
Virtual assistants are increasingly integrated into our daily routines. They can help with everything from setting alarms to giving directions on a map and can even help people with disabilities manage their homes more easily. As we use these wizards, we also become more accustomed to using natural language to accomplish tasks we previously did by hand.
One of the biggest challenges in building a robust virtual assistant is identifying what a user wants and what information is needed to perform the task at hand. In the natural language processing (NLP) literature, this is mostly framed as a task-oriented dialogue analysis task, where a given dialog must be parsed by a system to understand the user’s intent and perform the operation to fulfill that intent. While the academic community has made progress in handling task-oriented dialog thanks to custom-purpose data sets, such as MultiWOZ, ABOVE, SMCalFlow, etc., progress is limited because these data sets lack the typical speech phenomena needed for model training to optimize language model performance. The resulting models often underperform, leading to dissatisfaction with attendee interactions. Relevant speech patterns may include reviews, fluency, code mixing, and the use of structured context surrounding the user’s environment, which may include the user’s notes, smart home devices, contact lists, etc.
Consider the following dialog that illustrates a common instance when a user needs to review their expression:
 |
| A dialog conversation with a virtual assistant that includes a user review. |
The virtual assistant misinterprets the request and tries to call the wrong contact. Therefore, the user has to check his pronunciation to correct the wizard error. To correctly parse the last expression, the helper would also need to interpret the user’s special context; in this case, you would need to know that the user had a contact list saved on their phone that you should refer to.
Another common category of utterance that is a challenge for virtual assistants is code mixing, which occurs when the user switches from one language to another while speaking to the assistant. Consider the following statement:
 |
| A dialogue denoting a code mix between English and German. |
In this example, the user switches from English to German, where “Four o’clock” half “Four o’clock” in German.
In an effort to advance research in the analysis of such realistic and complex expressions, we are release of a new data set called PRESTO, a multilingual dataset for analyzing realistic task-oriented dialogues that includes approximately half a million realistic conversations between people and virtual assistants. The data set spans six different languages and includes multiple conversational phenomena users may encounter when using an assistant, including user reviews, fluency, and code mixing. The data set also includes the surrounding structured context, such as user contacts and lists associated with each instance. Explicit labeling of various phenomena in PRESTO allows us to create different test sets to separately analyze the model’s performance on these speech phenomena. We find that some of these phenomena are easier to model with few shot examples, while others require much more training data.
Data set characteristics
- Conversations by native speakers in six languages
All conversations in our dataset are provided by native speakers of six languages: English, French, German, Hindi, Japanese, and Spanish. This is in contrast to other data sets, such as MTOP and MASSIVEthat translate expressions only from English into other languages, which does not necessarily reflect the speech patterns of native speakers in languages other than English. - structured context
Users often rely on information stored on their devices, such as notes, contacts, and lists, when interacting with virtual assistants. However, this context is often not accessible to the wizard, which can lead to parse errors when processing user utterances. To address this issue, PRESTO includes three types of structured context, notes, lists, and contacts, as well as user statements and their analyses. Lists, notes, and contacts are created by native speakers of each language during data collection. Having such context allows us to examine how this information can be used to improve performance in parsing task-oriented dialog models.
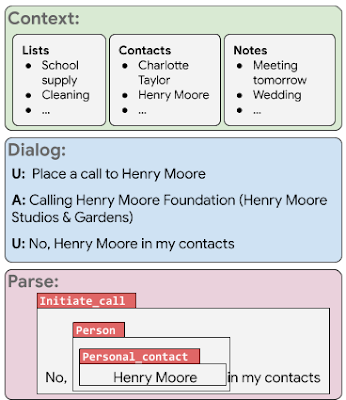
Each example in PRESTO consists of: Tickets — The virtual state of a user (context), one or more user utterances, and the corresponding responses from the virtual assistant (dialog). Production — Semantic analysis of the last user expression in the dialog (parse). - user reviews
It is common for a user to review or correct their own statements while talking to a virtual assistant. These revisions happen for a variety of reasons: the wizard might have made a mistake in understanding the utterance, or the user might have changed their mind when issuing a utterance. An example of this is in the figure above. Other examples of revisions include cancellation of the application (”Don’t add anything.”) or be corrected in the same statement (“Add bread, no, don’t wait, add wheat bread to my shopping list.”). Approximately 27% of all examples in PRESTO have some form of user revision that is explicitly tagged in the dataset. - code mix
As of 2022, about 43% of the world’s population is bilingual. As a result, many users switch languages while talking to virtual assistants. In the PRESTO construction, we asked bilingual data contributors to score mixed code utterances, which amounted to approximately 14% of all utterances in the data set.

Examples of PRESTO Hindi-English, Spanish-English and German-English Switched Code Statements. - disfluencies
Fluency issues, such as repeated phrases or filler words, are ubiquitous in users’ utterances due to the spoken nature of the conversations virtual assistants receive. Data sets like DISFL-QA be aware of the lack of such phenomena in the existing NLP literature and contribute to the goal of alleviating that gap. In our work, we include conversations about this particular phenomenon in all six languages.

Examples of expressions in English, Japanese and French with filler words or repetitions.



key results
We conducted specific experiments to focus on each of the phenomena described above. We ran based on mT5 models trained using the PRESTO dataset and evaluated using an exact match between the predicted analysis and the human annotated analysis. Below, we show the relative performance improvements as we scale the training data across each of the target phenomena: user reviews, lack of fluency, and code mixing.
 |
| K-shot results in various linguistic phenomena and the full set of tests through increasing the size of the training data. |
He whatThe results of the shots yield the following conclusions:
- Zero-shot performance on the marked phenomenon is poor, emphasizing the need for such expressions in the data set to improve performance.
- Mismatches and code combination have much better zero shot performance than user reviews (more than 40 point difference in exact match accuracy).
We also investigated the difference between training monolingual and multilingual models on the train set and found that with less data, multilingual models have an advantage over monolingual models, but the gap narrows as data size increases.

Additional details on data quality, data collection methodology, and modeling experiments can be found in our paper.
Conclusion
We created PRESTO, a multilingual dataset for analyzing task-oriented dialogues that includes realistic conversations that represent a variety of pain points that users often face in their daily conversations with virtual assistants that are lacking in existing datasets in the NLP community. . PRESTO includes approximately half a million utterances contributed by native speakers of six languages: English, French, German, Hindi, Japanese, and Spanish. We create dedicated test suites to focus on each target phenomenon: user reviews, lack of fluency, code mixing, and structured context. Our results indicate that zero-trigger performance is poor when the target phenomenon is not included in the training set, indicating the need for such expressions to improve performance. We noticed that user reviews and disfluencies are easier to model with more data compared to mixed code expressions, which are more difficult to model, even with a large number of examples. With the release of this dataset, we are opening more questions than we are answering, and we hope the research community will progress statements that are more in line with what users face every day.
Thanks
It was a privilege to collaborate on this work with Waleed Ammar, Siddharth Vashishtha, Motoki Sano, Faiz Surani, Max Chang, HyunJeong Choe, David Greene, Kyle He, Rattima Nitisaroj, Anna Trukhina, Shachi Paul, Pararth Shah, Rushin Shah, and Zhou Yu. We would also like to thank Tom Small for the animations in this blog post. Finally, many thanks to all the expert linguists and data annotators for making this happen.






{kind=link}