 NEWSLETTER
NEWSLETTER
The fashion industry is a highly lucrative business, with an estimated value of $2.1 trillion by 2025, as reported by the World Bank. This field encompasses a diverse range of segments, such as the creation, manufacture, distribution, and sales of clothing, shoes, and accessories. The industry is in a constant state of change, with new styles and trends appearing frequently. Therefore, fashion companies must be flexible and able to adapt in order to maintain their relevance and achieve success in the market.
Generative artificial intelligence (AI) refers to AI algorithms designed to generate new content, such as images, text, audio, or video, based on a set of learned patterns and data. It can be utilized to generate new and innovative apparel designs while offering improved personalization and cost-effectiveness. AI-driven design tools can create unique apparel designs based on input parameters or styles specified by potential customers through text prompts. Furthermore, AI can be utilized to personalize designs to the customer’s preferences. For example, a customer could select from a variety of colors, patterns, and styles, and AI models would generate a one-of-a-kind design based on those selections. The adoption of AI in the fashion industry is currently hindered by various technical, feasibility, and cost challenges. However, these obstacles can now be mitigated by utilizing advanced generative AI methods such as natural language-based image semantic segmentation and diffusion for virtual styling.
This blog post details the implementation of generative AI-assisted fashion online styling using text prompts. Machine learning (ML) engineers can fine-tune and deploy text-to-semantic-segmentation and in-painting models based on pre-trained CLIPSeq and Stable Diffusion with Amazon SageMaker. This enables fashion designers and consumers to create virtual modeling images based on text prompts and choose their preferred styles.
Generative AI Solutions
The CLIPSeg model introduced a novel image semantic segmentation method allowing you to easily identify fashion items in pictures using simple text commands. It utilizes a text prompt or an image encoder to encode textual and visual information into a multimodal embedding space, enabling highly accurate segmentation of target objects based on the prompt. The model has been trained on a vast amount of data with techniques such as zero-shot transfer, natural language supervision, and multimodal self-supervised contrastive learning. This means that you can utilize a pre-trained model that is publicly available by Timo Lüddecke et al without the need for customization.
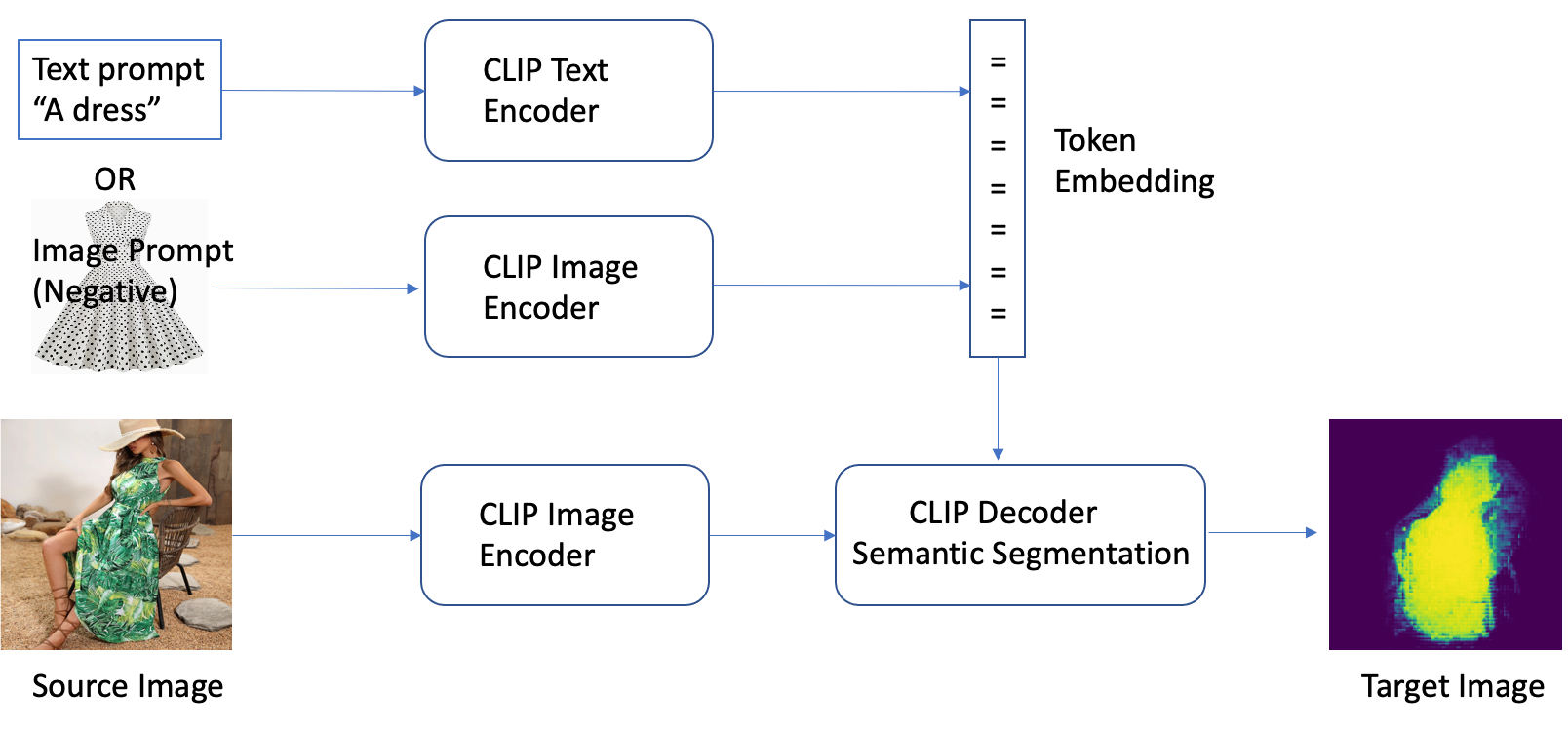
CLIPSeg is a model that uses a text and image encoder to encode textual and visual information into a multimodal embedding space to perform semantic segmentation based on a text prompt. The architecture of CLIPSeg consists of two main components: a text encoder and an image encoder. The text encoder takes in the text prompt and converts it into a text embedding, while the image encoder takes in the image and converts it into an image embedding. Both embeddings are then concatenated and passed through a fully connected layer to produce the final segmentation mask.
In terms of data flow, the model is trained on a dataset of images and corresponding text prompts, where the text prompts describe the target object to be segmented. During the training process, the text encoder and image encoder are optimized to learn the mapping between the text prompts and the image to produce the final segmentation mask. Once the model is trained, it can take in a new text prompt and image and produce a segmentation mask for the object described in the prompt.
Stable Diffusion is a technique that allows fashion designers to generate highly realistic imagery in large quantities purely based on text descriptions without the need for lengthy and expensive customization. This is beneficial for designers who want to create vogue styles quickly, and manufacturers who want to produce personalized products at a lower cost.
The following diagram illustrates the Stable Diffusion architecture and data flow.
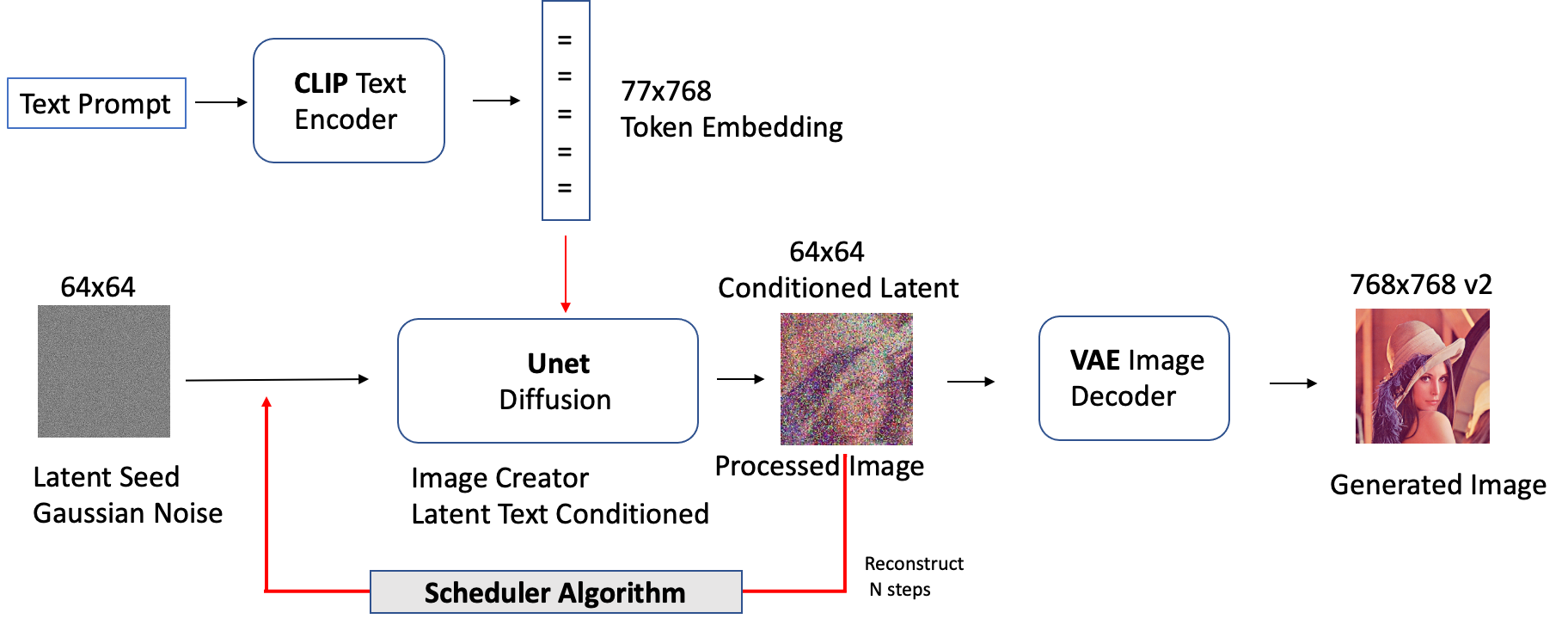
Compared to traditional GAN-based methods, Stable Diffusion is a generative AI that is capable of producing more stable and photo-realistic images that match the distribution of the original image. The model can be conditioned on a wide range of purposes, such as text for text-to-image generation, bounding boxes for layout-to-image generation, masked images for in-painting, and lower-resolution images for super-resolution. Diffusion models have a wide range of business applications, and their practical uses continue to evolve. These models will greatly benefit various industries such as fashion, retail and e-commerce, entertainment, social media, marketing, and more.
Generate masks from text prompts using CLIPSeg
Vogue online styling is a service that enables customers to receive fashion advice and recommendations from AI through an online platform. It does this by selecting clothing and accessories that complement the customer’s appearance, fit within their budget, and match their personal preferences. With the utilization of generative AI, tasks can be accomplished with greater ease, leading to increased customer satisfaction and reduced expenses.
The solution can be deployed on an Amazon Elastic Compute Cloud (EC2) p3.2xlarge instance, which has one single V100 GPU with 16G memory. Several techniques were employed to improve performance and reduce GPU memory usage, resulting in faster image generation. These include using fp16 and enabling memory efficient attention to decrease bandwidth in the attention block.
We began by having the user upload a fashion image, followed by downloading and extracting the pre-trained model from CLIPSeq. The image is then normalized and resized to comply with the size limit. Stable Diffusion V2 supports image resolution up to 768×768 while V1 supports up to 512×512. See the following code:
from models.clipseg import CLIPDensePredT
# The original image
image = download_image(img_url).resize((768, 768))
# Download pre-trained CLIPSeq model and unzip the pkg
! wget https://owncloud.gwdg.de/index.php/s/ioHbRzFx6th32hn/download -O weights.zip
! unzip -d weights -j weights.zip
# Load CLIP model. Available models = ['RN50', 'RN101', 'RN50x4',
# 'RN50x16', 'RN50x64', 'ViT-B/32', 'ViT-B/16', 'ViT-L/14', 'ViT-L/14@336px']
model = CLIPDensePredT(version='ViT-B/16', reduce_dim=64)
model.eval()
# non-strict, because we only stored decoder weights (not CLIP weights)
model.load_state_dict(torch.load('weights/rd64-uni.pth', \
map_location=torch.device('cuda')), strict=False)
# Image normalization and resizing
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
transforms.Resize((768, 768)),
])
img = transform(image).unsqueeze(0)With the use of the pre-trained CLIPSeq model, we are able to extract the target object from an image using a text prompt. This is done by inputting the text prompt into the text encoder, which converts it into a text embedding. The image is then input into the image encoder, which converts it into an image embedding. Both embeddings are then concatenated and passed through a fully connected layer to produce the final segmentation mask, which highlights the target object described in the text prompt. See the following code:
# Text prompt
prompt="Get the dress only."
# predict
mask_image_filename="the_mask_image.png"
with torch.no_grad():
preds = model(img.repeat(4,1,1,1), prompt)[0]
# save the mask image after computing the area under the standard
# Gaussian probability density function and calculates the cumulative
# distribution function of the normal distribution with ndtr.
plt.imsave(mask_image_filename,torch.special.ndtr(preds[0][0]))With the accurate mask image from semantic segmentation, we can use in-painting for content substitution. In-painting is the process of using a trained generative model to fill in missing parts of an image. By using the mask image to identify the target object, we can apply the in-painting technique to substitute the target object with something else, such as a different clothing item or accessory. The Stable Diffusion V2 model can be used for this purpose, because it is capable of producing high-resolution, photo-realistic images that match the distribution of the original image.
Fine-tuning from pre-trained models using DreamBooth
Fine-tuning is a process in deep learning where a pre-trained model is further trained on a new task using a small amount of labelled data. Rather than training from scratch, the idea is to take a network that has already been trained on a large dataset for a similar task and further train it on a new dataset to make it more specialized for that particular task.
Fashion designers can also use a subject-driven, fine-tuned Stable Diffusion in-painting model to generate a specific class of style, such as casual long skirts for ladies. To do this, the first step is to provide a set of sample images in the target domain, roughly about 1 dozens, with proper text labels such as the following and binding them to a unique identifier that references the design, style, color and fabric. The label on the text plays a critical role in determining the results of the fine-tuned model. There are several ways to enhance fine tuning through effective prompt engineering and here are a few examples.
Sample text prompts to descibe some of the most common design elements of casual
long skirts for ladies:
Design Style: A-line, wrap, maxi, mini, and pleated skirts are some of the most
popular styles for casual wear. A-line skirts are fitted at the waist and
flare out at the hem, creating a flattering silhouette. Wrap skirts have a
wrap closure and can be tied at the waist for a customizable fit. Maxi skirts
are long and flowy, while mini skirts are short and flirty. Pleated skirts
have folds that add texture and movement to the garment.
Pattern: Casual skirts can feature a variety of patterns, including stripes,
florals, polka dots, and solids. These patterns can range from bold and graphic
to subtle and understated.
Colors: Casual skirts come in a range of colors, including neutral shades likeblack,
white, and gray, as well as brighter hues like pink, red, and blue. Some skirts
may also feature multiple colors in a single garment, such asa skirt with a bold
pattern that incorporates several shades.
Fabrics: Common fabrics used in casual skirts include cotton, denim, linen, and
rayon. These materials offer different levels of comfort and durability, making
it easy to find a skirt that suits your personal style and needs.
Using a small set of images to fine-tune Stable Diffusion may result in model overfitting. DreamBooth[5] addresses this by using a class-specific prior-preservation loss. It learns to bind a unique identifier with that specific subject in two steps. First, it fine-tunes the low-resolution model with the input images paired with a text prompt that contains a unique identifier and the name of the class the subject belongs to, such as “skirt”. In practice, this means having the model fit images and the images sampled from the visual prior of the non-fine-tuned class simultaneously. These prior-preserving images are sampled and labeled using the “class noun” prompt. Second, it will fine-tune the super-high-resolution components by pairing low-resolution and high-resolution images from the input images set, which allows the outputs of the fine-tuned model to maintain fidelity to small details.
Fine-tuning a pre-trained in-painting text encoder with the UNet for resolution 512×512 images requires approximately 22GB of VRAM or higher for 768×768 resolution. Ideally fine-tune samples should be resized to match the desirable output image resolution to avoid performance degradation. The text encoder produces more accurate details such as model faces. One option is to run on a single AWS EC2 g5.2xlarge instance, now available in eight regions or use Hugging Face Accelerate to run the fine-tuned code across a distributed configuration. For additional memory savings, you can choose a sliced version of attention that performs the computation in steps instead of all at once by simply modifying DreamBooth’s training script train_dreambooth_inpaint.py to add the pipeline enable_attention_slicing() function.
Accelerate is a library that enables one fine tuning code to be run across any distributed configuration. Hugging Face and Amazon introduced Hugging Face Deep Learning Containers (DLCs) to scale fine tuning tasks across multiple GPUs and nodes. You can configure the launch configuration for Amazon SageMaker with a single CLI command.
# From your aws account, install the sagemaker sdk for Accelerate
pip install "accelerate[sagemaker]" --upgrade
# Configure the launch configuration for Amazon SageMaker
accelerate config
# List and verify Accelerate configuration
accelerate env
# Make necessary modification of the training script as the following to save
# output on S3, if needed
# - torch.save('/opt/ml/model`)
# + accelerator.save('/opt/ml/model')To launch a fine-tune job, verify Accelerate’s configuration using CLI and provide the necessary training arguments, then use the following shell script.
# Instance images — Custom images that represents the specific
# concept for dreambooth training. You should collect
# high #quality images based on your use cases.
# Class images — Regularization images for prior-preservation
# loss to prevent overfitting. You should generate these
# images directly from the base pre-trained model.
# You can choose to generate them on your own or generate
# them on the fly when running the training script.
#
# You can access train_dreambooth_inpaint.py from huggingface/diffuser
export MODEL_NAME="stabilityai/stable-diffusion-2-inpainting"
export INSTANCE_DIR="/data/fashion/gowns/highres/"
export CLASS_DIR="/opt/data/fashion/generated_gowns/imgs"
export OUTPUT_DIR="/opt/model/diffuser/outputs/inpainting/"
accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_text_encoder \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="A supermodel poses in long summer travel skirt, photorealistic" \
--class_prompt="A supermodel poses in skirt, photorealistic" \
--resolution=512 \
--train_batch_size=1 \
--use_8bit_adam \
--gradient_checkpointing \
--learning_rate=2e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--max_train_steps=800The fine-tuned in-painting model allows for the generation of more specific images to the fashion class described by the text prompt. Because it has been fine-tuned with a set of high-resolution images and text prompts, the model can generate images that are more tailored to the class, such as formal evening gowns. It’s important to note that the more specific the class and the more data used for fine-tuning, the more accurate and realistic the output images will be.
%tree -d ./finetuned-stable-diffusion-v2-1-inpainting
finetuned-stable-diffusion-v2-1-inpainting
├── 512-inpainting-ema.ckpt
├── feature_extractor
├── code
│ └──inference.py
│ ├──requirements.txt
├── scheduler
├── text_encoder
├── tokenizer
├── unet
└── vae
Deploy a fine-tuned in-painting model using SageMaker for inference
With Amazon SageMaker, you can deploy the fine-tuned Stable Diffusion models for real-tim inference. To upload the model to Amazon Simple Storage service (S3) for deployment, a model.tar.gz archive tarball must be created. Ensure the archive directly includes all files, not a folder that contains them. The DreamBooth fine-tuning archive folder should appear as follows after eliminating the intermittent checkpoints:
The initial step in creating our inference handler involves the creation of the inference.py file. This file serves as the central hub for loading the model and handling all incoming inference requests. After the model is loaded, the model_fn() function is executed. When the need arises to perform inference, the predict_fn() function is called. Additionally, the decode_base64() function is utilized to convert a JSON string, contained within the payload, into a PIL image data type.
%%writefile code/inference.py
import base64
import torch
from PIL import Image
from io import BytesIO
from diffusers import EulerDiscreteScheduler, StableDiffusionInpaintPipeline
def decode_base64(base64_string):
decoded_string = BytesIO(base64.b64decode(base64_string))
img = Image.open(decoded_string)
return img
def model_fn(model_dir):
# Load stable diffusion and move it to the GPU
scheduler = EulerDiscreteScheduler.from_pretrained(model_dir, subfolder="scheduler")
pipe = StableDiffusionInpaintPipeline.from_pretrained(model_dir,
scheduler=scheduler,
revision="fp16",
torch_dtype=torch.float16)
pipe = pipe.to("cuda")
pipe.enable_xformers_memory_efficient_attention()
#pipe.enable_attention_slicing()
return pipe
def predict_fn(data, pipe):
# get prompt & parameters
prompt = data.pop("inputs", data)
# Require json string input. Inference to convert imge to string.
input_img = data.pop("input_img", data)
mask_img = data.pop("mask_img", data)
# set valid HP for stable diffusion
num_inference_steps = data.pop("num_inference_steps", 25)
guidance_scale = data.pop("guidance_scale", 6.5)
num_images_per_prompt = data.pop("num_images_per_prompt", 2)
image_length = data.pop("image_length", 512)
# run generation with parameters
generated_images = pipe(
prompt,
image = decode_base64(input_img),
mask_image = decode_base64(mask_img),
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
num_images_per_prompt=num_images_per_prompt,
height=image_length,
width=image_length,
#)["images"] # for Stabel Diffusion v1.x
).images
# create response
encoded_images = []
for image in generated_images:
buffered = BytesIO()
image.save(buffered, format="JPEG")
encoded_images.append(base64.b64encode(buffered.getvalue()).decode())
return {"generated_images": encoded_images}
To upload the model to an Amazon S3 bucket, it’s necessary to first create a model.tar.gz archive. It’s crucial to note that the archive should consist of the files directly and not a folder that holds them. For instance, the file should appear as follows:
import tarfile
import os
# helper to create the model.tar.gz
def compress(tar_dir=None,output_file="model.tar.gz"):
parent_dir=os.getcwd()
os.chdir(tar_dir)
with tarfile.open(os.path.join(parent_dir, output_file), "w:gz") as tar:
for item in os.listdir('.'):
print(item)
tar.add(item, arcname=item)
os.chdir(parent_dir)
compress(str(model_tar))
# After we created the model.tar.gz archive we can upload it to Amazon S3. We will
# use the sagemaker SDK to upload the model to our sagemaker session bucket.
from sagemaker.s3 import S3Uploader
# upload model.tar.gz to s3
s3_model_uri=S3Uploader.upload(local_path="model.tar.gz", \
desired_s3_uri=f"s3://{sess.default_bucket()}/finetuned-stable-diffusion-v2-1-inpainting")After the model archive is uploaded, we can deploy it on Amazon SageMaker using HuggingfaceModel for real-time inference. You can host the endpoint using a g4dn.xlarge instance, which is equipped with a single NVIDIA Tesla T4 GPU with 16GB of VRAM. Autoscaling can be activated to handle varying traffic demands. For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker.
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_model_uri, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version='py38', # python version used
)
# deploy the endpoint endpoint
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.g4dn.xlarge"
)The huggingface_model.deploy() method returns a HuggingFacePredictor object that can be used to request inference. The endpoint requires a JSON with an inputs key, which represents the input prompt for the model to generate an image. You can also control the generation with parameters such as num_inference_steps, guidance_scale, and “num_images_per_prompt”. The predictor.predict() function returns a JSON with a “generated_images” key, which holds the four generated images as base64 encoded strings. We added two helper functions, decode_base64_to_image and display_images, to decode the response and display the images respectively. The former decodes the base64 encoded string and returns a PIL.Image object, and the latter displays a list of PIL.Image objects. See the following code:
import PIL
from io import BytesIO
from IPython.display import display
import base64
import matplotlib.pyplot as plt
import json
# Encoder to convert an image to json string
def encode_base64(file_name):
with open(file_name, "rb") as image:
image_string = base64.b64encode(bytearray(image.read())).decode()
return image_string
# Decode to to convert a json str to an image
def decode_base64_image(base64_string):
decoded_string = BytesIO(base64.b64decode(base64_string))
img = PIL.Image.open(decoded_string)
return img
# display PIL images as grid
def display_images(images=None,columns=3, width=100, height=100):
plt.figure(figsize=(width, height))
for i, image in enumerate(images):
plt.subplot(int(len(images) / columns + 1), columns, i + 1)
plt.axis('off')
plt.imshow(image)
# Display images in a row/col grid
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = PIL.Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return gridLet’s move forward with the in-painting task. It has been estimated that it will take roughly 15 seconds to produce three images, given the input image and the mask created using CLIPSeg with the text prompt discussed previously. See the following code:
num_images_per_prompt = 3
prompt = "A female super-model poses in a casual long vacation skirt, with full body length, bright colors, photorealistic, high quality, highly detailed, elegant, sharp focus"
# Convert image to string
input_image_filename = "./imgs/skirt-model-2.jpg"
encoded_input_image = encode_base64(input_image_filename)
encoded_mask_image = encode_base64("./imgs/skirt-model-2-mask.jpg")
# Set in-painint parameters
guidance_scale = 6.7
num_inference_steps = 45
# run prediction
response = predictor.predict(data={
"inputs": prompt,
"input_img": encoded_input_image,
"mask_img": encoded_mask_image,
"num_images_per_prompt" : num_images_per_prompt,
"image_length": 768
}
)
# decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]]
# visualize generation
display_images(decoded_images, columns=num_images_per_prompt, width=100, height=100)
# insert initial image in the list so we can compare side by side
image = PIL.Image.open(input_image_filename).convert("RGB")
decoded_images.insert(0, image)
# Display inpainting images in grid
image_grid(decoded_images, 1, num_images_per_prompt + 1)
The in-painted images can be displayed along with the original image for visual comparison. Additionally, the in-painting process can be constrained using various parameters such as guidance_scale, which controls the strength of the guidance image during the in-painting process. This allows the user to adjust the output image and achieve the desired results.
Amazon SageMaker Jumpstart offers Stable Diffusion templates for various models, including text-to-image and upscaling. For more information, please refer to SageMaker JumpStart now provides Stable Diffusion and Bloom models. Additional Jumpstart templates will be available in the near future.
Limitations
Although CLIPSeg usually performs well on recognizing common objects, it struggles on more abstract or systematic tasks such as counting the number of objects in an image and on more complex tasks such as predicting how close the nearest object such a handbag is in a photo. Zero-shot CLIPSeq also struggles compared to task-specific models on very fine-grained classification, such as telling the difference between two vague designs, variants of dress, or style classification. CLIPSeq also still has poor generalization to images not covered in its pre-training dataset. Finally, it has been observed that CLIP’s zero-shot classifiers can be sensitive to wording or phrasing and sometimes require trial and error “prompt engineering” to perform well. Switching to a different semantic segmentation model for CLIPSeq’s backbone, such as BEiT, which boasts a 62.8% mIOU on the ADE20K dataset, could potentially improve results.
Fashion designs generated by using Stable Diffusion have been found to be limited to parts of garments that are at least as predictably-placed in the wider context of the fashion models, and which conform to high-level embeddings that you could reasonably expect to find in a hyperscale dataset used during training the pre-trained model. The real limit of generative AI is that the model will eventually produce totally imaginary and less authentic outputs. Therefore, the fashion designs generated by AI may not be as varied or unique as those created by human designers.
Conclusion
Generative AI provides the fashion sector an opportunity to transform their practices through better user experiences and cost-efficient business strategies. In this post, we showcase how to harness generative AI to enable fashion designers and consumers to create personalized fashion styles using virtual modeling. With the assistance of existing Amazon SageMaker Jumpstart templates and those to come, users can quickly embrace these advanced techniques without needing in-depth technical expertise, all while maintaining versatility and lowering expenses.
This innovative technology presents new chances for companies and professionals involved in content generation, across various industries. Generative AI provides ample capabilities for enhancing and creating content. Try out the recent additions to the Jumpstart templates in your SageMaker Studio, such as fine-tuning text-to-image and upscale capabilities.
We would like to thank Li Zhang, Karl Albertsen, Kristine Pearce, Nikhil Velpanur, Aaron Sengstacken, James Wu and Neelam Koshiya for their supports and valuable inputs that helped improve this work.
About the Authors
 Alfred Shen is a Senior AI/ML Specialist at AWS. He has been worked in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
Alfred Shen is a Senior AI/ML Specialist at AWS. He has been worked in Silicon Valley, holding technical and managerial positions in diverse sectors including healthcare, finance, and high-tech. He is a dedicated applied AI/ML researcher, concentrating on CV, NLP, and multimodality. His work has been showcased in publications such as EMNLP, ICLR, and Public Health.
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences






{kind=link}