
Con la llegada de las redes móviles 5G de alta velocidad, las empresas se posicionan más fácilmente que nunca con la oportunidad de aprovechar la convergencia de las redes de telecomunicaciones y la nube. Como uno de los casos de uso más destacados hasta la fecha, el aprendizaje automático (ML) en el perímetro ha permitido a las empresas implementar modelos de ML más cerca de sus clientes finales para reducir la latencia y aumentar la capacidad de respuesta de sus aplicaciones. Como ejemplo, soluciones inteligentes para lugares puede utilizar la visión por computadora casi en tiempo real para el análisis de multitudes en redes 5G, al mismo tiempo que minimiza la inversión en equipos de red de hardware en las instalaciones. Los minoristas pueden ofrecer experiencias más fluidas sobre la marcha con el procesamiento del lenguaje natural (NLP), los sistemas de recomendación en tiempo real y la detección de fraudes. Incluso robótica terrestre y aérea puede usar ML para desbloquear operaciones más seguras y autónomas.
Para reducir la barrera de entrada de ML en el borde, queríamos demostrar un ejemplo de implementación de un modelo previamente entrenado de Amazon SageMaker a AWS Wavelength, todo en menos de 100 líneas de código. En esta publicación, demostramos cómo implementar un modelo de SageMaker en AWS Wavelength para reducir la latencia de inferencia del modelo para aplicaciones basadas en redes 5G.
Descripción general de la solución
A través de la infraestructura global en rápida expansión de AWS, AWS Wavelength lleva el poder de la computación y el almacenamiento en la nube al borde de las redes 5G, desbloqueando experiencias móviles de mayor rendimiento. Con AWS Wavelength, puede extender su nube virtual privada (VPC) a las zonas de Wavelength correspondientes al borde de la red del operador de telecomunicaciones en 29 ciudades de todo el mundo. El siguiente diagrama muestra un ejemplo de esta arquitectura.
Puede optar por las zonas de longitud de onda dentro de una región determinada a través de la consola de administración de AWS o la interfaz de línea de comandos de AWS (AWS CLI). Para obtener más información sobre la implementación de aplicaciones distribuidas geográficamente en AWS Wavelength, consulte Implementación de clústeres de Amazon EKS distribuidos geográficamente en AWS Wavelength.
Sobre la base de los fundamentos discutidos en esta publicación, consideramos ML en el perímetro como una carga de trabajo de muestra con la que implementar en AWS Wavelength. Como nuestra carga de trabajo de muestra, implementamos un modelo previamente entrenado de Amazon SageMaker JumpStart.
SageMaker es un servicio de aprendizaje automático completamente administrado que permite a los desarrolladores implementar fácilmente modelos de aprendizaje automático en sus entornos de AWS. Aunque AWS ofrece una serie de opciones para el entrenamiento de modelos, desde modelos de AWS Marketplace y algoritmos integrados de SageMaker, existen varias técnicas para implementar modelos de aprendizaje automático de código abierto.
JumpStart brinda acceso a cientos de algoritmos integrados con modelos previamente entrenados que se pueden implementar sin problemas en los puntos finales de SageMaker. Desde el mantenimiento predictivo y la visión por computadora hasta la conducción autónoma y la detección de fraudes, JumpStart es compatible con una variedad de casos de uso populares con implementación con un solo clic en la consola.
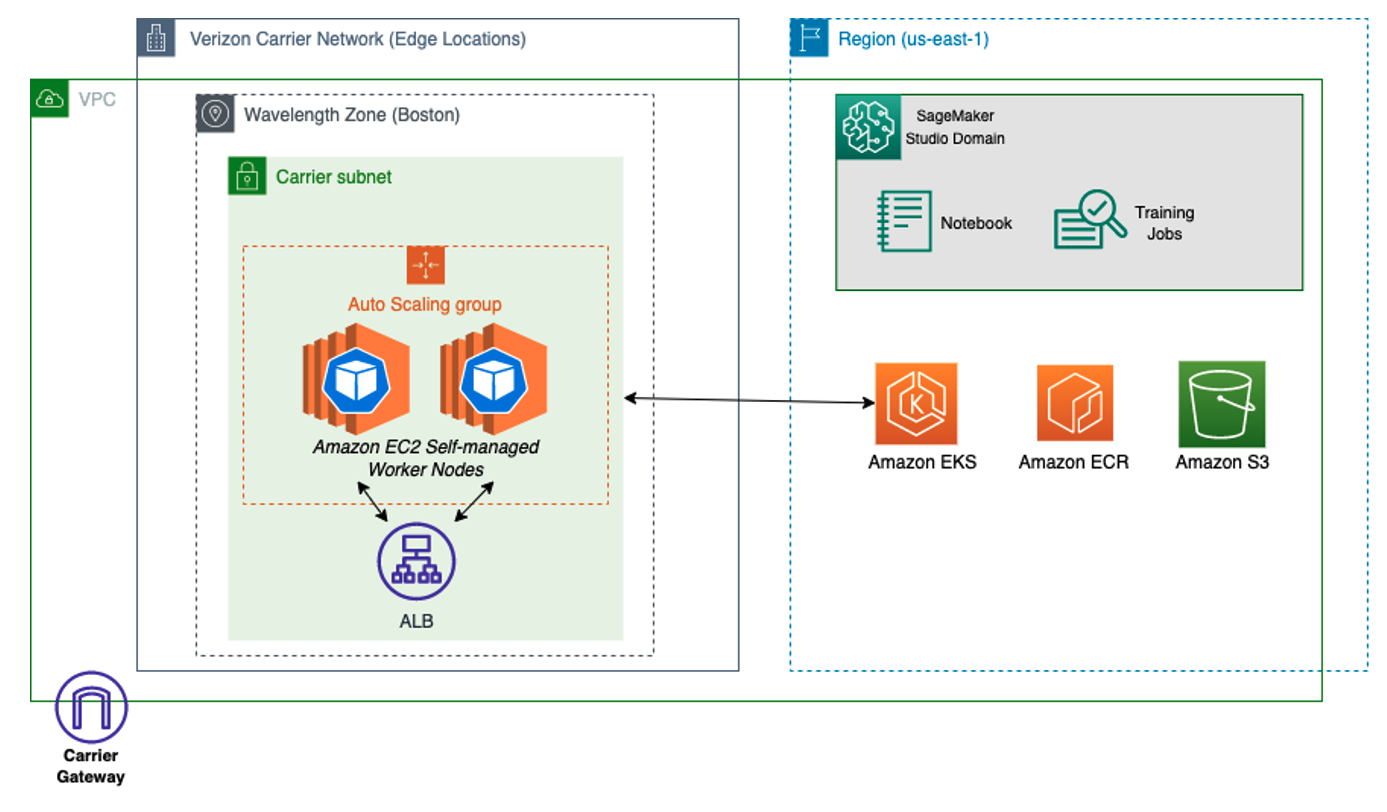
Debido a que SageMaker no se admite de forma nativa en las zonas de longitud de onda, demostramos cómo extraer los artefactos del modelo de la región y volver a implementarlos en el perímetro. Para hacerlo, utilice clústeres y grupos de nodos de Amazon Elastic Kubernetes Service (Amazon EKS) en Wavelength Zones, y luego cree un manifiesto de implementación con la imagen del contenedor generada por JumpStart. El siguiente diagrama ilustra esta arquitectura.
requisitos previos
Para que esto sea lo más fácil posible, asegúrese de que su cuenta de AWS tenga habilitadas las zonas de longitud de onda. Tenga en cuenta que esta integración solo está disponible en us-east-1 y us-west-2y estarás usando us-east-1 durante la duración de la demostración.
Para optar por AWS Wavelength, complete los siguientes pasos:
- En la consola de Amazon VPC, elija Zonas bajo Ajustes y elige Este de EE. UU. (Verizon) / us-east-1-wl1.
- Elegir Administrar.
- Seleccionar Optado en.
- Elegir Actualizar zonas.
Crear infraestructura de longitud de onda de AWS
Antes de convertir el extremo de inferencia del modelo local de SageMaker en una implementación de Kubernetes, puede crear un clúster de EKS en una zona de longitud de onda. Para hacerlo, implemente un clúster de Amazon EKS con un grupo de nodos de AWS Wavelength. Para obtener más información, puede visitar esta guía en el blog de contenedores de AWS o Repositorio 5GEdgeTutorials de Verizon para uno de esos ejemplos.
A continuación, utilizando un entorno de AWS Cloud9 o un entorno de desarrollo interactivo (IDE) de su elección, descargue los paquetes de SageMaker necesarios y Componer ventana acoplableuna dependencia clave de JumpStart.
Cree artefactos de modelos usando JumpStart
Primero, asegúrese de tener un rol de ejecución de AWS Identity and Access Management (IAM) para SageMaker. Para obtener más información, visite Roles de SageMaker.
- Usando este ejemplocree un archivo llamado train_model.py que use el kit de desarrollo de software (SDK) de SageMaker para recuperar un modelo preconstruido (reemplace con el nombre de recurso de Amazon (ARN) de su función de ejecución de SageMaker). En este archivo, implementa un modelo localmente usando el
instance_typeatributo en elmodel.deploy()función, que inicia un contenedor Docker dentro de su IDE utilizando todos los artefactos de modelo necesarios que definió:
- A continuación, establezca
infer_model_idal ID del modelo de SageMaker que le gustaría usar.
Para obtener una lista completa, consulte Algoritmos integrados con tabla de modelo preentrenada. En nuestro ejemplo, usamos el modelo de representaciones de codificador bidireccional de transformadores (BERT), comúnmente utilizado para el procesamiento de lenguaje natural.
- ejecutar el
train_model.pysecuencia de comandos para recuperar los artefactos del modelo JumpStart e implementar el modelo previamente entrenado en su máquina local:
Si este paso tiene éxito, su salida puede parecerse a la siguiente:
En el resultado, verá tres artefactos en orden: la imagen base para la inferencia de TensorFlow, el script de inferencia que sirve al modelo y los artefactos que contienen el modelo entrenado. Aunque podría crear una imagen de Docker personalizada con estos artefactos, otro enfoque es dejar que el modo local de SageMaker cree la imagen de Docker por usted. En los pasos posteriores, extraemos la imagen del contenedor que se ejecuta localmente y la implementamos en Amazon Elastic Container Registry (Amazon ECR), además de enviar el artefacto del modelo por separado a Amazon Simple Storage Service (Amazon S3).
Convierta artefactos de modo local en implementación remota de Kubernetes
Ahora que ha confirmado que SageMaker funciona localmente, extraigamos el manifiesto de implementación del contenedor en ejecución. Complete los siguientes pasos:
Identifique la ubicación del manifiesto de implementación del modo local de SageMaker: para hacerlo, busque en nuestro directorio raíz cualquier archivo llamado docker-compose.yaml.
docker_manifest=$( find /tmp/tmp* -name "docker-compose.yaml" -printf '%T+ %p\n' | sort | tail -n 1 | cut -d' ' -f2-)
echo $docker_manifestIdentifique la ubicación de los artefactos del modelo de modo local de SageMaker: luego, busque el volumen subyacente montado en el contenedor de inferencia local de SageMaker, que se usará en cada nodo trabajador de EKS después de cargar el artefacto en Amazon s3.
model_local_volume = $(grep -A1 -w "volumes:" $docker_manifest | tail -n 1 | tr -d ' ' | awk -F: '{print $1}' | cut -c 2-)
# Returns something like: /tmp/tmpcr4bu_a7</p>Cree una copia local del contenedor de inferencia de SageMaker en ejecución: a continuación, buscaremos la imagen del contenedor que se está ejecutando actualmente y que ejecuta nuestro modelo de inferencia de aprendizaje automático y haremos una copia del contenedor localmente. Esto asegurará que tengamos nuestra propia copia de la imagen del contenedor para extraer de Amazon ECR.
# Find container ID of running SageMaker Local container
mkdir sagemaker-container
container_id=$(docker ps --format "{{.ID}} {{.Image}}" | grep "tensorflow" | awk '{print $1}')
# Retrieve the files of the container locally
docker cp $my_container_id:/ sagemaker-container/Antes de actuar sobre el model_local_volumeque enviaremos a Amazon S3, envíe una copia de la imagen de Docker en ejecución, ahora en el sagemaker-container directorio, a Amazon Elastic Container Registry. Asegúrese de reemplazar region, aws_account_id, docker_image_id y my-repository:tag o siga la guía del usuario de Amazon ECR. Además, asegúrese de tomar nota de la URL final de la imagen de ECR (aws_account_id.dkr.ecr.region.amazonaws.com/my-repository:tag), que usaremos en nuestra implementación de EKS.
Ahora que tenemos una imagen de ECR correspondiente al punto final de inferencia, cree un nuevo depósito de Amazon S3 y copie los artefactos de SageMaker Local (model_local_volume) a este cubo. Paralelamente, cree una administración de acceso a la identidad (IAM) que proporcione a las instancias de Amazon EC2 acceso para leer objetos dentro del depósito. Asegúrese de reemplazar con un nombre único a nivel mundial para su depósito de Amazon S3.
A continuación, para asegurarse de que cada instancia de EC2 obtenga una copia del artefacto del modelo en el lanzamiento, edite los datos de usuario para sus nodos de trabajo de EKS. En su secuencia de comandos de datos de usuario, asegúrese de que cada nodo recupere los artefactos del modelo mediante la API de S3 en el momento del lanzamiento. Asegúrese de reemplazar con un nombre único a nivel mundial para su depósito de Amazon S3. Dado que los datos de usuario del nodo también incluirán el script de arranque de EKS, los datos de usuario completos pueden verse así.
Ahora, puede inspeccionar el manifiesto de la ventana acoplable existente y traducirlo a archivos de manifiesto compatibles con Kubernetes usando Componer, una conocida herramienta de conversión. Nota: si obtiene un error de compatibilidad de versión, cambie el version atributo en la línea 27 de docker-compose.yml para “2”.
Después de ejecutar Kompose, verá cuatro archivos nuevos: un Deployment objeto, Service objeto, PersistentVolumeClaim objeto, y NetworkPolicy objeto. ¡Ahora tiene todo lo que necesita para comenzar su incursión en Kubernetes en el perímetro!
Implementar artefactos de modelo de SageMaker
Asegúrese de haber descargado kubectl y aws-iam-authenticator en su IDE de AWS Cloud9. Si no, siga las guías de instalación:
Ahora, completa los siguientes pasos:
Modificar el service/algo-1-ow3nv objeto para cambiar el tipo de servicio de ClusterIP a NodePort. En nuestro ejemplo, hemos seleccionado el puerto 30.007 como nuestro NodePort:
A continuación, debe permitir NodePort en el grupo de seguridad de su nodo. Para hacerlo, recupere el ID de grupo de seguridad y coloque en la lista de permitidos el NodePort:
A continuación, modifique la algo-1-ow3nv-deployment.yaml manifiesto para montar el /tmp/model hostPath directorio al contenedor. Reemplazar con la imagen ECR que creó anteriormente:
Con los archivos de manifiesto que creó desde Kompose, use kubectl para aplicar las configuraciones a su clúster:
Conéctese al modelo de borde 5G
Para conectarse a su modelo, complete los siguientes pasos:
En la consola de Amazon EC2, recupere la IP del operador del nodo de trabajo de EKS o use la CLI de AWS para consultar la dirección IP del operador directamente:
Ahora, con la dirección IP del operador extraída, puede conectarse al modelo directamente usando NodePort. Crea un archivo llamado invoke.py para invocar el modelo BERT directamente al proporcionar una entrada basada en texto que se ejecutará en un analizador de sentimientos para determinar si el tono fue positivo o negativo:
Su salida debe parecerse a lo siguiente:
Limpiar
Para destruir todos los recursos de aplicaciones creados, elimine los nodos trabajadores de AWS Wavelength, el plano de control de EKS y todos los recursos creados dentro de la VPC. Además, elimine el repositorio de ECR utilizado para alojar la imagen del contenedor, los cubos de S3 utilizados para alojar los artefactos del modelo de SageMaker y el sagemaker-demo-app-s3 IAM política.
Conclusión
En esta publicación, demostramos un enfoque novedoso para implementar modelos de SageMaker en el perímetro de la red mediante Amazon EKS y AWS Wavelength. Para conocer las mejores prácticas de Amazon EKS en AWS Wavelength, consulte Implementación de clústeres de Amazon EKS distribuidos geográficamente en AWS Wavelength. Además, para obtener más información sobre Jumpstart, visite la Guía para desarrolladores de Amazon SageMaker JumpStart o la Tabla de modelos disponibles de JumpStart.
Sobre los autores
 Roberto Belson es Developer Advocate en la unidad de negocios mundial de telecomunicaciones de AWS, y se especializa en AWS Edge Computing. Se enfoca en trabajar con la comunidad de desarrolladores y clientes de grandes empresas para resolver sus desafíos comerciales mediante la automatización, las redes híbridas y la nube perimetral.
Roberto Belson es Developer Advocate en la unidad de negocios mundial de telecomunicaciones de AWS, y se especializa en AWS Edge Computing. Se enfoca en trabajar con la comunidad de desarrolladores y clientes de grandes empresas para resolver sus desafíos comerciales mediante la automatización, las redes híbridas y la nube perimetral.
 Mohamed Al-Mehdar es Arquitecto de Soluciones Sénior en la Unidad de Negocios de Telecomunicaciones Mundiales en AWS. Su objetivo principal es ayudar a los clientes a crear e implementar cargas de trabajo de TI empresarial y de telecomunicaciones en AWS. Antes de unirse a AWS, Mohammed trabajó en la industria de las telecomunicaciones durante más de 13 años y aporta una gran experiencia en las áreas de LTE Packet Core, 5G, IMS y WebRTC. Mohammed tiene una licenciatura en Ingeniería de Telecomunicaciones de la Universidad de Concordia.
Mohamed Al-Mehdar es Arquitecto de Soluciones Sénior en la Unidad de Negocios de Telecomunicaciones Mundiales en AWS. Su objetivo principal es ayudar a los clientes a crear e implementar cargas de trabajo de TI empresarial y de telecomunicaciones en AWS. Antes de unirse a AWS, Mohammed trabajó en la industria de las telecomunicaciones durante más de 13 años y aporta una gran experiencia en las áreas de LTE Packet Core, 5G, IMS y WebRTC. Mohammed tiene una licenciatura en Ingeniería de Telecomunicaciones de la Universidad de Concordia.
 Evan Kravitz es ingeniero de software en Amazon Web Services y trabaja en SageMaker JumpStart. Le gusta cocinar y salir a correr en la ciudad de Nueva York.
Evan Kravitz es ingeniero de software en Amazon Web Services y trabaja en SageMaker JumpStart. Le gusta cocinar y salir a correr en la ciudad de Nueva York.
 Justin San Arnauld es Director Asociado – Arquitectos de Soluciones en Verizon para el Sector Público con más de 15 años de experiencia en la industria de TI. Es un apasionado defensor del poder de la informática perimetral y las redes 5G y es un experto en el desarrollo de soluciones tecnológicas innovadoras que aprovechan estas tecnologías. Justin está particularmente entusiasmado con las capacidades que ofrece Amazon Web Services (AWS) en la entrega de soluciones de vanguardia para sus clientes. En su tiempo libre, a Justin le gusta mantenerse actualizado con las últimas tendencias tecnológicas y compartir sus conocimientos y puntos de vista con otros en la industria.
Justin San Arnauld es Director Asociado – Arquitectos de Soluciones en Verizon para el Sector Público con más de 15 años de experiencia en la industria de TI. Es un apasionado defensor del poder de la informática perimetral y las redes 5G y es un experto en el desarrollo de soluciones tecnológicas innovadoras que aprovechan estas tecnologías. Justin está particularmente entusiasmado con las capacidades que ofrece Amazon Web Services (AWS) en la entrega de soluciones de vanguardia para sus clientes. En su tiempo libre, a Justin le gusta mantenerse actualizado con las últimas tendencias tecnológicas y compartir sus conocimientos y puntos de vista con otros en la industria.






{kind=link}