
The development of TTS systems has been instrumental in converting written content into spoken language, allowing users to interact with the text audibly. This technology is particularly beneficial for understanding documents containing complex information, such as scientific articles and technical manuals, which often present significant challenges for people who rely solely on listening comprehension.
A persistent problem with existing TTS systems is their inability to process mathematical formulas accurately. These systems typically treat formulas as plain text, resulting in unintelligible or incomplete speech. This problem is especially common in academic and technical documents that use LaTeX to represent mathematical content. Because formulas are represented in distinctive formats, traditional TTS systems do not recognize their mathematical meaning, resulting in inaccurate or omitted speech output. This limitation presents a significant barrier for users, especially those in mathematics and science.
Current methods to address this problem involve OCR (optical character recognition) technologies and basic TTS integration. However, these approaches have limitations. For example, OCR systems convert formulas into text but do not interpret their semantic structure, making them unsuitable for accurate vocalization. Popular TTS readers like Microsoft Edge and Adobe Acrobat skip or incorrectly read mathematical formulas, highlighting the need for a more sophisticated solution. Some tools attempt to manually map LaTeX code to spoken English, but they have problems with exception cases and are not practical for widespread use.
Researchers from Seoul National University, Chung-Ang University, and NVIDIA developed MathReader to bridge this gap between the technology and users needed to read mathematical texts. MathReader combines an OCR, a fine-tuned T5 small language model, and a TTS system to decode mathematical expressions without errors. It overcomes the limited capabilities of current technologies so that document formulas are accurately vocalized. A channel that claims that mathematical content is converted to audio has significantly helped visually impaired users.
MathReader uses a five-step methodology to process documents. First, OCR is used to extract text and formulas from documents. Based on hierarchical vision transformers, Nougat's small OCR model converts PDF files into markup language files while distinguishing between text and LaTeX formulas. Formulas are then identified using unique LaTeX markers. The fine-tuned T5 small language model then translates these formulas into spoken English, effectively interpreting mathematical expressions into audible language. The translated formulas then replace their LaTeX counterparts in the text, ensuring compatibility with TTS systems. Finally, the VITS TTS model converts the updated text into high-quality speech. This process ensures accuracy and efficiency, making MathReader an innovative document-accessible tool.

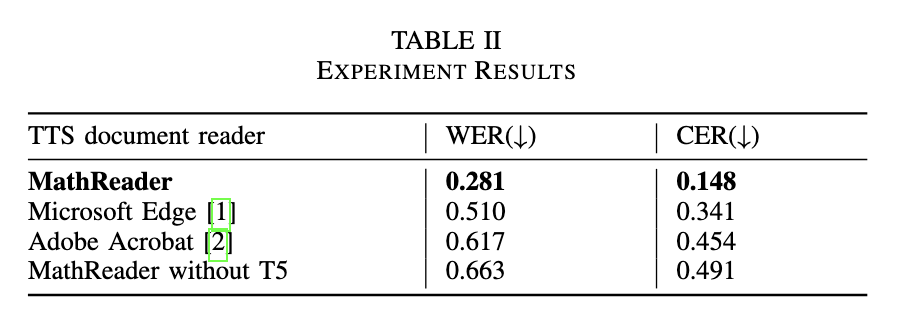
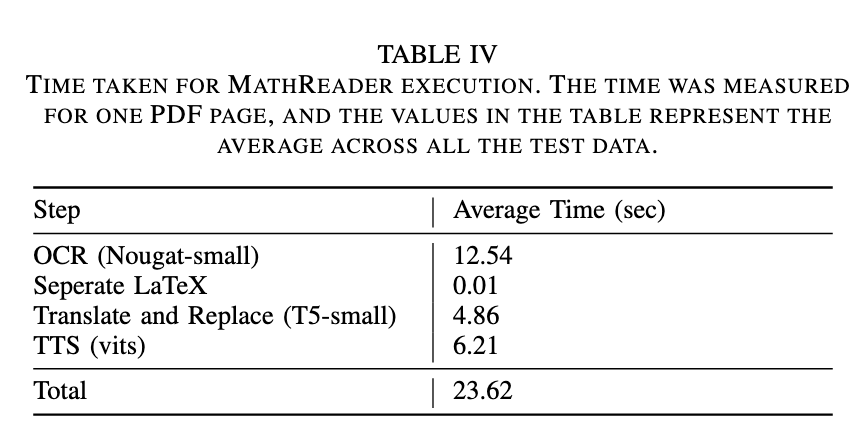
The performance evaluation highlights the effectiveness of MathReader. It significantly outperforms existing TTS systems, achieving a word error rate (WER) of 0.281 compared to 0.510 for Microsoft Edge and 0.617 for Adobe Acrobat. Similarly, its character error rate (CER) is remarkably low: 0.148, compared to 0.341 and 0.454 for the other systems. This substantial improvement demonstrates MathReader's ability to deliver accurate speech output, even for documents with complex or low-resolution mathematical content. For example, MathReader successfully vocalized formulas omitted by other systems, demonstrating its robustness. Furthermore, the time taken to process a single page averaged 23.62 seconds, including 12.54 seconds for OCR and 6.21 seconds for TTS conversion, indicating its practicality for real-time applications.
MathReader represents a significant advancement in TTS technology, addressing the critical challenge of accurately vocalizing mathematical content. Its integration of advanced OCR, an optimized language model and TTS ensures a comprehensive solution for users who rely on auditory access to documents. By delivering accurate and efficient results, MathReader sets a new standard for accessibility tools, providing an indispensable resource for people with visual impairments and paving the way for future innovations in this field.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 65,000 ml.
<a target="_blank" href="https://nebius.com/blog/posts/studio-embeddings-vision-and-language-models?utm_medium=newsletter&utm_source=marktechpost&utm_campaign=embedding-post-ai-studio” target=”_blank” rel=”noreferrer noopener”> (Recommended Reading) Nebius ai Studio Expands with Vision Models, New Language Models, Embeddings, and LoRA (Promoted)
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.






{kind=link}