
Microsoft's Phi-4 model is available in Hugging Face and offers developers a powerful tool for advanced reasoning and text generation tasks. In this article, we'll walk you through the steps to access and use Phi-4, from creating a Hugging Face account to generating results with the model. We'll also explore key features, including its optimized performance for memory and compute-constrained environments, and how you can use Phi-4 effectively in various applications.
Phi 4 and its characteristics
Phi-4 is a next-generation language model designed for advanced reasoning and high-quality text generation. In this Phi-4, we have around 14 billion parameters that align well across memory and computationally limited scenarios to make it very suitable for developers looking to incorporate efficient ai into their applications.
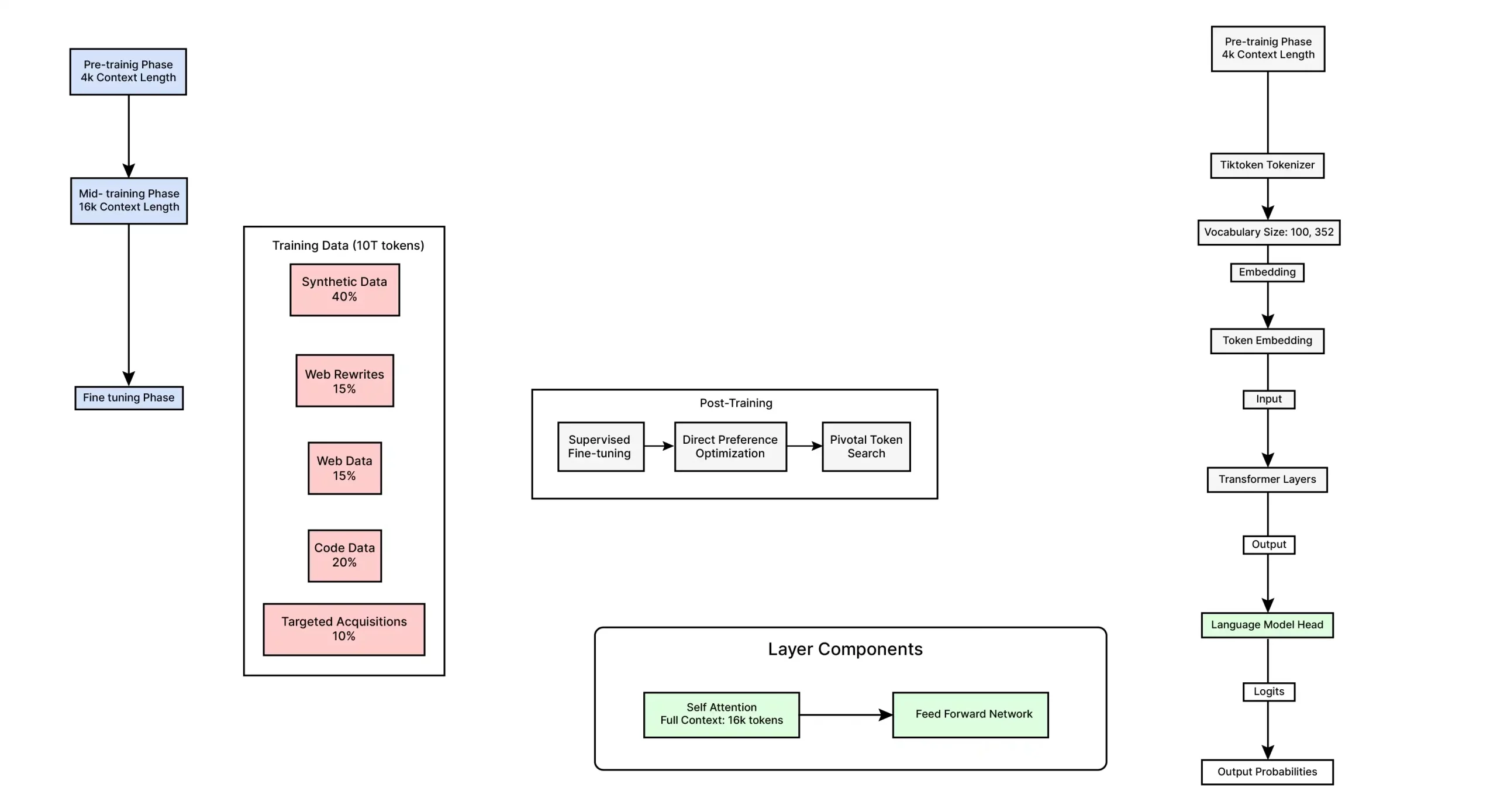
The Phi-4 model follows a decoder-only transformative architecture with 14 billion parameters, designed to process text through a sophisticated pipeline. Essentially, the input text is first tokenized using the Tiktoken tokenizer with a vocabulary size of 100,352, which is then fed into the token embedding layer. The core architecture of the transformer consists of multiple layers of self-attention mechanisms capable of handling a 16K token context window (expanded from 4K during mid-training), followed by feedback networks.
The model was trained on approximately 10 billion tokens with a diverse data composition: 40% synthetic data, 15% web rewrites, 15% leaked web data, 20% code data, and 10% targeted acquisitions. The training process progressed through three main phases: pre-training (with 4K context), mid-training (extended to a 16K context), and adjustment. Post-training improvements included supervised fine-tuning (SFT), direct preference optimization (DPO) with foundational token search, and judge-guided data, culminating in a language model that generates probability distributions over its vocabulary to generate responses. .
You can read more about Phi-4 here.
Phi-4 Features
- Context length: Phi-4 supports a context length of up to 16,000 tokens, allowing for extensive conversations or detailed text generation.
- Security measures: The model incorporates robust security features, including supervised tuning and preference optimization, to ensure safe and useful interactions.
Prerequisites
Before beginning the PHI 4 access process, make sure you have the following prerequisites:
- Hug Face Account: You will need a Hugging Face account to access and use models from the Hub.
- Python environment: Make sure you have Python 3.7 or later installed on your machine.
- Libraries: Install the necessary libraries.
Use the following commands to install them:
pip install transformers
pip install torchHow to access Phi-4 using Hugging Face?
Next, we'll show you how to easily access and use Microsoft's Phi-4 model in Hugging Face, enabling powerful reasoning and text generation capabilities for your applications. Follow our step-by-step instructions to get started quickly and efficiently.
Step 1: Create a Hug Face Account
To access PHI 4 and other models, you must first create an account on Hugging Face. Visit Hugging Face Website and register. After creating an account, you will be able to access public and private models hosted on the platform.
Step 2: Authenticate with your face hug
To access private models like PHI 4, you must authenticate your Hugging Face account. You can use the Hugging Face CLI tool to do this:
Install the CLI tool:
pip install huggingface_hubLog in to your Hugging Face account by running the following command:
huggingface-cli loginEnter your credentials or token when prompted.
Step 3 – Install the necessary libraries
First, make sure you have the transformer library installed. You can install it using pip:
pip install transformersStep 4: Load the Phi-4 Model
Once the library is installed, you can load the Phi-4 model using the Hugging Face pipeline API. Here's how you can do it:
import transformers
# Load the Phi-4 model
pipeline = transformers.pipeline(
"text-generation",
model="microsoft/phi-4",
model_kwargs={"torch_dtype": "auto"},
device_map="auto",
)Step 5: Prepare your opinion
Phi-4 is optimized for chat-style messages. You can structure your entry as follows:
messages = (
{"role": "system", "content": "You are a data scientist providing insights and explanations to a curious audience."},
{"role": "user", "content": "How should I explain machine learning to someone new to the field?"},
)Step 6: Generate results
Use the pipeline to generate responses based on your input:
outputs = pipeline(messages, max_new_tokens=128)
print(outputs(0)('generated_text'))Production:

Conclusion
Phi-4 is now fully accessible on Hugging Face, making it easier than ever for developers and researchers to leverage its capabilities for various applications. Whether you're building chatbots, educational tools, or any application that requires advanced language understanding, Phi-4 stands out as a powerful option.
For more details and updates, you can check the official site. Hugging Face Documentation and explore the capabilities of this innovative model.
Frequently asked questions
A. Microsoft developed Phi-4, a next-generation language model, to excel in advanced reasoning and high-quality text generation. With 14 billion parameters, it optimizes performance for memory- and compute-constrained environments.
A. You need Python 3.7 or later and libraries like transformers, torch, and huggingface_hub. Make sure your machine meets the necessary computing requirements, especially for handling large models.
A. Phi-4 is ideal for text generation, advanced reasoning, chatbot development, educational tools, and any application that requires extensive language understanding and generation.
A. Microsoft optimized Phi-4 for chat-style messages, structuring entries as a list of messages, each with a role (e.g., system, user) and content.
A. Key features of Phi-4 are:
14 billion parameters – for advanced text generation
Context length: up to 16,000 tokens.
Safety features: Monitored adjustment and preference optimization for safe interactions.
Efficiency: Optimized for memory and compute constrained environments.

Hi, I'm Janvi, a data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex data sets.





