
In many real-world applications, data is not purely textual; They can include images, tables and graphs that help reinforce the narrative. A multimodal report builder allows you to incorporate text and images into a final output, making your reports more dynamic and visually rich.
This article describes how to build such a pipeline using:
- CallIndex to orchestrate document analysis and query engines,
- Open ai language models for textual analysis,
- Call Parse to extract text and images from PDF documents,
- An observability setup using Arize Phoenix (via LlamaTrace) to log in and debug.
The end result is a process that can process an entire PDF slide deck (both text and images) and generate a structured report containing text and images.
Learning objectives
- Understand how to integrate text and visuals to generate effective financial reports using multimodal channels.
- Learn how to use LlamaIndex and LlamaParse to improve financial reporting with structured results.
- Explore LlamaParse to efficiently extract text and images from PDF documents.
- Set up observability using Arize Phoenix (via LlamaTrace) to log and debug complex pipelines.
- Create a structured query engine to generate reports that intersperse text summaries with visual elements.
This article was published as part of the Data Science Blogathon.
Process Overview
Creating a multimodal report builder involves creating a pipeline that seamlessly integrates textual and visual elements of complex documents such as PDF files. The process begins with installing the necessary libraries, such as LlamaIndex for document analysis and query orchestration, and LlamaParse for extracting text and images. Observability is established using Arize Phoenix (via LlamaTrace) to monitor and debug the pipeline.
Once the setup is complete, the pipeline processes a PDF document, parses its content into structured text, and renders visual elements such as tables and charts. These analyzed elements are then associated, creating a unified data set. A SummaryIndex is created to enable high-level information and a structured query engine is developed to generate reports that combine textual analysis with relevant visual elements. The result is a dynamic, interactive report builder that transforms static documents into rich multimodal results tailored to user queries.
Step by step implementation
Follow this step-by-step guide to create a multimodal report builder, from setting up dependencies to generating structured results with embedded text and images. Each step ensures a seamless integration of LlamaIndex, LlamaParse and Arize Phoenix for an efficient and dynamic process.
Step 1: Install and import dependencies
You will need the following libraries running on Python 3.9.9:
- flame index
- call-parse (for text + image analysis)
- calls-index-callbacks-arize-phoenix (for observability/logging)
- asyncio_nest (to handle asynchronous event loops in notebooks)
!pip install -U llama-index-callbacks-arize-phoenix
import nest_asyncio
nest_asyncio.apply()Step 2: Set up observability
We integrate with LlamaTrace – LlamaCloud API (Arize Phoenix). First, get an API key from llamatrace.comthen set environment variables to send traces to Phoenix.
The Phoenix API key can be obtained by registering at LlamaTrace here then navigate to the bottom left panel and click on 'Keys' where you should find your API key.
For example:
PHOENIX_API_KEY = ""
os.environ("OTEL_EXPORTER_OTLP_HEADERS") = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)Step 3 – Upload Data – Get Your Slide Deck
As a demonstration, we used the slideshow from ConocoPhillips' 2023 investor meeting. We download the PDF:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Check if the PDF slide deck is in the data folder; otherwise, place it in the data folder and name it whatever you want.
Step 4: configure models
You need an integration model and an LLM. In this example:
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(model="text-embedding-3-large")
llm = OpenAI(model="gpt-4o")Next, register them as default for LlamaIndex:
from llama_index.core import Settings
Settings.embed_model = embed_model
Settings.llm = llmStep 5: Parse the document with LlamaParse
LlamaParse can extract text and images (via a large multi-modal model). For each PDF page, it returns:
- Sales text (with tables, titles, bullets, etc.)
- A rendered image (saved locally)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs(0)("pages")
print(md_json_list(10)("md"))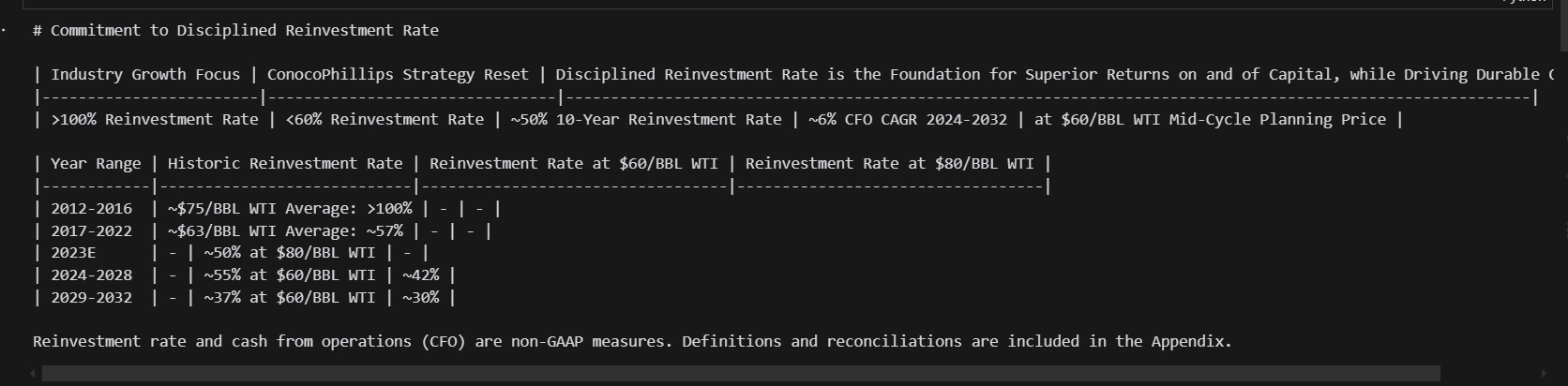
print(md_json_list(1).keys())
image_dicts = parser.get_images(md_json_objs, download_path="data_images")
Step 6: Associate text and images
We create a list of text node objects (LlamaIndex data structure) for each page. Each node has metadata about the page number and the path of the corresponding image file:
from llama_index.core.schema import TextNode
from typing import Optional
# get pages loaded through llamaparse
import re
def get_page_number(file_name):
match = re.search(r"-page-(\d+)\.jpg$", str(file_name))
if match:
return int(match.group(1))
return 0
def _get_sorted_image_files(image_dir):
"""Get image files sorted by page."""
raw_files = (f for f in list(Path(image_dir).iterdir()) if f.is_file())
sorted_files = sorted(raw_files, key=get_page_number)
return sorted_files
from copy import deepcopy
from pathlib import Path
# attach image metadata to the text nodes
def get_text_nodes(json_dicts, image_dir=None):
"""Split docs into nodes, by separator."""
nodes = ()
image_files = _get_sorted_image_files(image_dir) if image_dir is not None else None
md_texts = (d("md") for d in json_dicts)
for idx, md_text in enumerate(md_texts):
chunk_metadata = {"page_num": idx + 1}
if image_files is not None:
image_file = image_files(idx)
chunk_metadata("image_path") = str(image_file)
chunk_metadata("parsed_text_markdown") = md_text
node = TextNode(
text="",
metadata=chunk_metadata,
)
nodes.append(node)
return nodes
# this will split into pages
text_nodes = get_text_nodes(md_json_list, image_dir="data_images")
print(text_nodes(10).get_content(metadata_mode="all"))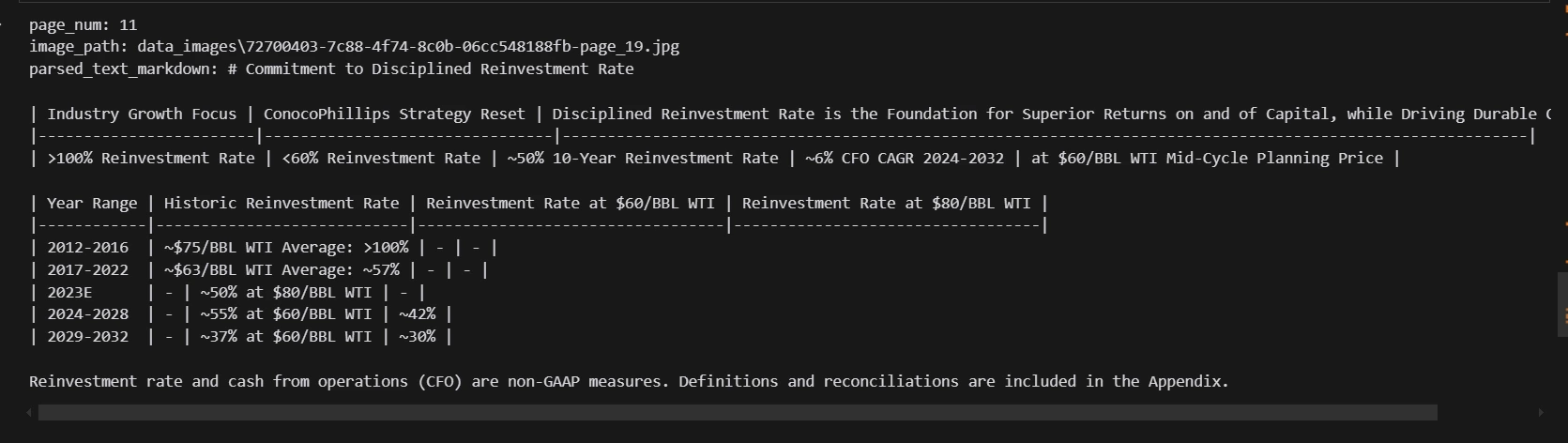
Step 7: Create a summary index
With these text nodes in hand, you can create a SummaryIndex:
import os
from llama_index.core import (
StorageContext,
SummaryIndex,
load_index_from_storage,
)
if not os.path.exists("storage_nodes_summary"):
index = SummaryIndex(text_nodes)
# save index to disk
index.set_index_id("summary_index")
index.storage_context.persist("./storage_nodes_summary")
else:
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage_nodes_summary")
# load index
index = load_index_from_storage(storage_context, index_id="summary_index")SummaryIndex ensures that you can easily retrieve or generate high-level summaries of the entire document.
Step 8: Define a structured output scheme
Our process aims to produce a final result with interlocking blocks of text and blocks of images. For that, we create a custom Pydantic model (using Pydantic v2 or ensuring compatibility) with two types of blocks:text block and Image block—and a parental model ReportOutput:
from llama_index.llms.openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
from IPython.display import display, Markdown, Image
from typing import Union
class TextBlock(BaseModel):
"""Text block."""
text: str = Field(..., description="The text for this block.")
class ImageBlock(BaseModel):
"""Image block."""
file_path: str = Field(..., description="File path to the image.")
class ReportOutput(BaseModel):
"""Data model for a report.
Can contain a mix of text and image blocks. MUST contain at least one image block.
"""
blocks: List(Union(TextBlock, ImageBlock)) = Field(
..., description="A list of text and image blocks."
)
def render(self) -> None:
"""Render as HTML on the page."""
for b in self.blocks:
if isinstance(b, TextBlock):
display(Markdown(b.text))
else:
display(Image(filename=b.file_path))
system_prompt = """\
You are a report generation assistant tasked with producing a well-formatted context given parsed context.
You will be given context from one or more reports that take the form of parsed text.
You are responsible for producing a report with interleaving text and images - in the format of interleaving text and "image" blocks.
Since you cannot directly produce an image, the image block takes in a file path - you should write in the file path of the image instead.
How do you know which image to generate? Each context chunk will contain metadata including an image render of the source chunk, given as a file path.
Include ONLY the images from the chunks that have heavy visual elements (you can get a hint of this if the parsed text contains a lot of tables).
You MUST include at least one image block in the output.
You MUST output your response as a tool call in order to adhere to the required output format. Do NOT give back normal text.
"""
llm = OpenAI(model="gpt-4o", api_key="OpenAI_API_KEY", system_prompt=system_prompt)
sllm = llm.as_structured_llm(output_cls=ReportOutput)The key point: ReportOutput requires at least one block of images, which ensures that the final response is multimodal.
Step 9 – Create a structured query engine
LlamaIndex allows you to use a “structured LLM” (that is, an LLM whose output is automatically parsed into a specific schema). Here's how:
query_engine = index.as_query_engine(
similarity_top_k=10,
llm=sllm,
# response_mode="tree_summarize"
response_mode="compact",
)
response = query_engine.query(
"Give me a summary of the financial performance of the Alaska/International segment vs. the lower 48 segment"
)
response.response.render()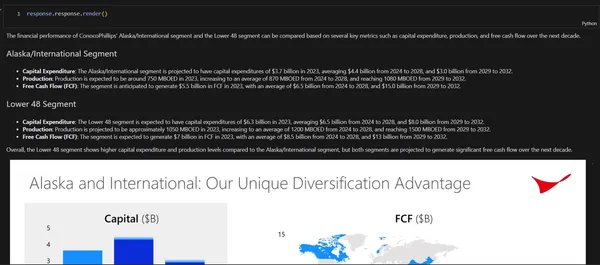
# Output
The financial performance of ConocoPhillips' Alaska/International segment and the Lower 48 segment can be compared based on several key metrics such as capital expenditure, production, and free cash flow over the next decade.
Alaska/International Segment
Capital Expenditure: The Alaska/International segment is projected to have capital expenditures of $3.7 billion in 2023, averaging $4.4 billion from 2024 to 2028, and $3.0 billion from 2029 to 2032.
Production: Production is expected to be around 750 MBOED in 2023, increasing to an average of 870 MBOED from 2024 to 2028, and reaching 1080 MBOED from 2029 to 2032.
Free Cash Flow (FCF): The segment is anticipated to generate $5.5 billion in FCF in 2023, with an average of $6.5 billion from 2024 to 2028, and $15.0 billion from 2029 to 2032.
Lower 48 Segment
Capital Expenditure: The Lower 48 segment is expected to have capital expenditures of $6.3 billion in 2023, averaging $6.5 billion from 2024 to 2028, and $8.0 billion from 2029 to 2032.
Production: Production is projected to be approximately 1050 MBOED in 2023, increasing to an average of 1200 MBOED from 2024 to 2028, and reaching 1500 MBOED from 2029 to 2032.
Free Cash Flow (FCF): The segment is expected to generate $7 billion in FCF in 2023, with an average of $8.5 billion from 2024 to 2028, and $13 billion from 2029 to 2032.
Overall, the Lower 48 segment shows higher capital expenditure and production levels compared to the Alaska/International segment, but both segments are projected to generate significant free cash flow over the next decade.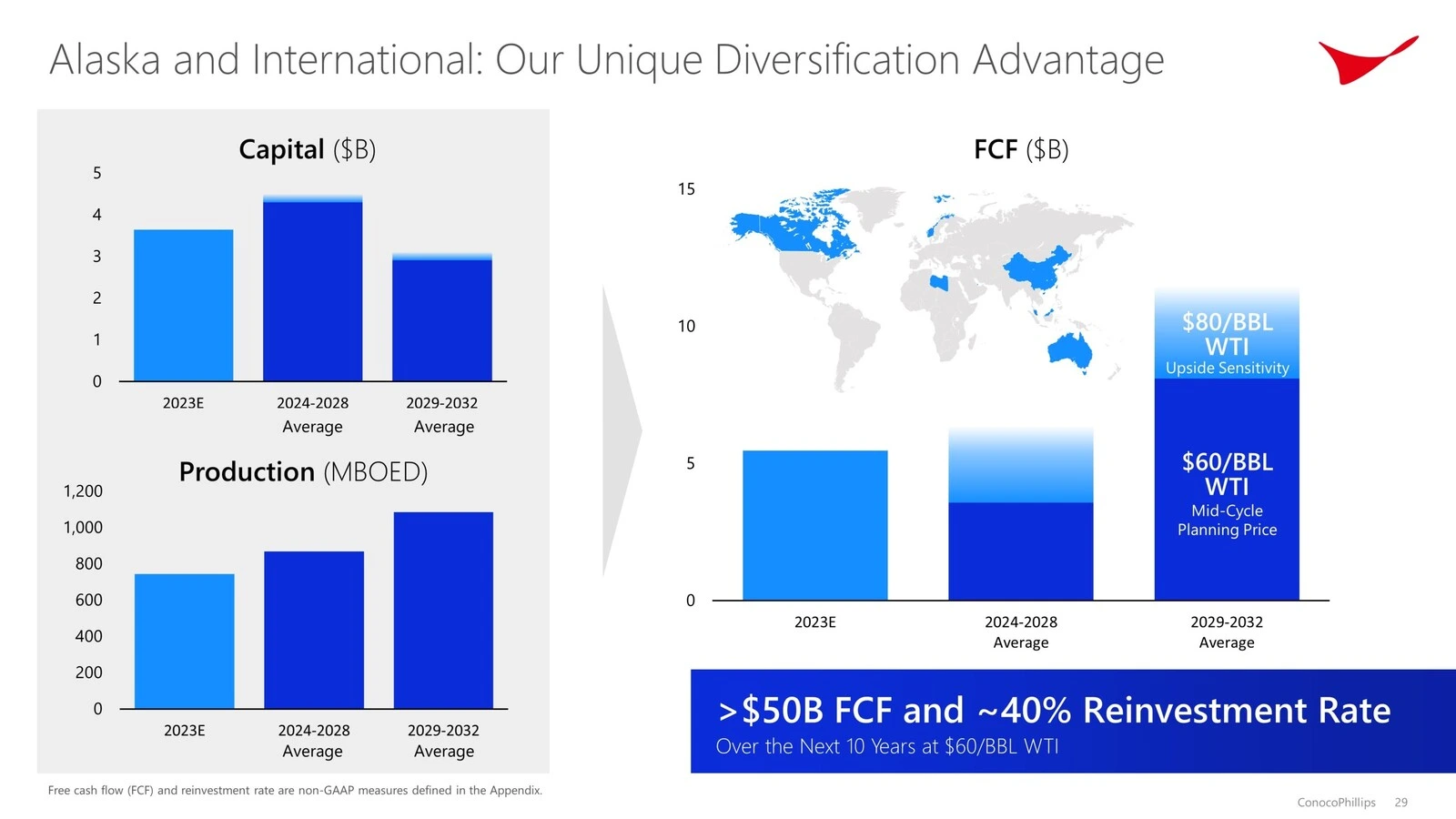
# Trying another query
response = query_engine.query(
"Give me a summary of whether you think the financial projections are stable, and if not, what are the potential risk factors. "
"Support your research with sources."
)
response.response.render()
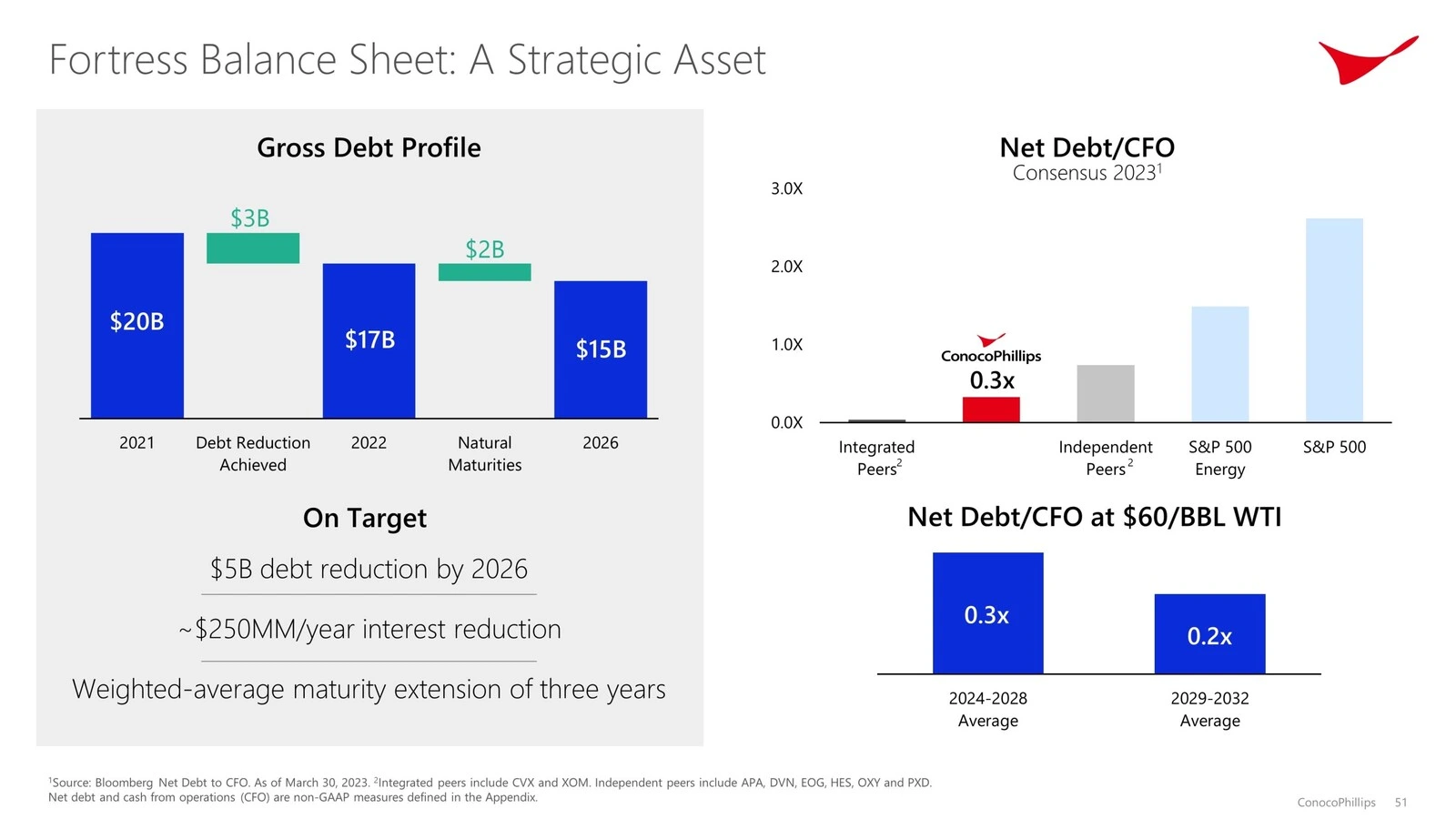
Conclusion
By combining LlamaIndex, LlamaParse, and OpenAI, you can create a multimodal report generator that processes an entire PDF (with text, tables, and images) into structured output. This approach delivers richer, more visually informative results—exactly what stakeholders need to glean critical insights from complex corporate or technical documents.
Feel free to adapt this pipeline to your own documents, add a recovery step for large files, or integrate domain-specific models to analyze the underlying images. With the foundation laid out here, you can create dynamic, interactive, and visually rich reports that go far beyond simple text-based queries.
Many thanks to Jerry Liu from LlamaIndex for developing this amazing channel.
Key takeaways
- Transform PDF files with text and images into structured formats while preserving the integrity of the original content using LlamaParse and LlamaIndex.
- Generate visually rich reports that interweave textual summaries and images for better contextual understanding.
- Financial reporting can be enhanced by integrating text and visuals for more insightful and dynamic results.
- Leveraging LlamaIndex and LlamaParse streamlines the financial reporting process, ensuring accurate and structured results.
- Retrieve relevant documents before processing to optimize reporting for large files.
- Improve visual analytics, incorporate graph-specific analytics, and combine models for text and image processing to gain deeper insights.
Frequently asked questions
A. A multimodal report generator is a system that produces reports that contain multiple types of content (primarily text and images) in a coherent output. In this process, a PDF is analyzed into textual and visual elements and then combined into a single final report.
A. Observability tools like Arize Phoenix (via LlamaTrace) allow you to monitor and debug model behavior, track queries and responses, and identify problems in real time. It is especially useful when dealing with large or complex documents and multiple steps based on LLM.
A. Most PDF text extractors only handle plain text, and often miss formatting, images, and tables. LlamaParse is capable of extracting text and images (rendered page images), which is crucial for creating multimodal channels where you need to query tables, charts, or other visual elements.
A. SummaryIndex is an abstraction of LlamaIndex that organizes your content (for example, pages of a PDF) so you can quickly generate complete summaries. It helps gather high-level information from long documents without having to manually fragment them or run a retrieval query for each piece of data.
A. In the ReportOutput Pydantic model, enforce that the block list requires at least one ImageBlock. This is indicated in the schematic and in the system message. The LLM must follow these rules or it will not produce valid structured results.
The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.

Hello! I am Adarsh, a Business Analytics graduate from ISB, currently immersed in research and exploring new frontiers. I am passionate about data science, artificial intelligence, and all the innovative ways they can transform industries. Whether it's building models, working on data pipelines, or diving into machine learning, I love experimenting with the latest technology. ai is not just my interest, it's where I see the future going, and I'm always excited to be a part of that journey!





