
Long Language Models (LLM) are computer models capable of parsing and generating text. They are trained on a large amount of textual data to improve their performance in tasks such as text generation and even coding.
Most LLMs today are text-only, meaning they excel only at text-based applications and have limited ability to understand other types of data.
Examples of text-only LLMs include GPT-3, BERT, Robertaetc
By contrast, multimodal LLMs combine other types of data, such as images, videos, audio, and other sensory input, along with text. Integrating multimodality into LLMs addresses some of the limitations of current text-only models and opens up possibilities for new applications that were previously impossible.
🔥 Best Image Annotation Tools in 2023
The recently launched GPT-4 by Open AI is an example of a multimodal LLM. It can accept image and text input and has demonstrated human-level performance in numerous benchmarks.
Rise of multimodal AI
The advancement of multimodal AI can be attributed to two crucial machine learning techniques: representation learning and transfer learning.
With representation learningmodels can develop a shared representation for all modalities, while transfer learning it allows them to first learn fundamental knowledge before refining it in specific domains.
These techniques are essential to making multimodal AI feasible and effective, as evidenced by recent advances such as CLIP, which aligns images and text, and DALL E 2 and Stable Diffusion, which generate high-quality images from text cues. .
As the boundaries between different data modalities become less clear, we can expect more AI applications to take advantage of the relationships between multiple modalities, marking a paradigm shift in the field. Ad-hoc approaches will gradually become obsolete, and the importance of understanding the connections between various modalities will continue to grow.
Operation of multimodal LLMs
Text-only language models (LLMs) work with the transformer model, which helps them understand and generate language. This model takes the input text and converts it into a numerical representation called “word embedding”. These embeds help the model understand the meaning and context of the text.
The transformer model then uses something called “attention layers” to process the text and determine how different words in the input text relate to each other. This information helps the model predict the next most likely word in the output.
On the other hand, multimodal LLMs work not only with text but also with other forms of data such as images, audio, and video. These models convert text and other types of data into a common encoding space, which means they can process all kinds of data using the same mechanism. This allows models to generate responses incorporating information from multiple modalities, leading to more accurate and contextual results.
Why is there a need for multimodal language models?
Text-only LLMs like GPT-3 and BERT have a wide range of applications, including writing articles, composing emails, and coding. However, this text-only approach has also highlighted the limitations of these models.
Although language is a crucial part of human intelligence, it only represents one facet of our intelligence. Our cognitive abilities are highly dependent on unconscious perception and abilities, largely shaped by our past experiences and understanding of how the world works.
Text-only trained LLMs have an inherently limited ability to incorporate common sense and knowledge of the world, which can be problematic for certain tasks. Expanding the training data set can help to some extent, but these models can still find unexpected gaps in your knowledge. Multimodal approaches can address some of these challenges.
To better understand this, consider the example of ChatGPT and GPT-4.
Although ChatGPT is a remarkable language model that has proven to be incredibly useful in many contexts, it has some limitations in areas like complex reasoning.
To address this, the next iteration of GPT, GPT-4, is expected to surpass the reasoning capabilities of ChatGPT. By using more advanced algorithms and incorporating multimodality, GPT-4 is poised to take natural language processing to the next level, enabling you to tackle more complex reasoning problems and further improving your ability to generate similar responses. the human ones
Open AI: GPT-4
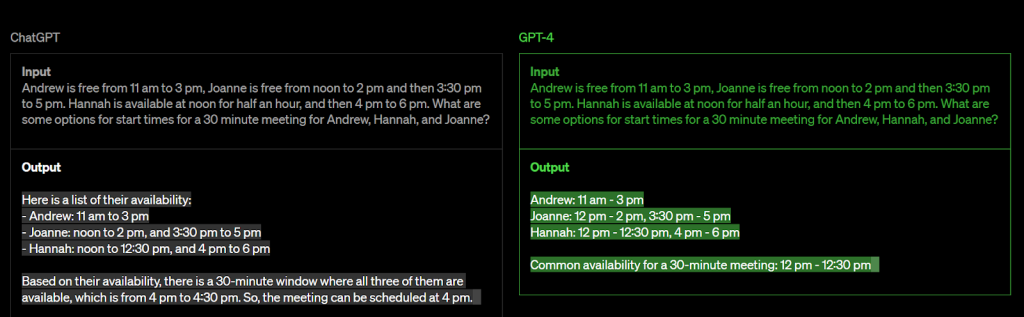
GPT-4 is a large, multimodal model that can accept image and text input and generate text output. Although it may not be as capable as humans in certain real-world situations, GPT-4 has demonstrated human-level performance in numerous academic and professional benchmarks.
Compared to its predecessor, GPT-3.5, the distinction between the two models may be subtle in casual conversation, but it becomes apparent when the complexity of a task reaches a certain threshold. GPT-4 is more reliable and creative, and can handle more nuanced instructions than GPT-3.5.
Additionally, it can handle prompts involving text and images, allowing users to specify any vision or language task. GPT-4 has proven its capabilities in various domains, including documents containing text, photographs, diagrams, or screenshots, and can output text as natural language and code.
khan academy recently announced that it will use GPT-4 to power its AI assistant khanmigo, who will act as a virtual tutor for students and as a classroom assistant for teachers. Each student’s ability to grasp concepts varies significantly, and the use of GPT-4 will help the organization address this issue.
Microsoft: Kosmos-1
Kosmos-1 is a multimodal large language model (MLLM) that can perceive different modalities, learn in context (few takes), and follow instructions (zero takes). Kosmos-1 has been trained from the ground up on web data, including text and images, image and caption pairs, and text data.
The model achieved impressive performance on the tasks of comprehension, generation, perception-language, and vision-language. Kosmos-1 natively supports language, perception-language, and vision activities, and can handle natural language and perception-intensive tasks.
Kosmos-1 has shown that multimodality allows large language models to achieve more with less and allows smaller models to solve complicated tasks.
Google: Palm-E
PaLM-E is a new robotics model developed by researchers at Google and TU Berlin that uses knowledge transfer from various visual and linguistic domains to enhance robot learning. Unlike previous efforts, PaLM-E trains the language model to incorporate raw sensor data from the robotic agent directly. This results in a highly effective robot learning model, a state-of-the-art general purpose visual language model.
The model takes inputs with different types of information, such as text, images, and an understanding of the robot’s environment. It can produce responses in the form of plain text or a series of textual instructions that can be translated into executable commands for a robot based on a variety of types of input information, including text, images, and environmental data.
PaLM-E demonstrates proficiency in both embedded and non-embedded tasks, as evidenced by experiments conducted by the researchers. Their findings indicate that training the model on a combination of tasks and performances improves its performance on each task. Furthermore, the model’s ability to transfer knowledge allows it to solve robotic tasks even with limited training examples effectively. This is especially important in robotics, where getting adequate training data can be challenging.
Limitations of Multimodal LLMs
Human beings naturally learn and combine different modalities and ways of understanding the world around them. On the other hand, multimodal LLMs attempt to simultaneously learn language and perception or combine previously trained components. While this approach can lead to faster development and improved scalability, it can also lead to incompatibilities with human intelligence, which can manifest through strange or unusual behavior.
Although multimodal LLMs are making progress in addressing some critical issues of modern language models and deep learning systems, there are still limitations to address. These limitations include potential mismatches between the models and human intelligence, which could impede their ability to bridge the gap between AI and human cognition.
Conclusion: Why are multimodal LLMs the future?
We are currently at the forefront of a new era in artificial intelligence, and despite its current limitations, multimodal models are poised to take over. These models combine multiple types and modalities of data and have the potential to completely transform the way we interact with machines.
Multimodal LLMs have achieved remarkable success in computer vision and natural language processing. However, in the future, we can expect multimodal LLMs to have an even more significant impact on our lives.
The possibilities for multimodal LLMs are endless and we have only begun to explore their true potential. Given their immense promise, it is clear that multimodal LLMs will play a crucial role in the future of AI.
Don’t forget to join our 16k+ ML SubReddit, discord channeland electronic newsletterwhere we share the latest AI research news, exciting AI projects, and more.
Sources:
- https://openai.com/research/gpt-4
- https://arxiv.org/abs/2302.14045
- https://www.marktechpost.com/2023/03/06/microsoft-presentes-kosmos-1-a-multimodal-large-language-model-that-can-perceive-general-modalities-follow-instructions-and- perform-in-context-learning/
- https://bdtechtalks.com/2023/03/13/multimodal-large-language-models/
- https://openai.com/customer-stories/khan-academy
- https://openai.com/product/gpt-4
- https://jina.ai/news/paradigm-shift-towards-multimodal-ai/
![]()
I am a civil engineering graduate (2022) from Jamia Millia Islamia, New Delhi, and I have strong interest in data science, especially in neural networks and its application in various areas.





{kind=link}