 NEWSLETTER
NEWSLETTER
With the wide availability of pretraining data and computing resources, basic models in vision, language, and multimodality have become more common. They exhibit varied interactions, including human feedback, and exceptional generalization power in zero-shot environments. Segment Anything (SAM) builds a delicate data engine to collect 11 million image mask data, then trains a powerful segmentation base model known as SAM, inspired by the successes of huge language models. It starts by defining a new requestable segmentation paradigm, which inputs a constructed message and generates the lookahead mask. Any object in a visual environment can be segmented using SAM’s acceptable flag, which includes points, boxes, masks, and free-form words.
However, SAM cannot divide certain visual notions by nature. Imagine wanting to remove the clock from a picture in your bedroom or cut out your adorable pet dog from a photo album. Using the standard SAM model would require a lot of time and effort. You must find the target element in each image in various positions or situations before you activate SAM and give it specific instructions for segmentation. Therefore, they ask if they can quickly customize SAM to split distinctive graphical concepts. To do this, researchers from the Shanghai Artificial Intelligence Laboratory, CUHK MMLab, Tencent Youtu Lab, CFCS, School of CS, and Peking University suggest PerSAM, a customization strategy for the Segment Anything Model that requires no training. Using only data from a single shot, a user-supplied image, and a raw skin denoting personal concept, his technique effectively personalizes SAM.
They present three approaches to unlock the customization potential of the SAM decoder while the test image is being processed. To be more precise, they first encode the embedding of the target object in the reference image using SAM’s image encoder and the supplied mask. The feature similarity between the element and each pixel in the new test image is then calculated. The estimated feature similarity drives each layer of token-to-image cross-attention in the SAM decoder. Also, two points are chosen as the positive-negative pair and encoded as fast tokens to provide SAM with a location in advance.
As a result, for efficient interaction of features, request tokens are forced to focus primarily on front end destination areas.
• Focused and directed attention
• Target-specific incitement
• Post-refinement of Caledonia
They implement a two-step post-refinement technique to get results in sharper segmentation. They use SAM to gradually improve the skin produced. It only adds 100ms to the process.
As shown in Figure 2, PerSAM exhibits good custom segmentation performance for a single participant in a variety of positions or settings when using the above designs. However, there can occasionally be failure scenarios where the subject has hierarchical structures that need to be segmented, such as the top of a container, the head of a toy robot, or the lid of a teddy bear.
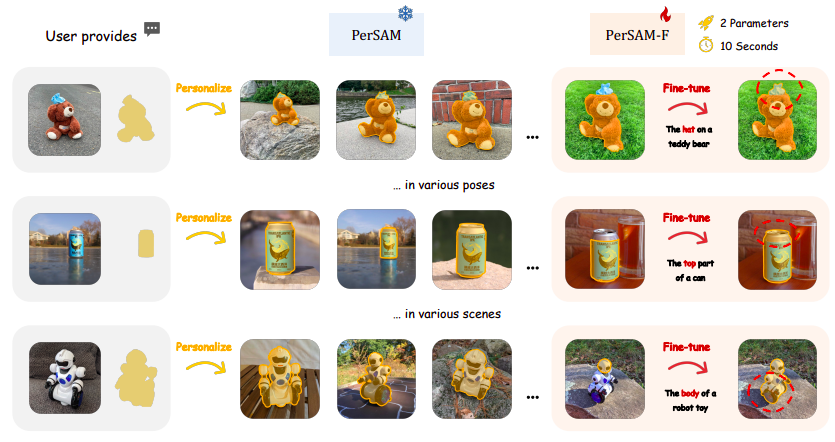
Since SAM can accept both the local component and the global shape as acceptable pixel-level masks, this uncertainty makes it difficult for PerSAM to choose the correct size for the segmentation output. To facilitate this, they also present PerSAM-F, a fine-tuning variation of their methodology. They adjust two parameters in 10 seconds while freezing the entire SAM to maintain their pre-trained knowledge. Specifically, they allow SAM to provide numerous segmentation results with various mask scales. They use learnable relative weights for each scale and a weighted sum as the final mask output to adaptively choose the optimal scale for different elements.
As can be seen in Figure 2 (right), PerSAM-T shows improved targeting accuracy thanks to this effective one-shot training. The ambiguity problem can be effectively controlled by weighting multi-scale masks instead of quick fits or adapters. They also point out that their method may allow DreamBooth to better tune stable diffusion for custom text-to-image output. DreamBooth and its associated works take a small set of photos that have a particular visual notion, like your favorite cat, and turn them into an identifier in the word embedding space that is then used to represent the target element in the sentence. However, the identifier includes visual details about the backgrounds of the provided photos, such as stairs.
This would override the new backgrounds in the generated images and disturb the learning of the target object representation. Therefore, they propose to leverage their PerSAM to segment the target object efficiently and only monitor for stable diffusion by the foreground area in the few shot images, allowing for a more diverse and higher fidelity synthesis. They summarize the contributions of their article as follows:
• Custom Segmentation Task. From a new point of view, they investigate how to customize the basic segmentation models in custom scenarios with minimal expense, that is, from general purpose to private.
• Efficient SAM Adaptation. They investigate for the first time how to modify SAM for downstream applications simply by adjusting two parameters and present two simple solutions: PerSAM and PerSAM-F.
• Personalization Assessment. They add annotations to PerSeg, a new segmentation dataset that contains numerous categories under various circumstances. Furthermore, they test their strategy using effective video object segmentation.
• Improved stable broadcast customization. Segmentation of the target element in photos with few shots reduces background noise and improves DreamBooth’s ability to generate personalized content.
review the Paper and Code. Don’t forget to join our 21k+ ML SubReddit, discord channel, and electronic newsletter, where we share the latest AI research news, exciting AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us at asif@marktechpost.com
 Check out 100 AI tools at AI Tools Club
Check out 100 AI tools at AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. She is currently pursuing her bachelor’s degree in Information Science and Artificial Intelligence at the Indian Institute of Technology (IIT), Bhilai. She spends most of her time working on projects aimed at harnessing the power of machine learning. Her research interest is image processing and she is passionate about creating solutions around her. She loves connecting with people and collaborating on interesting projects.






{kind=link}