
The self-attention mechanism is a core component of transformer architectures that faces enormous challenges in both theoretical foundations and practical implementation. Despite these successes in natural language processing, computer vision, and other areas, their development often relies on heuristic approaches, limiting interpretability and scalability. Self-serving mechanisms are also vulnerable to data corruption and adversarial attacks, making them unreliable in practice. All of these issues need to be addressed to improve the robustness and efficiency of transformer models.
Conventional self-attention techniques, including softmax attention, obtain weighted averages based on similarity to establish dynamic relationships between input tokens. Although these methods are effective, they encounter important limitations. The lack of a formalized framework makes it difficult to adapt and understand its underlying processes. Furthermore, self-attention mechanisms show a tendency to decrease performance in the presence of adverse or noisy circumstances. Finally, significant computational demands restrict its application in environments characterized by limited resources. These limitations require computationally efficient and theoretically principled methods that are robust to data anomalies.
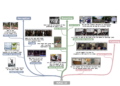
Researchers from the National University of Singapore propose an innovative reinterpretation of self-care using Kernel Principal Component Analysis (KPCA), establishing a comprehensive theoretical framework. This new interpretation presents several key contributions. It mathematically reframes self-attention as a projection of query vectors onto the principal component axes of the key matrix into a feature space, making it more interpretable. Furthermore, it is shown that the value matrix encodes the eigenvectors of the Gram matrix of key vectors, establishing a close link between self-attention and KPCA principles. The researchers present a robust mechanism to address vulnerabilities in data: Robust Principal Component Attention (RPC-Attention). Using Principal Component Search (PCP) to distinguish uncontaminated data from distortions in the primary matrix significantly strengthens resilience. This methodology creates a connection between theoretical precision and practical improvements, thus increasing the effectiveness and reliability of self-care mechanisms.
The construction incorporates multiple sophisticated technical components. Within the KPCA framework, query vectors are oriented with the principal component axes according to their representation in the feature space. Principal component search is applied to decompose the primary matrix into sparse and low-rank components that mitigate the problems created by data corruption. An efficient implementation is achieved by carefully replacing the softmax attention with a more robust alternative mechanism in certain layers of the transformer that balance efficiency and robustness. This is validated by extensive testing on classification datasets such as ImageNet-1K, segmentation datasets such as ADE20K, and language modeling such as WikiText-103, demonstrating the versatility of the approach across multiple domains.
The work significantly improves precision, robustness and resilience in different tasks. The mechanism improves object classification accuracy and error rates in corruption and adversarial attack situations. In language modeling, he demonstrates reduced perplexity, reflecting improved linguistic understanding. Its use in image segmentation exhibits superior performance on both clean and noisy datasets, supporting its adaptability to various challenges. These results illustrate its potential to overcome the critical limitations of traditional self-care methods.
Researchers reframe self-attention through KPCA, thereby providing a principled theoretical foundation and a resilient attention mechanism to address data vulnerabilities and computational challenges. The contributions greatly improve the understanding and capabilities of transformer architectures to develop more robust and efficient ai applications.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn actionable insights to improve LLM model performance and accuracy while protecting data privacy..
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}