
Con acceso a una amplia gama de modelos básicos de IA generativa (FM) y la capacidad de crear y entrenar sus propios modelos de aprendizaje automático (ML) en amazon SageMaker, los usuarios quieren una manera segura y fluida de experimentar y seleccionar los modelos que ofrecen el mayor valor para su negocio. En las etapas iniciales de un proyecto de aprendizaje automático, los científicos de datos colaboran estrechamente y comparten resultados experimentales para abordar los desafíos comerciales. Sin embargo, realizar un seguimiento de numerosos experimentos, sus parámetros, métricas y resultados puede resultar difícil, especialmente cuando se trabaja en proyectos complejos simultáneamente. flujo mluna popular herramienta de código abierto, ayuda a los científicos de datos a organizar, rastrear y analizar experimentos de aprendizaje automático e inteligencia artificial generativa, lo que facilita la reproducción y comparación de resultados.
SageMaker es un servicio de ML integral y totalmente administrado diseñado para proporcionar a los científicos de datos y a los ingenieros de ML las herramientas que necesitan para manejar todo el flujo de trabajo de ML. amazon SageMaker con MLflow es una capacidad de SageMaker que permite a los usuarios crear, administrar, analizar y comparar sus experimentos de aprendizaje automático sin problemas. Simplifica las tareas, a menudo complejas y que requieren mucho tiempo, involucradas en la configuración y administración de un entorno MLflow, lo que permite a los administradores de ML establecer rápidamente entornos MLflow seguros y escalables en AWS. Consulte MLFlow totalmente administrado en amazon SageMaker para obtener más detalles.
Seguridad mejorada: AWS VPC y AWS PrivateLink
Cuando trabaja con SageMaker, puede decidir el nivel de acceso a Internet que desea proporcionar a sus usuarios. Por ejemplo, puede otorgar permiso de acceso a los usuarios para descargar paquetes populares y personalizar el entorno de desarrollo. Sin embargo, esto también puede introducir riesgos potenciales de acceso no autorizado a sus datos. Para mitigar estos riesgos, puede restringir aún más qué tráfico puede acceder a Internet iniciando su entorno de aprendizaje automático en una nube privada virtual de amazon (amazon VPC). Con una VPC de amazon, puede controlar el acceso a la red y la conectividad a Internet de su entorno SageMaker, o incluso eliminar el acceso directo a Internet para agregar otra capa de seguridad. Consulte Conexión a SageMaker a través de un punto final de interfaz de VPC para comprender las implicaciones de ejecutar SageMaker dentro de una VPC y las diferencias al utilizar el aislamiento de red.
SageMaker con MLflow ahora es compatible con AWS PrivateLink, que le permite transferir datos críticos desde su VPC a Servidores de seguimiento de MLflow a través de un punto final de VPC. Esta capacidad mejora la protección de la información confidencial al garantizar que los datos enviados a los servidores de seguimiento de MLflow se transfieran dentro de la red de AWS, evitando la exposición a la Internet pública. Esta capacidad está disponible en todas las regiones de AWS donde SageMaker está disponible actualmente, excepto las regiones de China y las regiones de GovCloud (EE. UU.). Para obtener más información, consulte Conexión a un servidor de seguimiento de MLflow a través de un extremo de interfaz VPC.
En esta publicación de blog, demostramos un caso de uso para configurar un fabricante de salvia ambiente en un VPC privada (sin acceso a Internet), mientras usa flujo ml capacidades para acelerar la experimentación de ML.
Descripción general de la solución
Puede encontrar el código de referencia para este ejemplo en GitHub. Los pasos de alto nivel son los siguientes:
- Implemente infraestructura con el kit de desarrollo en la nube de AWS (AWS CDK), que incluye:
- Ejecute la experimentación de ML con MLflow usando el decorador @remote desde el código abierto SDK de Python de SageMaker.
La arquitectura general de la solución se muestra en la siguiente figura.
Para su referencia, esta publicación de blog muestra una solución para crear una VPC sin conexión a Internet utilizando una plantilla de AWS CloudFormation.
Requisitos previos
Necesita una cuenta de AWS con un rol de AWS Identity and Access Management (IAM) con permisos para administrar los recursos creados como parte de la solución. Para obtener más información, consulte Creación de una cuenta de AWS.
Implemente infraestructura con AWS CDK
El primer paso es crear la infraestructura utilizando esta pila de CDK. Puede seguir las instrucciones de implementación desde el LÉAME.
Primero echemos un vistazo más de cerca a la pila CDK.
Define varios puntos de enlace de VPC, incluido el punto de enlace de MLflow, como se muestra en el siguiente ejemplo:
vpc.add_interface_endpoint(
"mlflow-experiments",
service=ec2.InterfaceVpcEndpointAwsService.SAGEMAKER_EXPERIMENTS,
private_dns_enabled=True,
subnets=ec2.SubnetSelection(subnets=subnets),
security_groups=(studio_security_group)
)También intentamos restringir la función IAM de ejecución de SageMaker para que pueda usar SageMaker MLflow solo cuando esté en la VPC correcta.
Puede restringir aún más el punto de enlace de la VPC para MLflow adjuntando una política de punto de enlace de la VPC.
Los usuarios fuera de la VPC pueden potencialmente conectarse a Sagemaker MLflow a través del punto final de la VPC a MLflow. Puede agregar restricciones para que el acceso de los usuarios a SageMaker MLflow solo esté permitido desde su VPC.
studio_execution_role.attach_inline_policy(
iam.Policy(self, "mlflow-policy",
statements=(
iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=("sagemaker-mlflow:*"),
resources=("*"),
conditions={"StringEquals": {"aws:SourceVpc": vpc.vpc_id } }
)
)
)
)Después de una implementación exitosa, debería poder ver el nuevo VPC en AWS Management Console para amazon VPC sin acceso a Internet, como se muestra en la siguiente captura de pantalla.
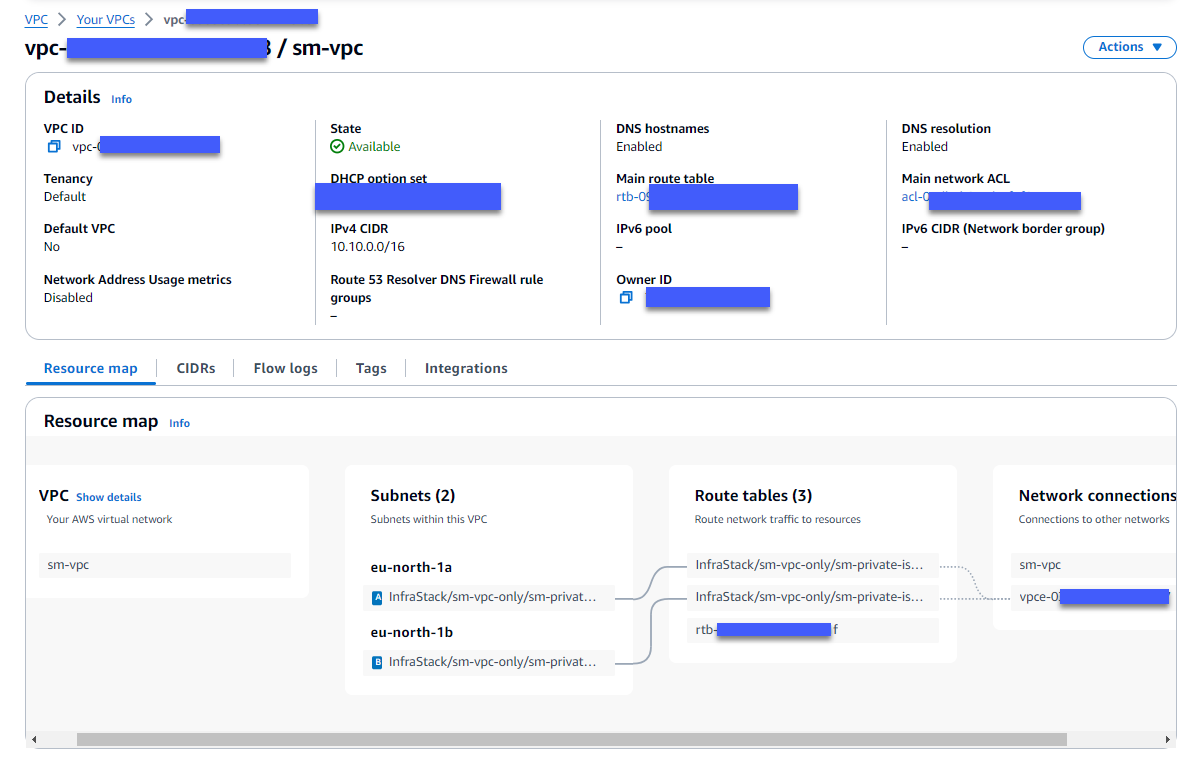
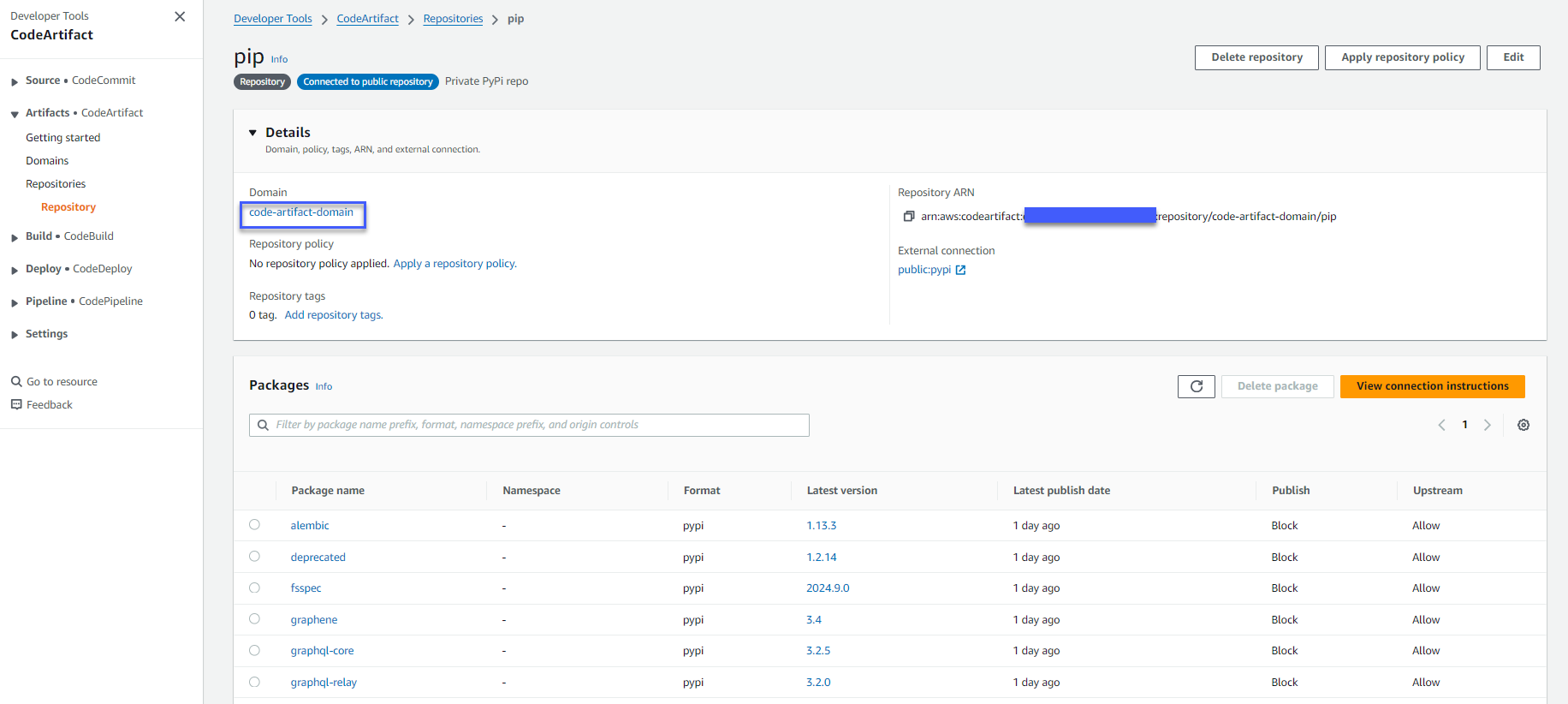
A Dominio CodeArtifact y un Repositorio CodeArtifact con conexión externa a PyPI También debe crearse, como se muestra en la siguiente figura, para que SageMaker pueda usarlo para descargar los paquetes necesarios sin acceso a Internet. Puede verificar la creación del dominio y el repositorio yendo a la consola CodeArtifact. Elija “Repositorios” en “Artefactos” en el panel de navegación y verá el repositorio “pip”.
Experimentación de aprendizaje automático con MLflow
Configuración
Después de la creación de la pila CDK, una nueva Dominio SageMaker con un perfil de usuario también debería crearse. Inicie amazon SageMaker Studio y cree un espacio JupyterLab. En el espacio JupyterLab, elija un tipo de instancia de ml.t3.mediumy seleccione una imagen con SageMaker Distribution 2.1.0.
Para verificar que el entorno SageMaker no tiene conexión a Internet, abra el espacio JupyterLab y verifique la conexión a Internet ejecutando el rizo comando en una terminal.

SageMaker con MLflow ahora es compatible con la versión MLflow 2.16.2 para acelerar los flujos de trabajo generativos de IA y ML desde la experimentación hasta la producción. Un flujo de aprendizaje automático 2.16.2 El servidor de seguimiento se crea junto con la pila CDK.
Puedes encontrar el Nombre de recurso de amazon (ARN) del servidor de seguimiento de MLflow ya sea desde la salida del CDK o desde la interfaz de usuario de SageMaker Studio haciendo clic en el icono “MLFlow”, como se muestra en la siguiente figura. Puede hacer clic en el botón “copiar” junto al “servidor mlflow” para copiar el ARN del servidor de seguimiento de MLflow.

Como conjunto de datos de ejemplo para entrenar el modelo, descargue el conjunto de datos de referencia del público Repositorio de aprendizaje automático de UC Irvine a su PC local y asígnele un nombre predictive_maintenance_raw_data_header.csv.
Cargue el conjunto de datos de referencia desde su PC local a su JupyterLab Space como se muestra en la siguiente figura.
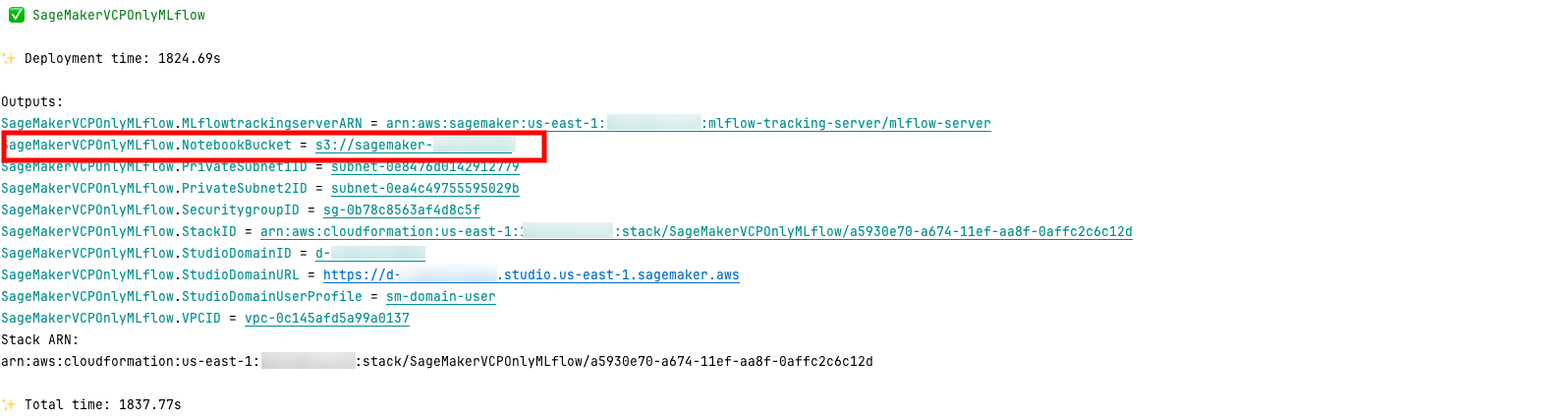
Para probar su conectividad privada con el servidor de seguimiento de MLflow, puede descargar el cuaderno de muestra que se cargó automáticamente durante la creación de la pila en un depósito dentro de su cuenta de AWS. Puede encontrar el nombre de un depósito S3 en la salida del CDK, como se muestra en la siguiente figura.
Desde la terminal de la aplicación JupyterLab, ejecute el siguiente comando:
aws s3 cp --recursive ./Ahora puedes abrir el privado-mlflow.ipynb computadora portátil.
En la primera celda, obtenga las credenciales para el repositorio CodeArtifact PyPI para que SageMaker pueda usar pip del repositorio privado AWS CodeArtifact. Las credenciales caducarán en 12 horas. Asegúrese de iniciar sesión nuevamente cuando caduquen.
%%bash
AWS_ACCOUNT=$(aws sts get-caller-identity --output text --query 'Account')
aws codeartifact login --tool pip --repository pip --domain code-artifact-domain --domain-owner ${AWS_ACCOUNT} --region ${AWS_DEFAULT_REGION}Experimentación
Después de la configuración, comience la experimentación. El escenario está utilizando el XGBoost Algoritmo para entrenar un modelo de clasificación binaria. Tanto el trabajo de procesamiento de datos como el uso del trabajo de entrenamiento de modelos. @decorador remoto para que los trabajos se ejecuten en las subredes privadas y el grupo de seguridad asociados a SageMaker desde su VPC privada.
En este caso, el decorador @remote busca los valores de los parámetros de SageMaker. archivo de configuración (config.yaml). Estos parámetros se utilizan para el procesamiento de datos y trabajos de capacitación. Definimos las subredes privadas y el grupo de seguridad asociados a SageMaker en el archivo de configuración. Para obtener la lista completa de configuraciones admitidas para el decorador @remote, consulte Archivo de configuración en la Guía para desarrolladores de SageMaker.
Tenga en cuenta que especificamos en PreExecutionCommands el aws codeartifact login comando para señalar a SageMaker al repositorio privado de CodeAritifact. Esto es necesario para garantizar que las dependencias se puedan instalar en tiempo de ejecución. Alternativamente, puede pasar una referencia a un contenedor en su amazon ECR a través de ImageUrique contiene todas las dependencias instaladas.
Especificamos el grupo de seguridad y la información de subredes en VpcConfig.
config_yaml = f"""
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
TelemetryOptOut: true
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn:
# ImageUri:
S3RootUri: s3://{bucket_prefix}
InstanceType: ml.m5.xlarge
Dependencies: ./requirements.txt
IncludeLocalWorkDir: true
PreExecutionCommands:
- "aws codeartifact login --tool pip --repository pip --domain code-artifact-domain --domain-owner {account_id} --region {region}"
CustomFileFilter:
IgnoreNamePatterns:
- "data/*"
- "models/*"
- "*.ipynb"
- "__pycache__"
VpcConfig:
SecurityGroupIds:
- {security_group_id}
Subnets:
- {private_subnet_id_1}
- {private_subnet_id_2}
"""A continuación se explica cómo configurar un experimento de MLflow similar a este.
from time import gmtime, strftime
# Mlflow (replace these values with your own, if needed)
project_prefix = project_prefix
tracking_server_arn = mlflow_arn
experiment_name = f"{project_prefix}-sm-private-experiment"
run_name=f"run-{strftime('%d-%H-%M-%S', gmtime())}"Preprocesamiento de datos
Durante el procesamiento de datos, utilizamos el @remote decorador para vincular parámetros en configuración.yaml a tu preprocess función.
Tenga en cuenta que el seguimiento de MLflow comienza desde el mlflow.start_run() API.
El mlflow.autolog() La API puede registrar automáticamente información como métricas, parámetros y artefactos.
puedes usar log_input() método para registrar un conjunto de datos en el almacén de artefactos de MLflow.
@remote(keep_alive_period_in_seconds=3600, job_name_prefix=f"{project_prefix}-sm-private-preprocess")
def preprocess(df, df_source: str, experiment_name: str):
mlflow.set_tracking_uri(tracking_server_arn)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=f"Preprocessing") as run:
mlflow.autolog()
columns = ('Type', 'Air temperature (K)', 'Process temperature (K)', 'Rotational speed (rpm)', 'Torque (Nm)', 'Tool wear (min)', 'Machine failure')
cat_columns = ('Type')
num_columns = ('Air temperature (K)', 'Process temperature (K)', 'Rotational speed (rpm)', 'Torque (Nm)', 'Tool wear (min)')
target_column = 'Machine failure'
df = df(columns)
mlflow.log_input(
mlflow.data.from_pandas(df, df_source, targets=target_column),
context="DataPreprocessing",
)
...
model_file_path="/opt/ml/model/sklearn_model.joblib"
os.makedirs(os.path.dirname(model_file_path), exist_ok=True)
joblib.dump(featurizer_model, model_file_path)
return X_train, y_train, X_val, y_val, X_test, y_test, featurizer_modelEjecute el trabajo de preprocesamiento y luego vaya a la interfaz de usuario de MLflow (que se muestra en la siguiente figura) para ver el trabajo de preprocesamiento rastreado con el conjunto de datos de entrada.
X_train, y_train, X_val, y_val, X_test, y_test, featurizer_model = preprocess(df=df,
df_source=input_data_path,
experiment_name=experiment_name)Puede abrir una interfaz de usuario de MLflow desde SageMaker Studio como se muestra en la siguiente figura. Haga clic en “Experimentos” en el panel de navegación y seleccione su experimento.
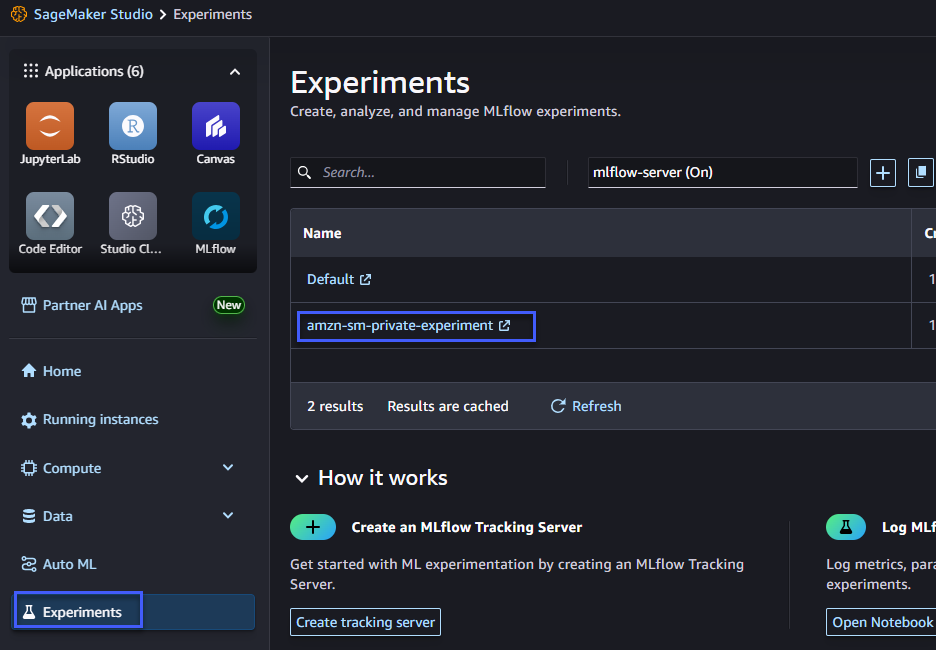
Desde la interfaz de usuario de MLflow, puede ver el trabajo de procesamiento que se acaba de ejecutar.

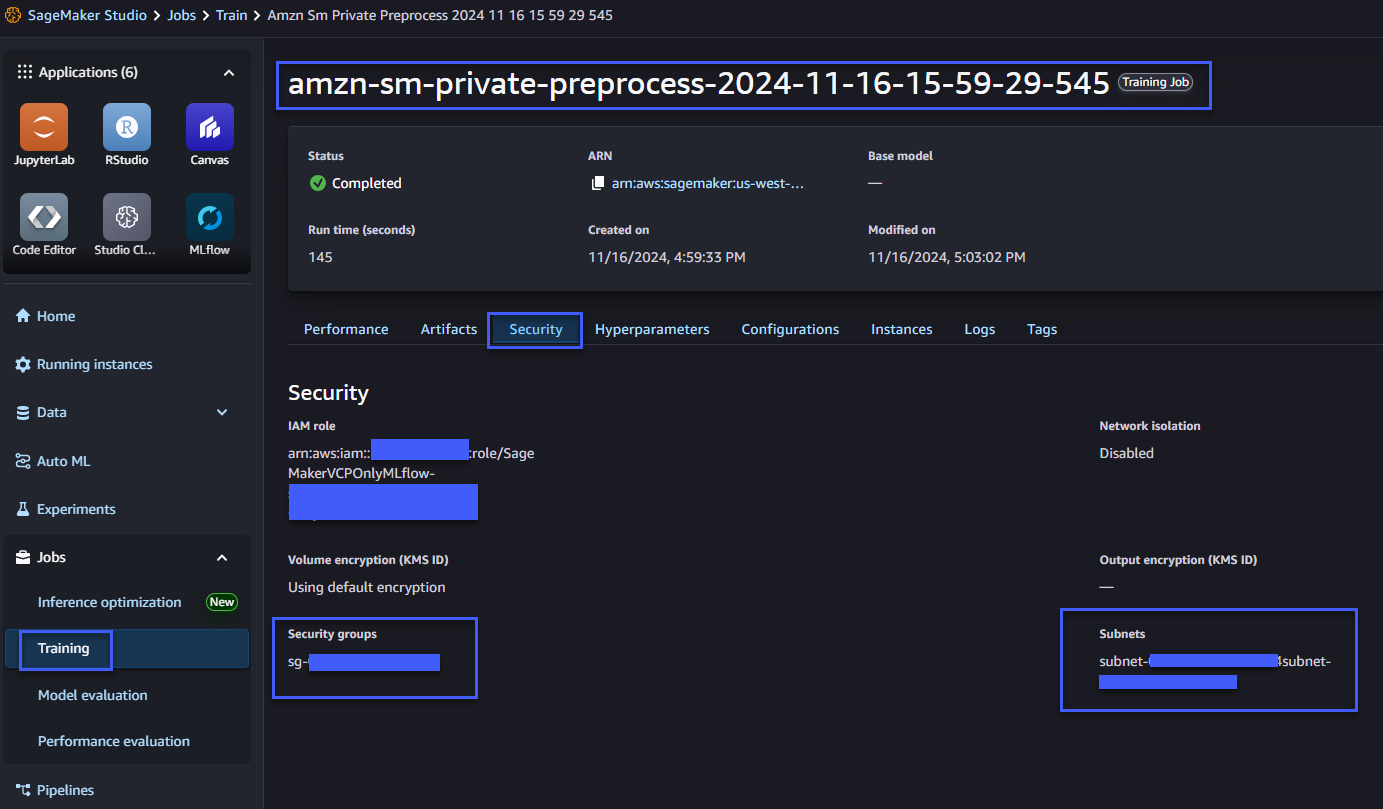
También puede ver los detalles de seguridad en la consola de SageMaker Studio en el trabajo de capacitación correspondiente, como se muestra en la siguiente figura.
Entrenamiento modelo
De forma similar al trabajo de procesamiento de datos, también puedes utilizar @remote decorador con el trabajo de formación.
Tenga en cuenta que el log_metrics() El método envía las métricas definidas al servidor de seguimiento de MLflow.
@remote(keep_alive_period_in_seconds=3600, job_name_prefix=f"{project_prefix}-sm-private-train")
def train(X_train, y_train, X_val, y_val,
eta=0.1,
max_depth=2,
gamma=0.0,
min_child_weight=1,
verbosity=0,
objective="binary:logistic",
eval_metric="auc",
num_boost_round=5):
mlflow.set_tracking_uri(tracking_server_arn)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=f"Training") as run:
mlflow.autolog()
# Creating DMatrix(es)
dtrain = xgboost.DMatrix(X_train, label=y_train)
dval = xgboost.DMatrix(X_val, label=y_val)
watchlist = ((dtrain, "train"), (dval, "validation"))
print('')
print (f'===Starting training with max_depth {max_depth}===')
param_dist = {
"max_depth": max_depth,
"eta": eta,
"gamma": gamma,
"min_child_weight": min_child_weight,
"verbosity": verbosity,
"objective": objective,
"eval_metric": eval_metric
}
xgb = xgboost.train(
params=param_dist,
dtrain=dtrain,
evals=watchlist,
num_boost_round=num_boost_round)
predictions = xgb.predict(dval)
print ("Metrics for validation set")
print('')
print (pd.crosstab(index=y_val, columns=np.round(predictions),
rownames=('Actuals'), colnames=('Predictions'), margins=True))
rounded_predict = np.round(predictions)
val_accuracy = accuracy_score(y_val, rounded_predict)
val_precision = precision_score(y_val, rounded_predict)
val_recall = recall_score(y_val, rounded_predict)
# Log additional metrics, next to the default ones logged automatically
mlflow.log_metric("Accuracy Model A", val_accuracy * 100.0)
mlflow.log_metric("Precision Model A", val_precision)
mlflow.log_metric("Recall Model A", val_recall)
from sklearn.metrics import roc_auc_score
val_auc = roc_auc_score(y_val, predictions)
mlflow.log_metric("Validation AUC A", val_auc)
model_file_path="/opt/ml/model/xgboost_model.bin"
os.makedirs(os.path.dirname(model_file_path), exist_ok=True)
xgb.save_model(model_file_path)
return xgbDefina hiperparámetros y ejecute el trabajo de entrenamiento.
eta=0.3
max_depth=10
booster = train(X_train, y_train, X_val, y_val,
eta=eta,
max_depth=max_depth)En la interfaz de usuario de MLflow puede ver las métricas de seguimiento como se muestra en la siguiente figura. En la pestaña “Experimentos”, vaya al trabajo “Entrenamiento” de su tarea de experimento. Está en la pestaña “Descripción general”.
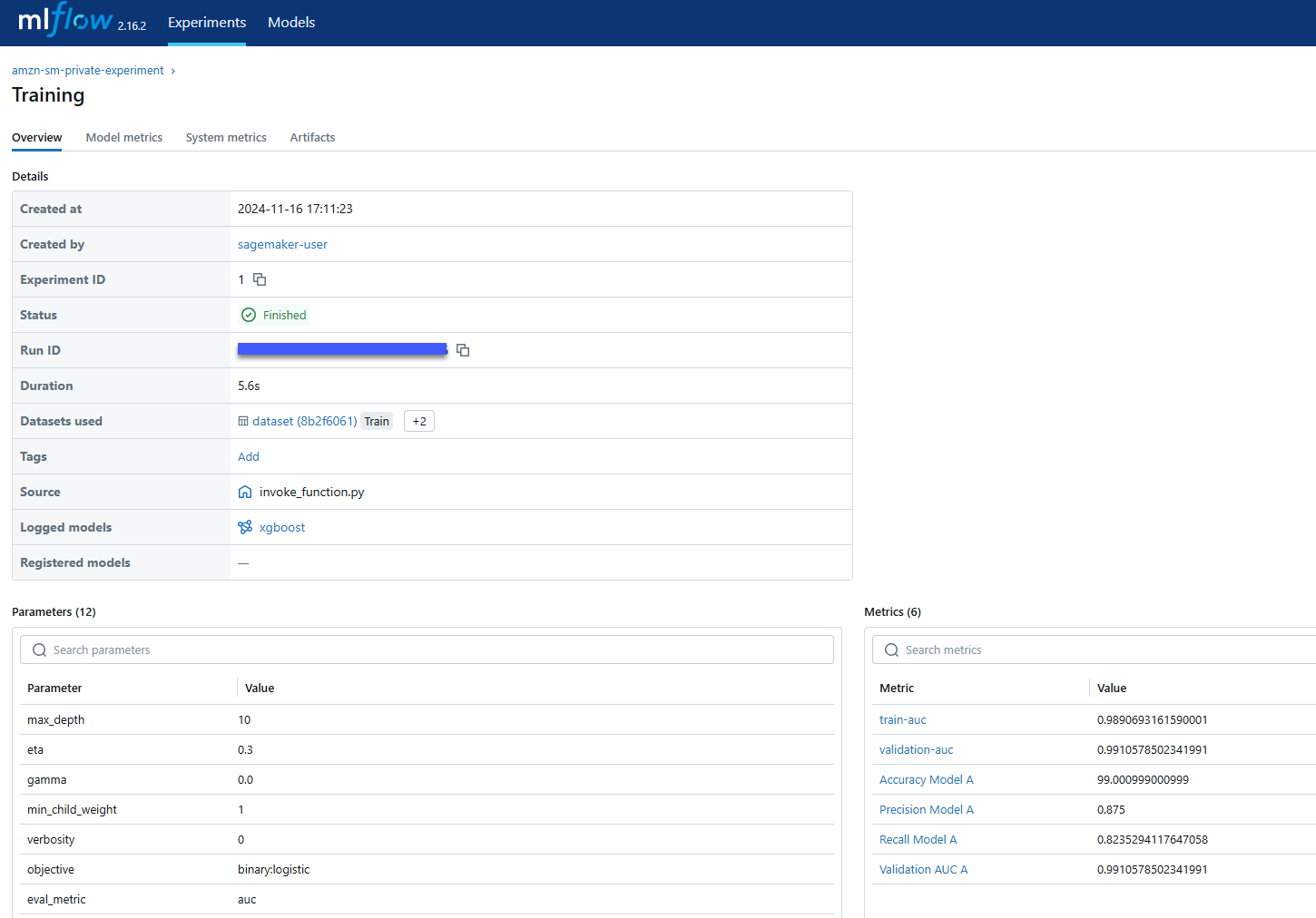
También puede ver las métricas como gráficos. En la pestaña “Métricas del modelo”, puede ver las métricas de rendimiento del modelo que se configuraron como parte del registro del trabajo de capacitación.
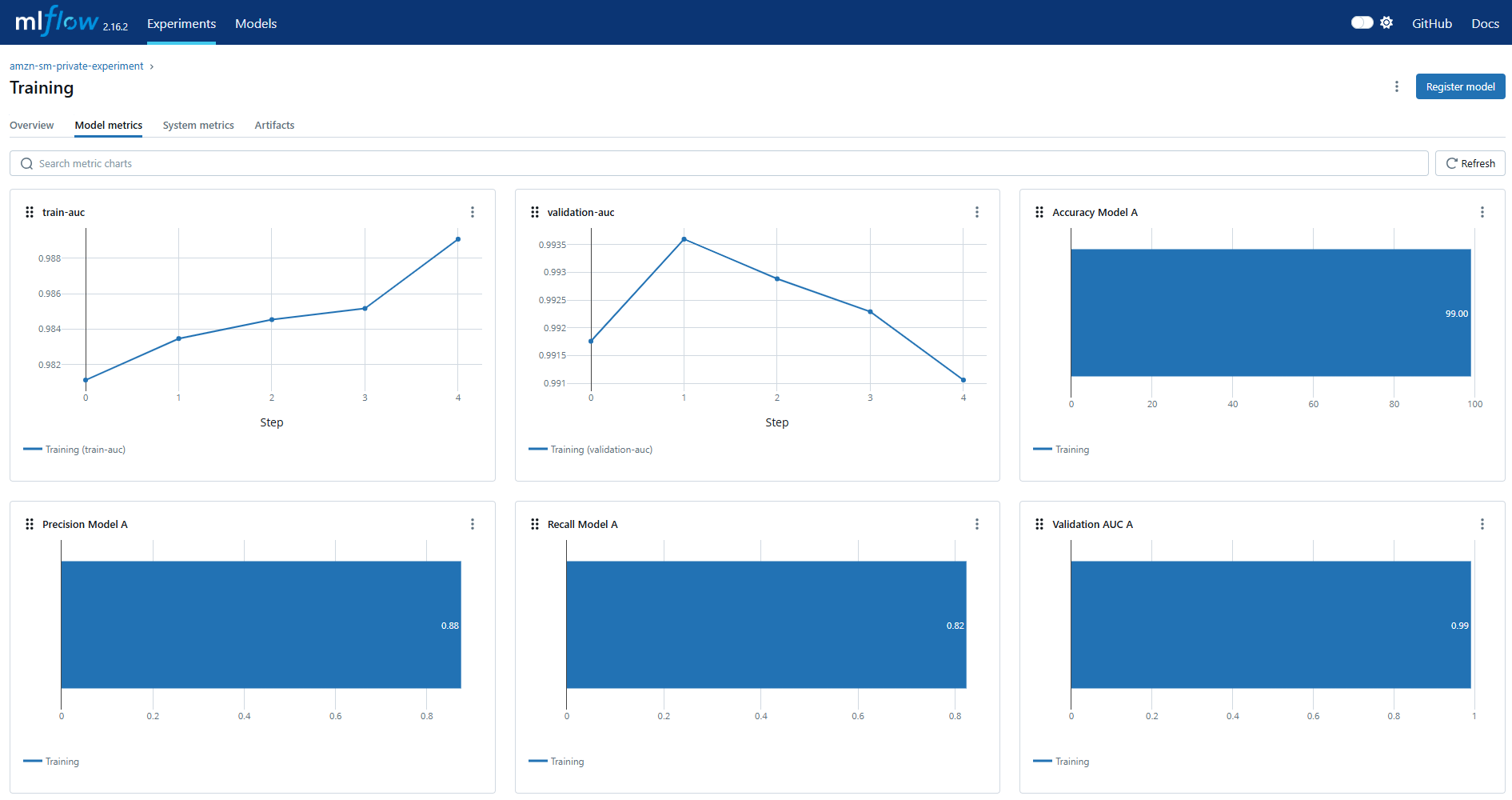
Con MLflow, puede registrar la información de su conjunto de datos junto con otras métricas clave, como hiperparámetros y evaluación de modelos. Encuentre más detalles en la publicación del blog Experimentación de LLM con MLFlow.
Limpiar
Para limpiar, primero elimine todos los espacios y aplicaciones creados dentro del dominio de SageMaker Studio. Luego destruya la infraestructura creada ejecutando el siguiente código.
cdk destroyConclusión
SageMaker con MLflow permite a los profesionales de ML crear, administrar, analizar y comparar experimentos de ML en AWS. Para mejorar la seguridad, SageMaker con MLflow ahora admite Enlace privado de AWS. Todas las versiones de MLflow Tracking Server, incluidas 2.16.2 Integre perfectamente con esta función, lo que permite una comunicación segura entre sus entornos de aprendizaje automático y los servicios de AWS sin exponer los datos a la Internet pública.
Para obtener una capa adicional de seguridad, puede configurar SageMaker Studio dentro de su VPC privada sin acceso a Internet y ejecutar sus experimentos de aprendizaje automático en este entorno.
SageMaker con MLflow ahora es compatible con MLflow 2.16.2. Configurar una instalación nueva proporciona la mejor experiencia y compatibilidad total con las funciones más recientes.
Acerca de los autores
 Xiaoyu Xing es arquitecto de soluciones en AWS. La impulsa una profunda pasión por la Inteligencia Artificial (IA) y el Aprendizaje Automático (ML). Se esfuerza por cerrar la brecha entre estas tecnologías de vanguardia y una audiencia más amplia, capacitando a personas de diversos orígenes para que aprendan y aprovechen la IA y el aprendizaje automático con facilidad. Ayuda a los clientes a adoptar soluciones de IA y aprendizaje automático en AWS de forma segura y responsable.
Xiaoyu Xing es arquitecto de soluciones en AWS. La impulsa una profunda pasión por la Inteligencia Artificial (IA) y el Aprendizaje Automático (ML). Se esfuerza por cerrar la brecha entre estas tecnologías de vanguardia y una audiencia más amplia, capacitando a personas de diversos orígenes para que aprendan y aprovechen la IA y el aprendizaje automático con facilidad. Ayuda a los clientes a adoptar soluciones de IA y aprendizaje automático en AWS de forma segura y responsable.
 Paolo Di Francesco es arquitecto senior de soluciones en amazon Web Services (AWS). Es Doctor en Ingeniería de Telecomunicaciones y tiene experiencia en ingeniería de software. Le apasiona el aprendizaje automático y actualmente se centra en utilizar su experiencia para ayudar a los clientes a alcanzar sus objetivos en AWS, en particular en debates sobre MLOps. Fuera del trabajo, le gusta jugar al fútbol y leer.
Paolo Di Francesco es arquitecto senior de soluciones en amazon Web Services (AWS). Es Doctor en Ingeniería de Telecomunicaciones y tiene experiencia en ingeniería de software. Le apasiona el aprendizaje automático y actualmente se centra en utilizar su experiencia para ayudar a los clientes a alcanzar sus objetivos en AWS, en particular en debates sobre MLOps. Fuera del trabajo, le gusta jugar al fútbol y leer.
 Tomer Shenhar es gerente de producto en AWS. Se especializa en IA responsable, impulsado por la pasión de desarrollar soluciones de IA transparentes y éticamente sólidas.
Tomer Shenhar es gerente de producto en AWS. Se especializa en IA responsable, impulsado por la pasión de desarrollar soluciones de IA transparentes y éticamente sólidas.






{kind=link}