using deep convolutional networks. She received her Ph.D. He graduated in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Improvements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.






{kind=link}