
Today, large language models (LLM) are being integrated with multi-agent systems, where multiple intelligent agents collaborate to achieve a unified goal. Multi-agent frameworks are designed to improve problem solving, improve decision making, and optimize the capability of ai systems. to address diverse user needs. By distributing responsibilities among agents, these systems ensure better task execution and offer scalable solutions. They are valuable in applications such as customer service, where accurate responses and adaptability are paramount.
However, to implement these multi-agent systems, it is necessary to create realistic and scalable data sets for testing and training. The scarcity of domain-specific data and privacy concerns surrounding proprietary information limit the ability to train ai systems effectively. Additionally, customer-facing ai agents must maintain logical and correct reasoning when navigating through sequences of actions or trajectories to arrive at solutions. This process often involves calls to external tools, resulting in errors if the wrong sequence or parameters are used. These inaccuracies lead to lower user confidence and system reliability, creating a critical need for more robust methods to verify agent trajectories and generate realistic test data sets.
Traditionally, addressing these challenges involved relying on human-labeled data or leveraging LLMs as judges to verify trajectories. While LLM-based solutions have shown promise, they face significant limitations, including sensitivity to input requests, inconsistent results from API-based models, and high operational costs. Furthermore, these approaches are time-consuming and need to be scaled up more effectively, especially when applied to complex domains that demand accurate and context-aware responses. As a consequence, There is an urgent need for a cost-effective and deterministic solution to validate ai agent behaviors and ensure reliable results..
Researchers at Splunk Inc. have proposed an innovative framework called MAG-V (METROulti-TOGent framework for synthetic data GRAMgeneration and Verification), which aims to overcome these limitations. MAG-V is a multi-agent system designed to generate synthetic data sets and verify the trajectories of ai agents. The framework introduces a novel approach that combines classic machine learning techniques with advanced LLM capabilities. Unlike traditional systems, MAG-V does not rely on LLMs as feedback mechanisms. Instead, it uses deterministic methods and machine learning models to ensure accuracy and scalability in trajectory verification.
MAG-V uses three specialized agents:
- A researcher: The researcher generates questions that mimic realistic customer queries.
- An assistant: the assistant responds based on predefined trajectories
- Reverse engineering: Reverse engineering creates alternative questions from the wizard's answers.
This process allows the framework to generate synthetic data sets that test the wizard's capabilities. The team started with an initial data set of 19 questions and expanded it to 190 synthetic questions through an iterative process. After rigorous filtering, 45 high-quality questions were selected for the test. Each question was run five times to identify the most common trajectory, ensuring the reliability of the data set.
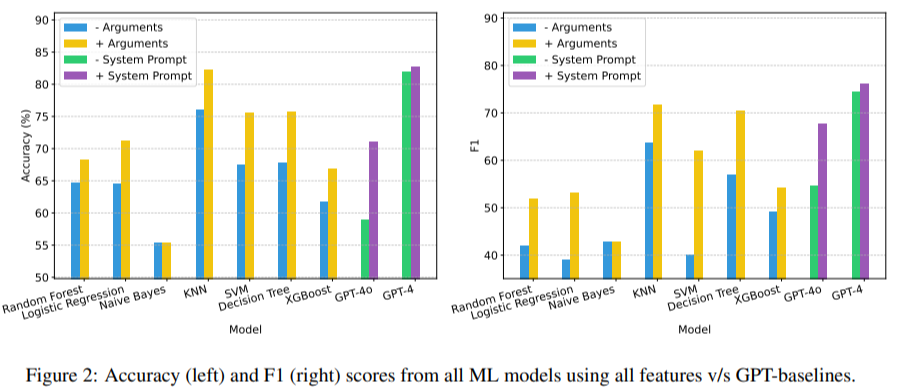
MAG-V employs semantic similarity, graph editing distance, and argument overlap to verify trajectories. These features train machine learning models such as k-Nearest Neighbors (k-NN), support vector machines (SVM), and random forests. The framework was successful in its evaluation, outperforming the GPT-4o judges' baselines with 11% accuracy and matching the performance of GPT-4 on several metrics. For example, MAG-V's k-NN model achieved an accuracy of 82.33% and demonstrated an F1 score of 71.73. The approach also demonstrated cost-effectiveness by combining cheaper models such as GPT-4o-mini with in-context learning samples, guiding them to perform at levels comparable to more expensive LLMs.
The MAG-V framework delivers results by addressing critical challenges in trajectory verification. Its deterministic nature ensures consistent results, eliminating the variability associated with LLM-based approaches. By generating synthetic data sets, MAG-V reduces reliance on real customer data, addressing privacy concerns and data scarcity. The framework's ability to verify trajectories using statistical and integration-based features represents progress in ai system reliability. Additionally, MAG-V's reliance on alternative questions for trajectory verification provides a robust method for testing and validating the reasoning pathways of ai agents.
Several key takeaways from the research on MAG-V are as follows:
- MAG-V generated 190 synthetic questions from an initial data set of 19, filtering them into 45 high-quality queries. This process demonstrated the potential of creating scalable data to support ai testing and training.
- The framework's deterministic methodology eliminates reliance on LLM approaches as a judge, delivering consistent and reproducible results.
- Machine learning models trained with MAG-V features achieved accuracy improvements of up to 11% over GPT-4o baselines, demonstrating the effectiveness of the approach.
- By integrating in-context learning with cheaper LLMs like GPT-4o-mini, MAG-V provided a cost-effective alternative to high-end models without compromising performance.
- The framework is adaptable to multiple domains and demonstrates scalability by leveraging alternative questions to validate trajectories.
In conclusion, the MAG-V framework effectively addresses critical challenges in synthetic data generation and trajectory verification for ai systems. The framework offers a scalable, cost-effective and deterministic solution by integrating multi-agent systems with classic machine learning models such as k-NN, SVM and Random Forests. MAG-V's ability to generate high-quality synthetic data sets and accurately verify trajectories makes it considered for implementing reliable ai applications.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
(You must subscribe): Subscribe to our newsletter to receive updates on ai research and development
Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and artificial intelligence to address real-world challenges. With a strong interest in solving practical problems, he brings a new perspective to the intersection of ai and real-life solutions.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}