
Building generative ai applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. To address these challenges, we introduce amazon Bedrock IDE, an integrated environment for developing and customizing generative ai applications. Formerly known as amazon Bedrock Studio, amazon Bedrock IDE is now incorporated into the amazon SageMaker Unified Studio (currently in preview). SageMaker Unified Studio combines various AWS services, including amazon Bedrock, amazon SageMaker, amazon Redshift, amazon Glue, amazon Athena, and amazon Managed Workflows for Apache Airflow (MWAA), into a comprehensive data and ai development platform. In this blog post, we’ll focus on amazon Bedrock IDE and its generative ai capabilities within the amazon SageMaker Unified Studio environment.
Consider a global retail site operating across multiple regions and countries. Its sales analysts face a daily challenge: they need to make data-driven decisions but are overwhelmed by the volume of available information. They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. Without specialized structured query language (SQL) knowledge or Retrieval Augmented Generation (RAG) expertise, these analysts struggle to combine insights effectively from both sources.
In this post, we’ll show how anyone in your company can use amazon Bedrock IDE to quickly create a generative ai chat agent application that analyzes sales performance data. Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex data pipelines. The following diagram illustrates the conceptual architecture of an ai assistant with amazon Bedrock IDE.
Solution overview
The ai chat agent application combines structured and unstructured data analysis through amazon Bedrock IDE:
- For structured data: connects to sales records in amazon Athena, translating natural language into SQL queries
- For unstructured data: uses amazon Titan Text Embeddings and amazon OpenSearch to enable semantic search across customer reviews and marketing reports
The amazon Bedrock IDE interface seamlessly combines results from both sources, delivering comprehensive insights without requiring users to understand the underlying data structures or query languages. The following figure illustrates the workflow from initial user interaction to final response. For more details on the user interaction flow, check out our associated <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-ide-genai-demo” target=”_blank” rel=”noopener”>GitHub repository.
Solution architecture
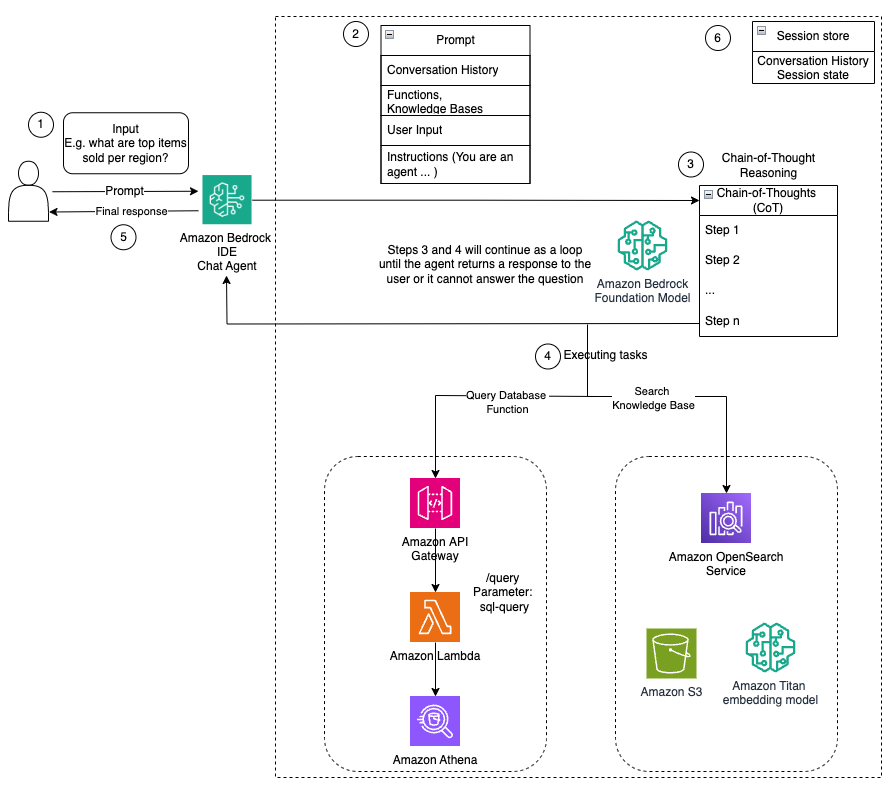
The architecture in the preceding figure shows how amazon Bedrock IDE orchestrates the data flow. When users pose questions through the natural language interface, the chat agent determines whether to query the structured data in amazon Athena through the amazon Bedrock IDE function, search the amazon Bedrock knowledge base, or combine both sources for comprehensive insights. This approach enables sales, marketing, product, and supply chain teams to make data-driven decisions efficiently, regardless of their technical expertise. For example, by the end of this tutorial, you will be able to query the data with prompts such as “Can you return our five top selling products this quarter and the principal customer complaints for each?” or “Were there any supply chain issues that could have affected our North American market for clothing sales?”
In the following sections, we’ll guide you through setting up your SageMaker Unified Studio project, creating your knowledge base, building the natural language query interface, and testing the solution.
SageMaker Unified Studio setup
SageMaker Unified Studio is a browser-based web application where you can use all your data and tools for analytics and ai. SageMaker Unified Studio can authenticate you with your AWS Identity and Access Management (IAM) credentials, credentials from your identity provider through the AWS IAM Identity Center, or with your SAML credentials.
You can obtain the SageMaker Unified Studio URL for your domains by accessing the AWS Management Console for amazon DataZone. Follow the steps in the Administrator Guide to set up your SageMaker Unified Studio.
Building a generative ai application
SageMaker Unified Studio offers tools to discover and build with generative ai. To get started, you need to build a project.
- Open SageMaker Unified Studio and choose Generative ai playground at the top of the page.
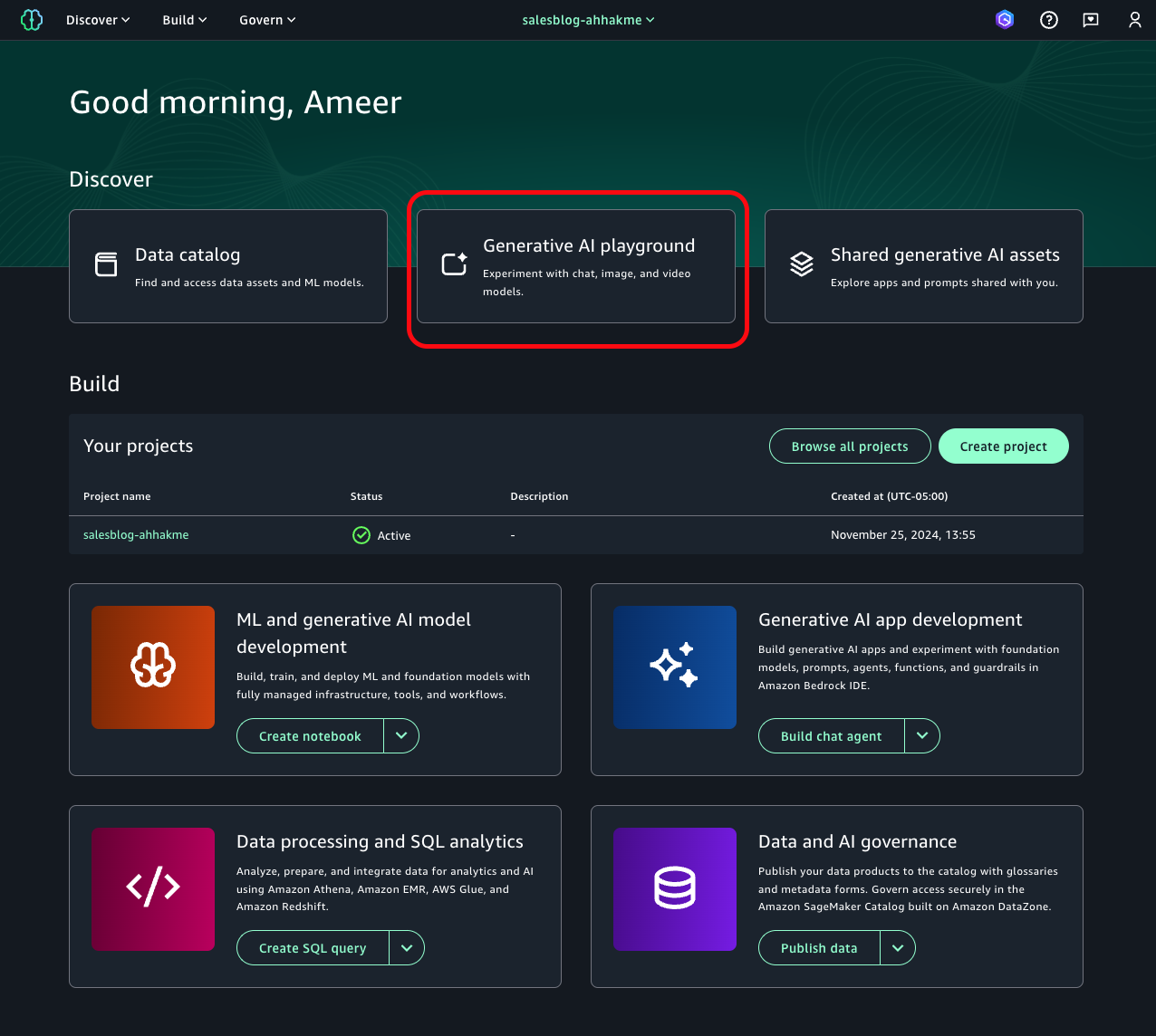
- Here, you can explore, experiment and compare various foundation models (FMs) through a chat interface.
<img loading="lazy" class="alignnone size-full wp-image-94725" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/12/1733756587_62_Build-generative-AI-applications-quickly-with-Amazon-Bedrock-IDE-in.png" alt="Bedrock IDE – Generative ai playground ” width=”1278″ height=”1190″/>
Similarly, you can explore image and video models with the Image & video playground.
- To begin creating your chat agent, choose Build chat agent in the chat playground window. You will now create a new project before building your app. Choose Create project.
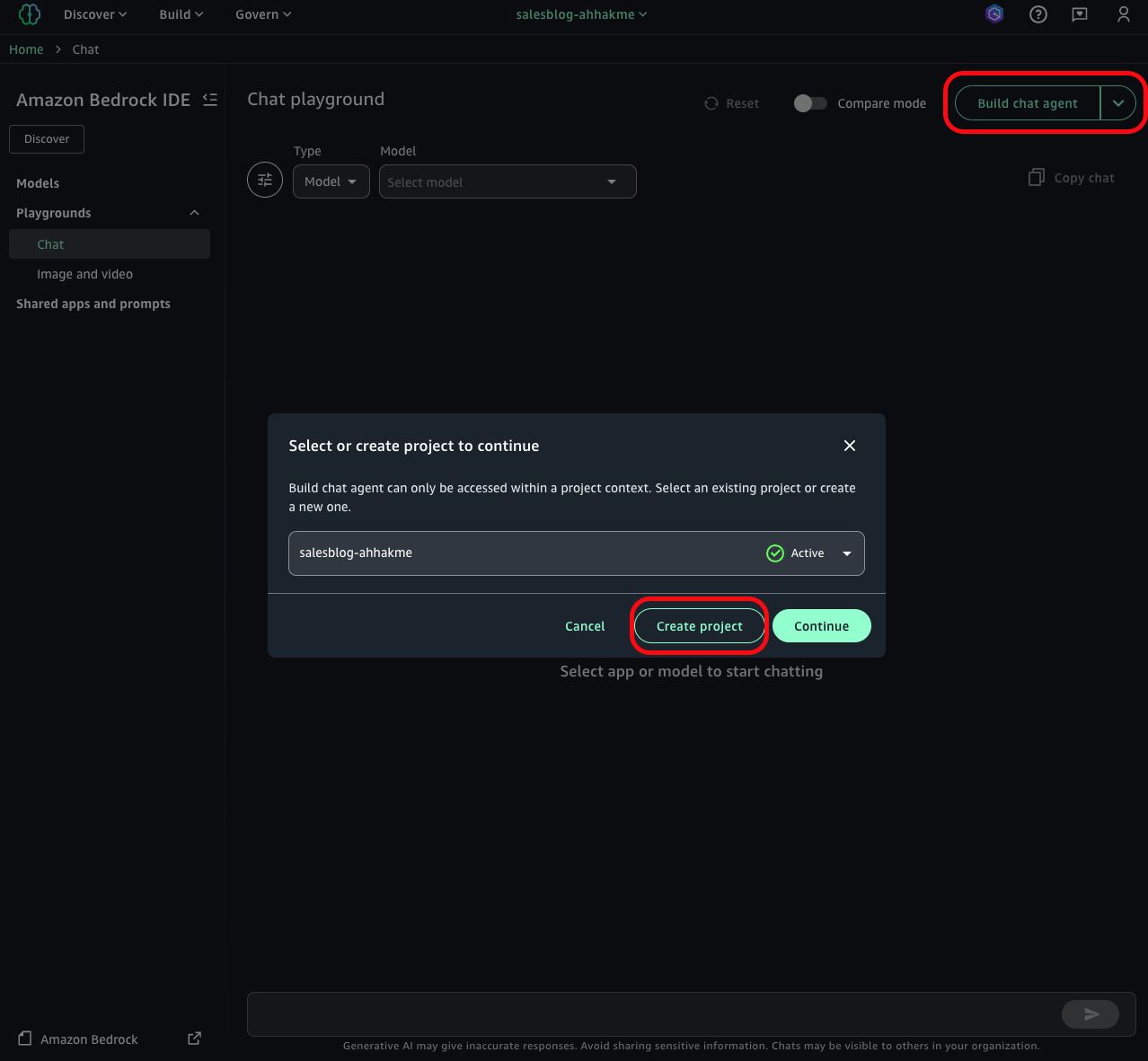
- Enter a project name. Next, select Generative ai application development from the available profiles. This profile includes all the necessary elements for working with amazon Bedrock components in your generative ai application development. Choose Continue.
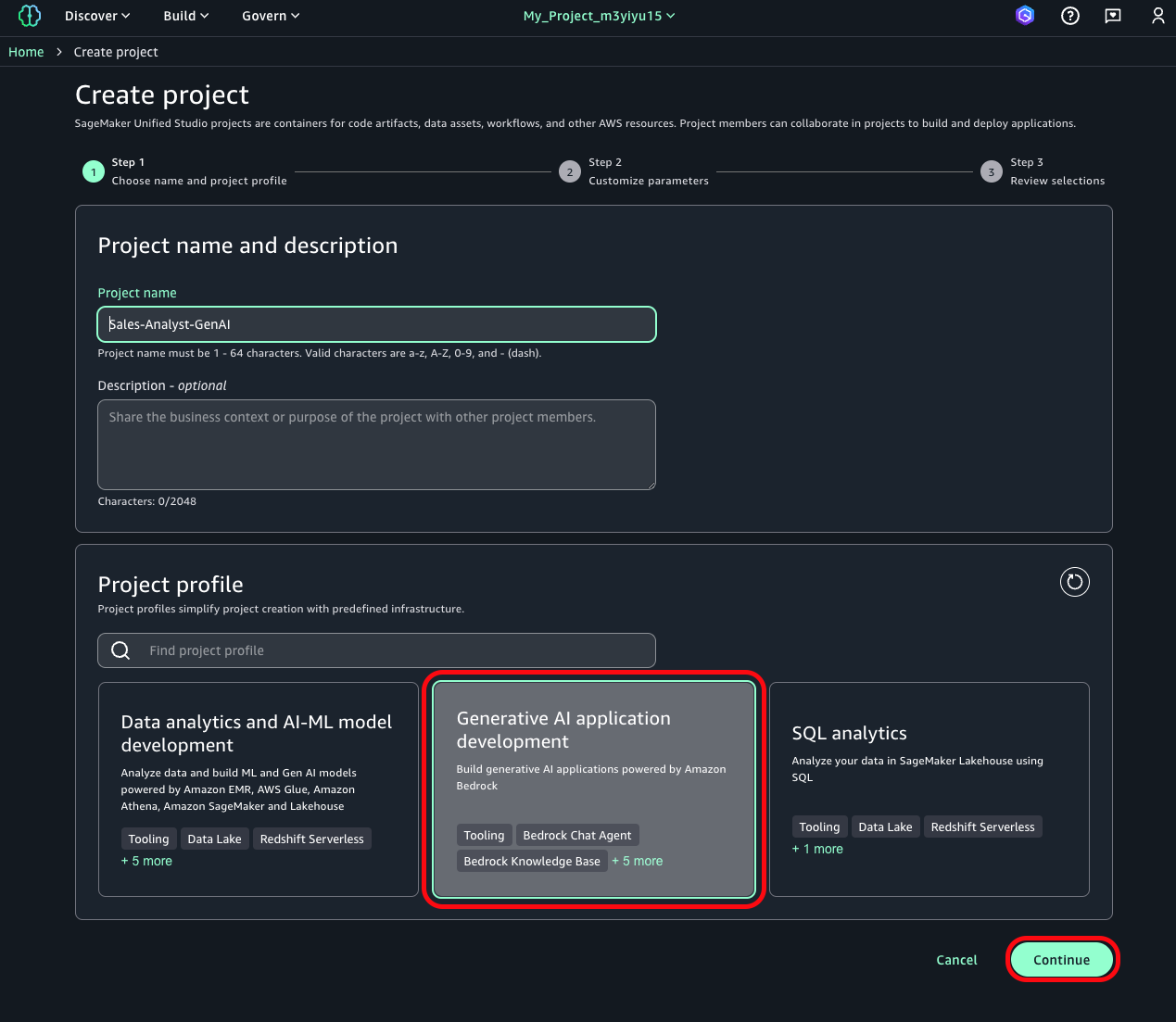
- On the next screen, leave all settings at their default values. Choose Continue to move to the next screen and choose the Create Project button to initiate the project creation process. The system will take a few minutes to set up your project.
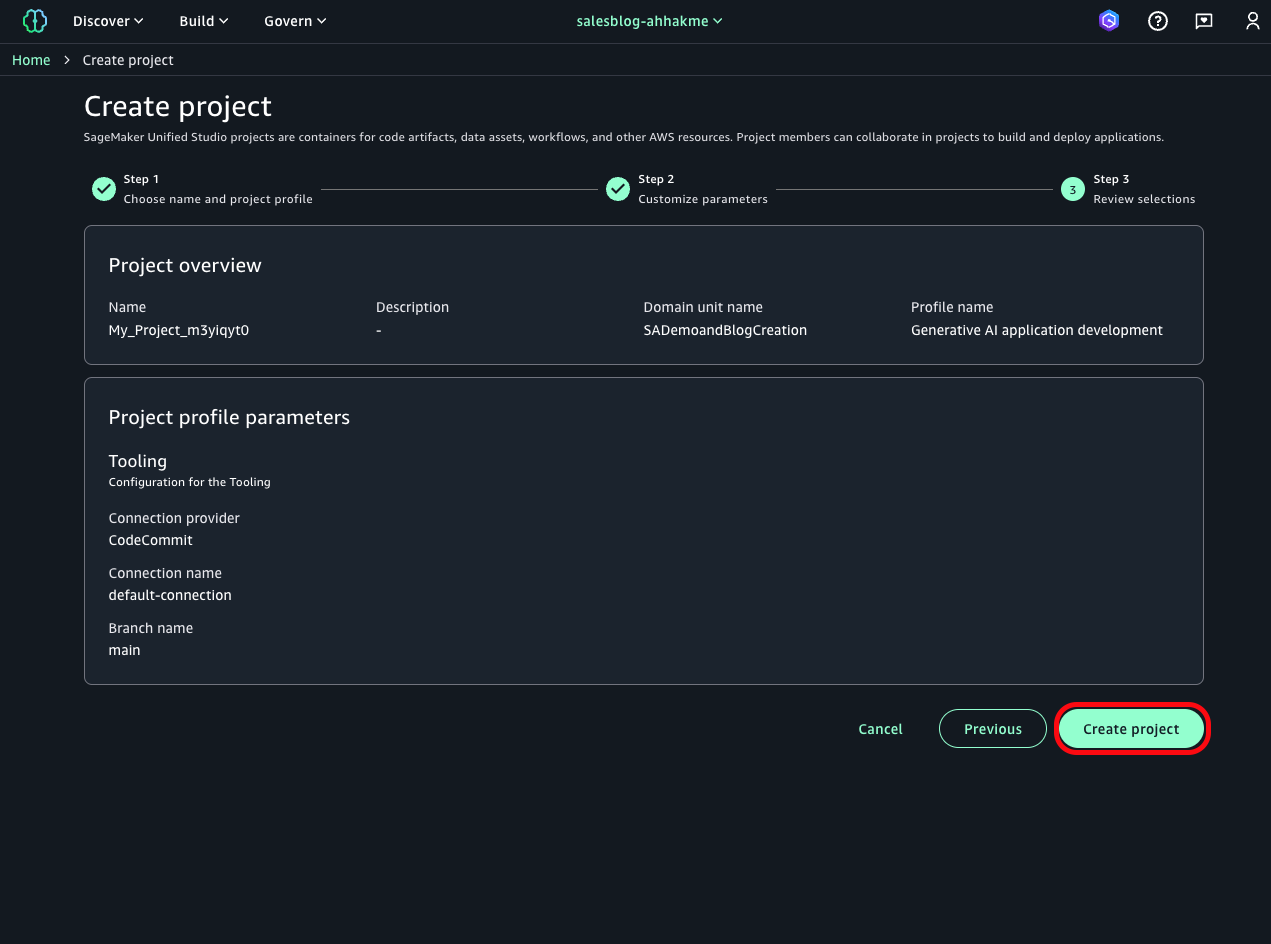
After you’ve created your project, you can begin building your generative ai application.
Prerequisites
Before creating your application in amazon Bedrock IDE, you’ll need to set up a few resources in your AWS account. This will provision the backend infrastructure and services that the sales analytics application will rely on. This includes setting up amazon API Gateway, AWS Lambda functions, and amazon Athena to enable querying the structured sales data.
- Deploy the required AWS resources:
- Launch the AWS CloudFormation stack in your preferred AWS Region:

- After the stack is deployed, note down the API Gateway URL value from the CloudFormation outputs tab:
TextToSqlEngineAPIGatewayURL. - Navigate to the AWS Secrets Manager console and find the secret
-api-keys. Choose Retrieve secret and copy theapiKeyvalue from the plaintext string{"clientId":"default","allowedOperations":("query"),"apiKey":"xxxxxxxx"}.
- Launch the AWS CloudFormation stack in your preferred AWS Region:
You’ll need these values when setting up your amazon Bedrock IDE function later.
- Download all three sample data files. These files contain synthetic data generated by a generative ai model, including customer reviews, customer survey responses, and world news that you’ll use to build your knowledge base:
- Download the API configuration: <a target="_blank" href="https://github.com/aws-samples/amazon-bedrock-ide-genai-demo/blob/main/openapi_schema/openapi_schema.json” target=”_blank” rel=”noopener”>openapi_schema.json. You’ll use this file when setting up your function to query sales data.
That’s it! With these resources ready, you can create your sales analytics application. Each subsequent section will guide you through exactly when and how to use these files.
Instructions configuration for the chat agent
Go to amazon Bedrock IDE chat agent application. Select model from dropdown (this can be changed later – ensure it supports data and functions). In chat agent instructions field, enter:
This instruction will guide the ai application to act as a sales analytics agent, providing structured responses based on the given sales data schema in addition to accessing the product reviews and other sales-related data.
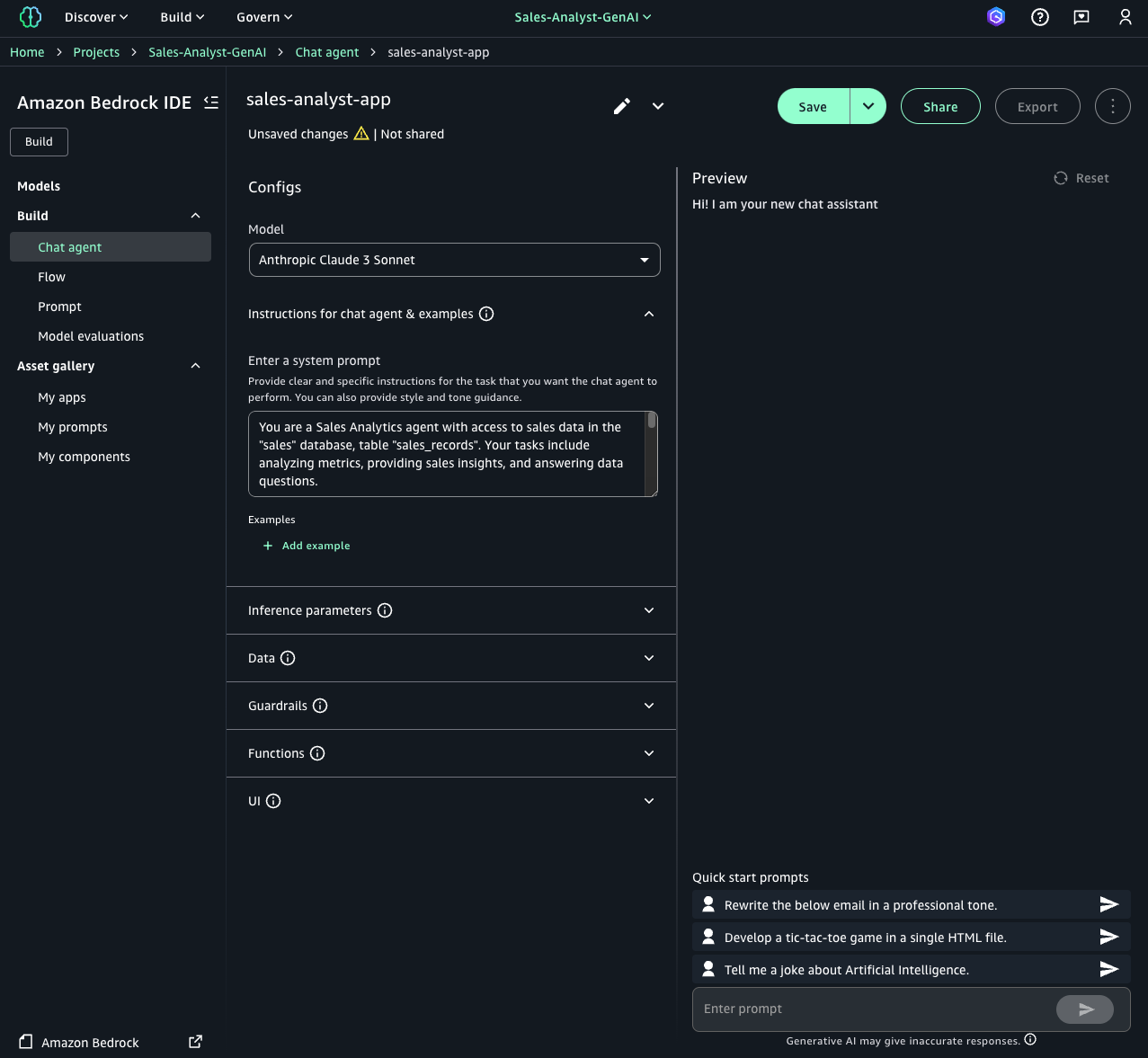
For this application, you will create two main components: a knowledge base to handle unstructured data, and a function that uses amazon Athena to query the structured data. These components will work together to process and retrieve information for your generative ai application.
Creating a knowledge base
Knowledge bases enable your application to analyze unstructured data like customer reviews and news stories.
- Select the Data section on the current chat agent screen.
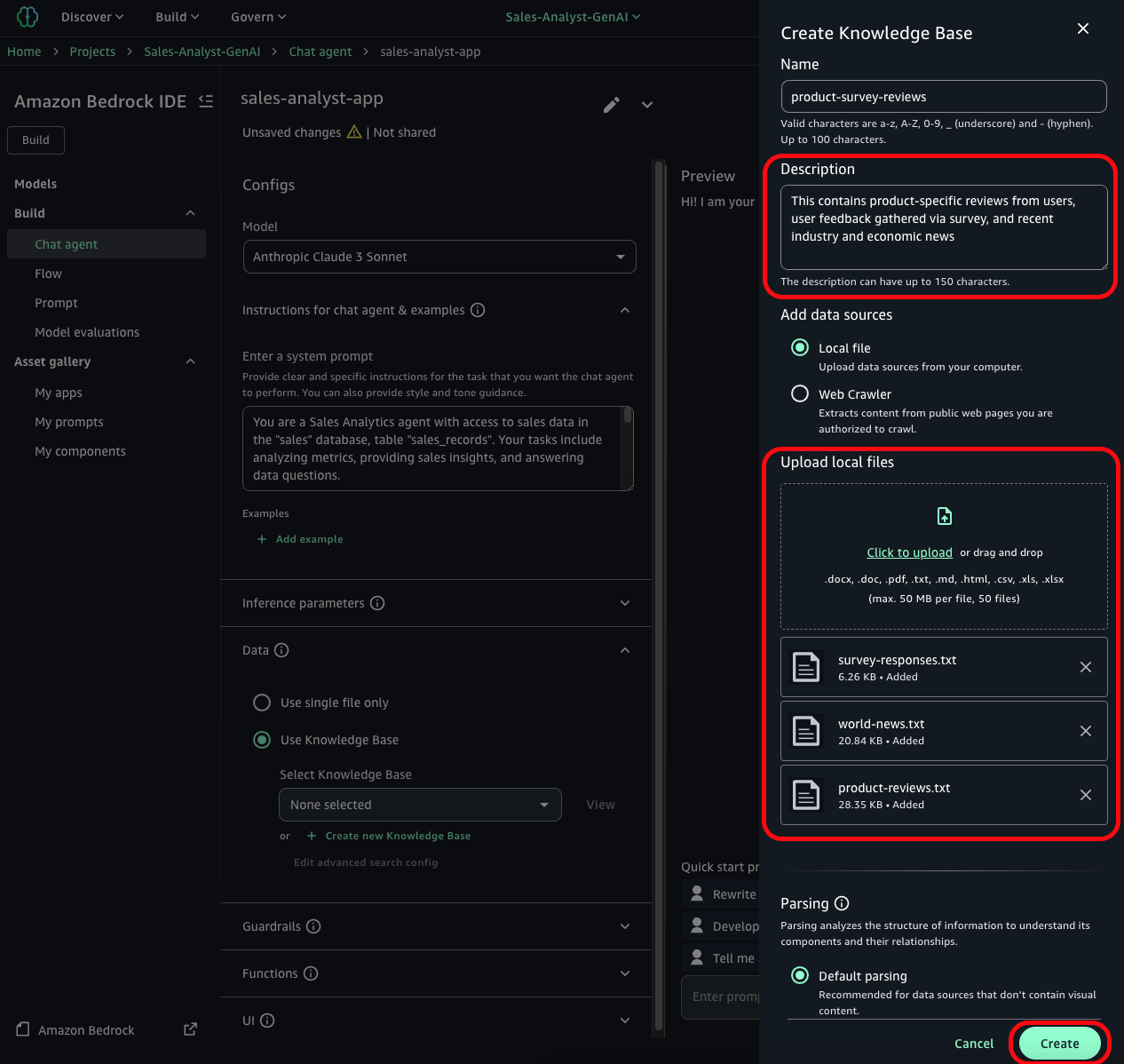
- Choose Create new Knowledge Base and enter a name for your new knowledge base. You also need to enter a brief description for the chat agent to understand the purpose of this Knowledge Base:
This contains product-specific reviews from users, user feedback gathered via survey, and recent industry and economic news
- You have two options for configuring your knowledge base data sources, you can either use local files or you can configure a web crawler. Web scraping automatically extracts content from public web pages that you have permission to access. By adding website URLs to the tool, it will crawl these sites and create a knowledge base from all the defined URLs. This process allows you to efficiently gather and structure information from multiple web sources, building a comprehensive dataset for your needs.
For this post, you’ll upload the files containing unstructured data that we mentioned previously (product-reviews.txt, survey-response.txt, and world-news.txt).
- Choose Click to upload, and upload the three files. Keep the default parsing settings.
- For the embeddings model, select amazon Titan Text Embeddings V2 or any other embeddings model.
- Select OpenSearch Serverless as your vector store.
- After you’ve made these selections, choose Create to create your knowledge base.
- After the knowledge base creation is finished, select it for your application under the Select Knowledge Base dropdown.
This unstructured data will be used to enhance the knowledge base of your generative ai application, allowing it to process and provide insights based on customer reviews, survey responses, and current news relevant to your business sector.
To verify that the unstructured data connection is working properly, submit this example prompt into the application. Note that generative ai systems are nondeterministic, so responses will not be the same every time.
Prompt:
Expected response:
Creating a function
In this section, you will create a function that will interact with amazon API Gateway to query the database, which then forwards requests to the Lambda function that retrieves data from amazon Simple Storage Service (amazon S3) and processes SQL queries using amazon Athena. The AWS infrastructure has already been deployed as part of the CloudFormation template. The structured dataset includes order information for products spanning from 2010 to 2017. This historical data will allow the function to analyze sales trends, product performance, and other relevant metrics over this seven-year period. The application will use this function to integrate structured data analysis capabilities, enabling it to provide insights based on concrete sales data alongside the unstructured data from reviews and news that are already incorporated.
- In your amazon Bedrock IDE Chat agent application, expand the Functions section on the screen. Choose Create New Function.
- Enter a name for the function and provide a description.
- For the function schema, select Import JSON/YAML. Import the API schema from the
openapi_schema.jsonfile that you downloaded earlier. - Important: After importing, you need to modify the API endpoint URL in the schema. Replace it with the actual value from the CloudFormation stack output
TextToSqlEngineAPIGatewayURL. This step makes sure that your function is correctly linked to the appropriate API endpoint for your application.
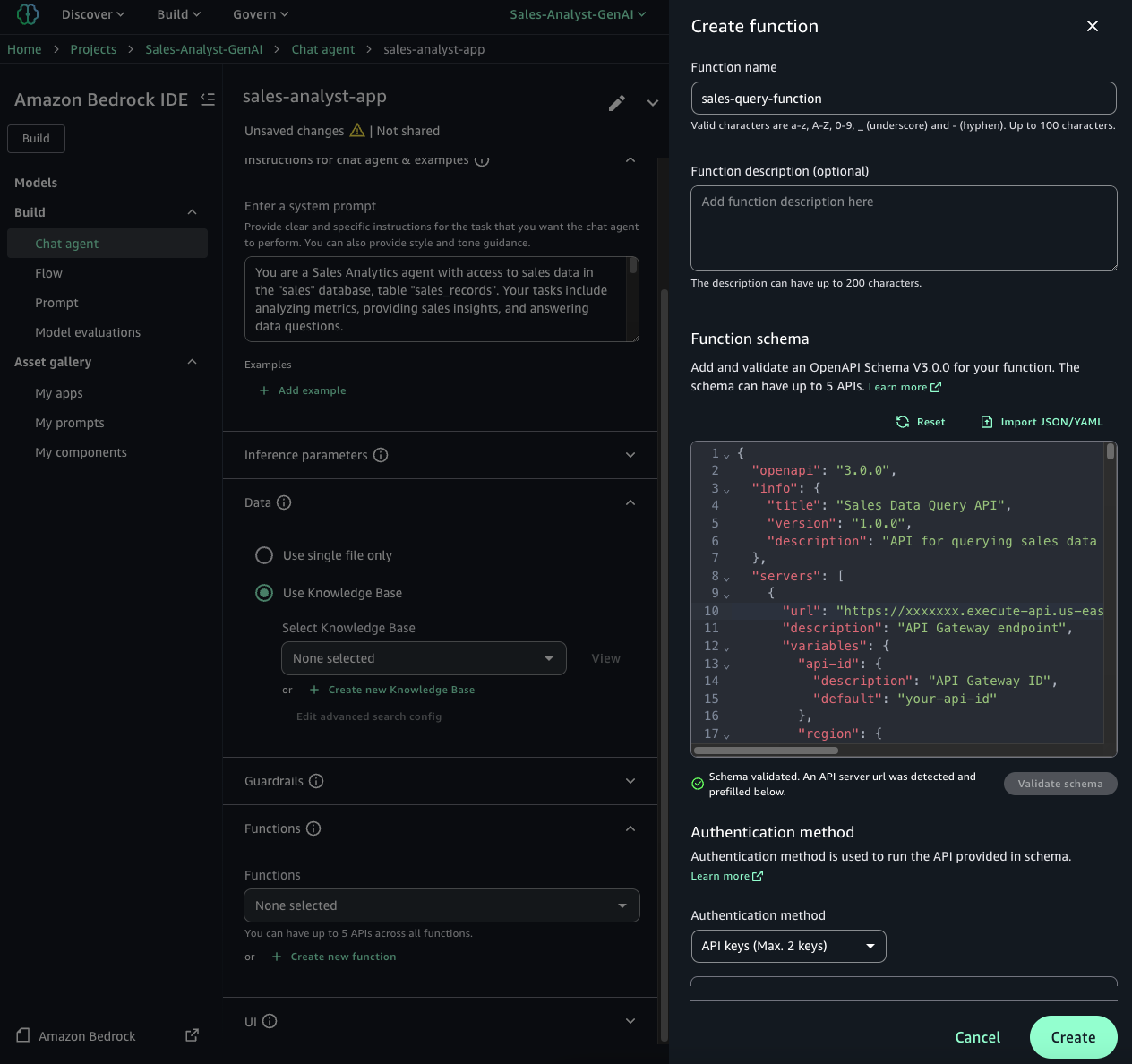
- For the Authentication method, select API Keys (Max. 2 Keys) and enter the following details:
- Choose Create and wait until the function creation is complete.
- After the function creation is finished, select it for your application under Functions dropdown.
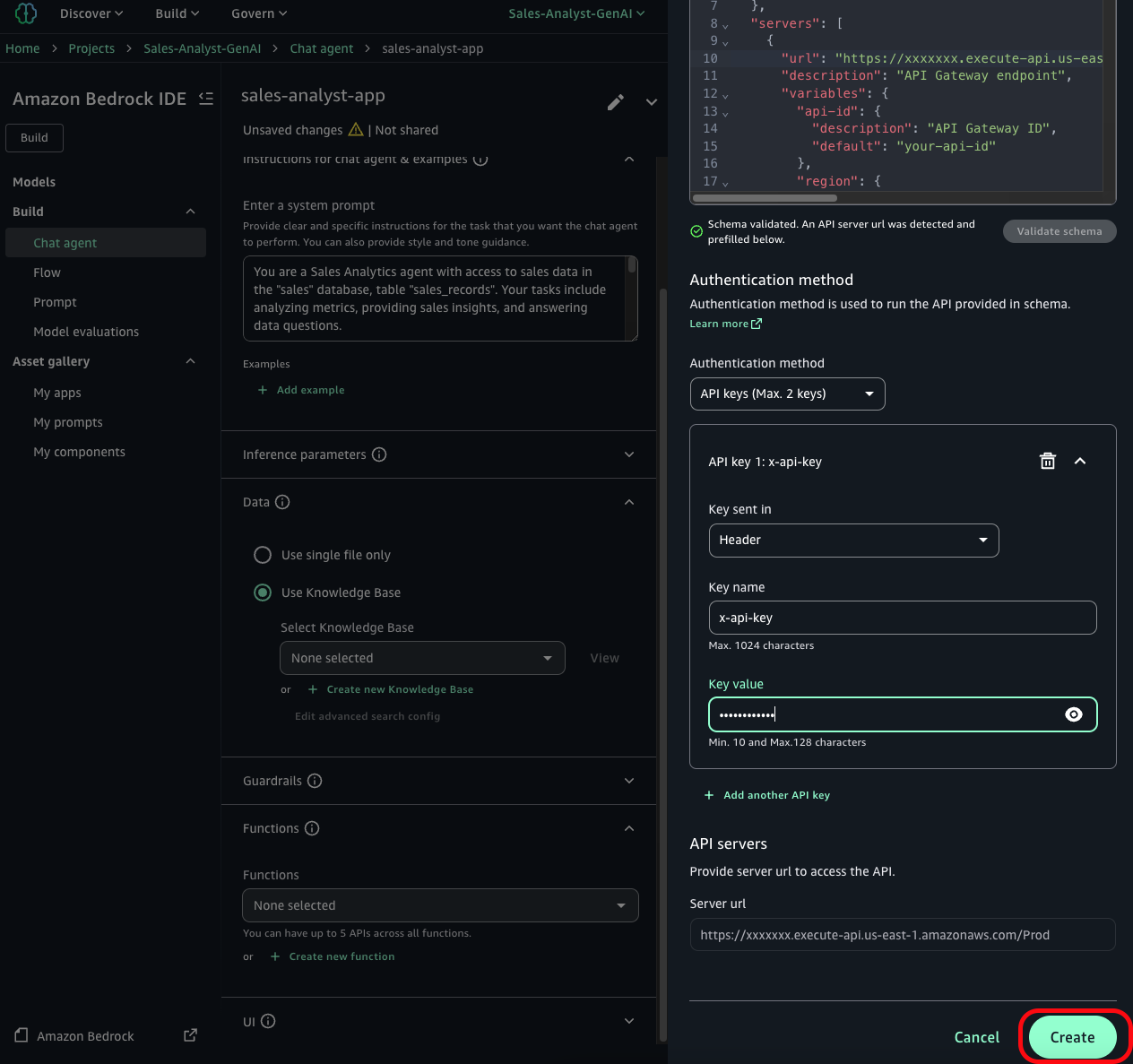
To verify that the structured data connection is working properly, submit the following example query into the application. Note that generative ai systems are nondeterministic, so responses will not be the same every time.
Prompt:
Expected response:
Sharing your application
After you’ve built your application, you can share it with other users in your organization through SageMaker Unified Studio.
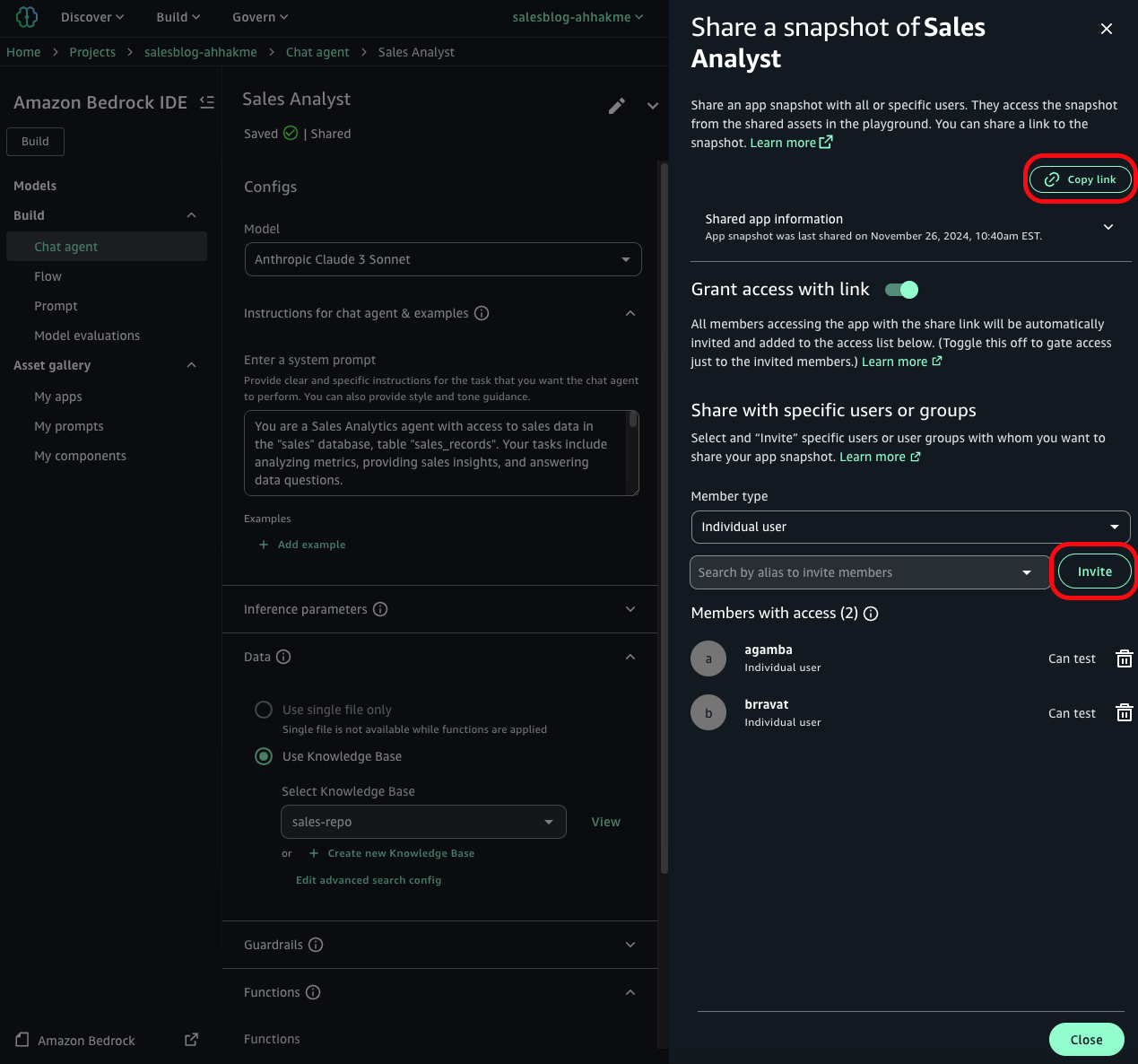
- In the application interface, locate and choose Share in the top right corner.
- In the sharing dialog, search for users by their alias and choose Invite to include them in the sharing list.
- After adding all desired users, copy the application URL from the sharing dialog and send the URL to the added users through your preferred communication channel.
Note: if you turn link sharing on, anyone with the link will be able to subscribe and use the app. If you add their names specifically, only those users can see the app, and it will appear under the “Shared generative ai assets” section for them.
Users must have valid SageMaker Unified Studio access credentials to use the shared application. Contact your AWS administrator if users encounter access issues.
Examples
The following examples demonstrate how a global retail site uses this solution to transform their sales analytics process and extract valuable insights. Let’s explore three types of queries that demonstrate the power of this approach:
- Analyzing structured data to understand sales performance
- Analyzing unstructured customer feedback to extract insights
- Combining both data sources for comprehensive business intelligence
In the following examples, we’ll show how sales analysts can extract valuable insights through basic conversational queries.
Keep in mind that generative ai systems are nondeterministic, so responses will not be the same every time. Generative ai systems might also hallucinate information, and care should be taken to evaluate responses for correctness. Additionally, the structured data source is randomly generated on download, so our results will not necessarily agree. You can access the CSV data source in amazon S3 to evaluate the results manually. Our examples used the Anthropic Claude 3 Sonnet model, but feel free to experiment with others.
Structured data examples
The feature columns that can be queried are the following: Region, Country, Item Type, Sales Channel, Order Priority, Order Date, Order ID, Ship Date, Units Sold, Unit Price, Unit Cost, Total Revenue, Total Cost, and Total Profit. The data spans seven regions and over a hundred countries, with the following item types represented: Baby Food, Beverages, Cereal, Clothes, Cosmetics, Fruits, Household, Meat, Office Supplies, Personal Care, Snacks, and Vegetables.
Prompt 1:
Expected Response 1:
Prompt 2:
Expected Response 2:
Unstructured data examples
The following examples demonstrate a few natural language prompts that you can use to query unstructured data. The goal of these queries is to query textual data to answer questions and identify common themes.
The data that can be queried includes product-specific reviews from users, online compared to offline feedback gathered through surveys, and recent industry and economic news.
Prompt 1:
Expected Response 1:
Prompt 2:
Expected Response 2:
Combined data examples
The following are examples of a few natural language prompts that you can use to query both structured and unstructured data sources and seamlessly combine the results into valuable business insights.
Prompt 1:
Expected Response 1:
Prompt 2:
Expected Response 2:
Clean-up
To clean up the resources deployed in these instructions, first delete the CloudFormation stack. You can then remove resources from your amazon Bedrock IDE project and delete domains by following the amazon SageMaker Unified Studio documentation.
Conclusion
In this post, we demonstrated how amazon Bedrock IDE transforms generative ai application development from a complex technical endeavor into a straightforward point-and-click experience. While traditional approaches require specialized ML expertise and significant development time, amazon Bedrock IDE enables users from various skill levels to create production-ready ai applications in hours instead of weeks.
The key benefits are clear: anyone can now build sophisticated generative ai applications without coding expertise, achieve faster time-to-value through pre-built components, and maintain enterprise governance through centralized management. All while having secure access to their organization’s data through a unified, simple-to-use interface. This same approach can be applied beyond sales analytics to other scenarios where teams need to quickly build ai applications that combine enterprise data with large language models – making generative ai truly accessible across your organization.
Ready to transform your organization’s ai capabilities? Start building your first generative ai application today by following our step-by-step guide or visit amazon Bedrock IDE to explore more solutions for your business needs.
About the Authors
 Ameer Hakme is an AWS Solutions Architect based in Pennsylvania. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud. An expert in ai/ML and generative ai, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.
Ameer Hakme is an AWS Solutions Architect based in Pennsylvania. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud. An expert in ai/ML and generative ai, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.
 Adam Gamba is a Solutions Architect and Aspiring Analytics & ai/ML Specialist at AWS. With his background in computer science, he is very interested in using technology to build solutions to real-world problems. Originally from New Jersey, but now based in Arlington, Virginia, Adam enjoys rock climbing, playing piano, cooking, and attending local museums and concerts.
Adam Gamba is a Solutions Architect and Aspiring Analytics & ai/ML Specialist at AWS. With his background in computer science, he is very interested in using technology to build solutions to real-world problems. Originally from New Jersey, but now based in Arlington, Virginia, Adam enjoys rock climbing, playing piano, cooking, and attending local museums and concerts.
 Bhaskar Ravat is a Senior Solutions Architect at AWS based in New York, with a deep interest in the transformative potential of ai. My passion lies in exploring how ai can impact both everyday life and the broader human experience. You can find him reading 4 books at a time when not helping or building solutions for customers.
Bhaskar Ravat is a Senior Solutions Architect at AWS based in New York, with a deep interest in the transformative potential of ai. My passion lies in exploring how ai can impact both everyday life and the broader human experience. You can find him reading 4 books at a time when not helping or building solutions for customers.
 Kosti Vasilakakis is a Principal Product Manager at AWS. He is an ex-data-scientist, turned PM, now leading amazon Bedrock IDE to help enterprises build high-quality Gen ai applications faster. Kosti remains in awe of the rapid advancements in ai, and is excited to be working on its democratization. Outside of work, you’ll find him coding personal productivity automations, playing tennis, and spending time in the wilderness with his family.
Kosti Vasilakakis is a Principal Product Manager at AWS. He is an ex-data-scientist, turned PM, now leading amazon Bedrock IDE to help enterprises build high-quality Gen ai applications faster. Kosti remains in awe of the rapid advancements in ai, and is excited to be working on its democratization. Outside of work, you’ll find him coding personal productivity automations, playing tennis, and spending time in the wilderness with his family.






{kind=link}