
Rapid engineering refers to the practice of writing instructions to obtain desired responses from basic models (FM). You may have to spend months experimenting and iterating your prompts, following best practices for each model, to achieve the desired result. Additionally, these cues are model and task specific, and performance is not guaranteed when used with a different FM. This manual effort required for rapid engineering can slow down your ability to test different models.
Today we are pleased to announce the availability of Prompt Optimization on amazon Bedrock. With this capability, you can now optimize your prompts for multiple use cases with a single API call or by clicking a button in the amazon Bedrock console.
In this post, we discuss how you can get started with this new feature using an example use case, as well as looking at some performance benchmarks.
Solution Overview
As of this writing, Prompt Optimization for amazon Bedrock supports Prompt Optimization for the Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus, and Claude-3.5-Sonnet models from Anthropic, the Llama 3 70B and Llama 3.1 70B models from Meta, the large model from Mistral and the Titan Text Premier Model from amazon. Quick optimizations can lead to significant improvements for generative ai tasks. Some examples of performance benchmarks for various tasks were conducted and analyzed.
In the following sections, we demonstrate how to use the quick optimization feature. For our use case, we want to optimize a message that analyzes the transcript of a call or chat and ranks the next best action.
Use automatic message optimization
To get started with this feature, complete the following steps:
- In the amazon Bedrock console, choose Quick management in the navigation panel.
- Choose Create message.
- Enter a name and optional description for your message, then choose Create.
- For User messageEnter the request template you want to optimize.
For example, we want to optimize a message that analyzes the transcript of a call or chat and classifies the next best action as one of the following:
- Wait for the customer's opinion
- Assign agent
- Climb
The following screenshot shows what our message looks like in the message builder.
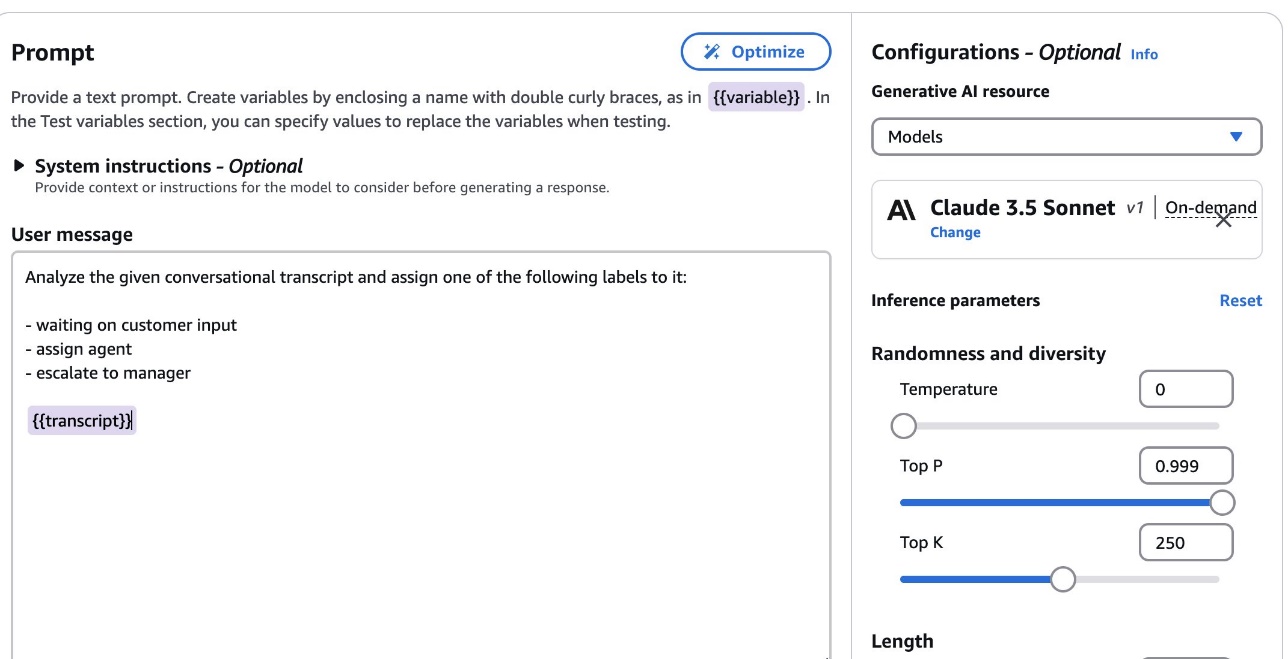
- In it Settings panel, for Generative ai Resourcechoose Models and choose your preferred model. For this example, we use Anthropic's Sonnet Claude 3.5.
- Choose Optimize.
A pop-up window appears indicating that your message is being optimized.
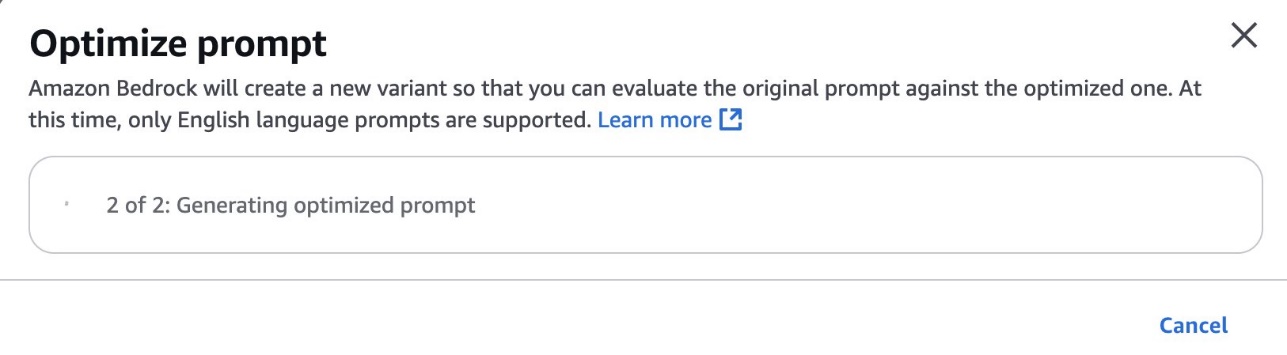
When the optimization is complete, you should see a side-by-side view of the original message and optimized for your use case.
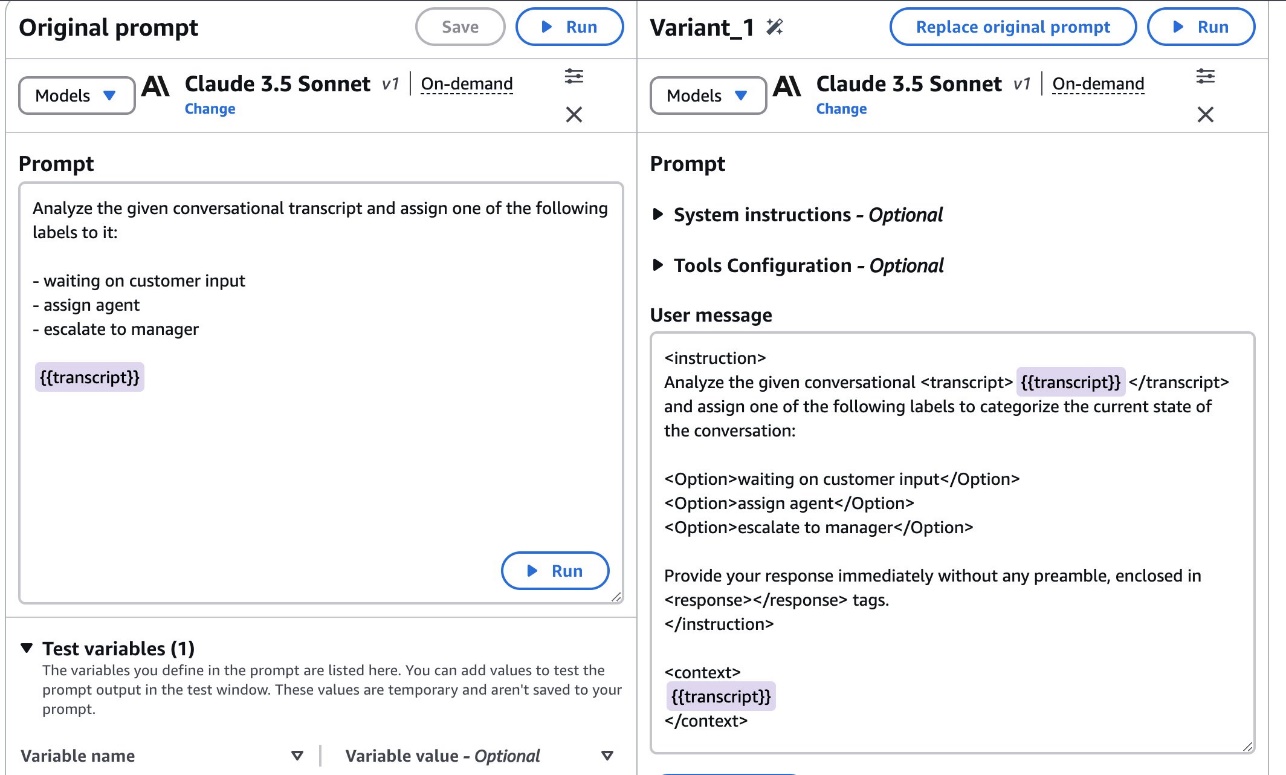
- Add values to your test variables (in this case,
transcript) and choose Run.
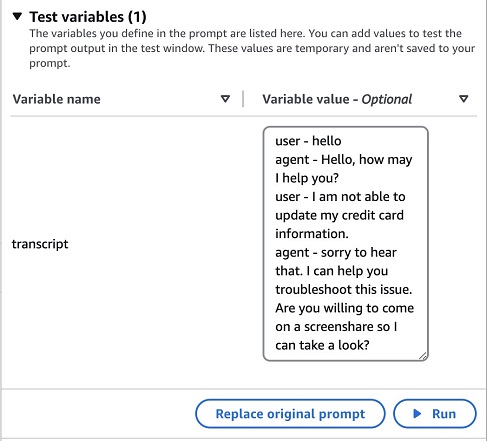
You will then be able to see the result of the model in the desired format.
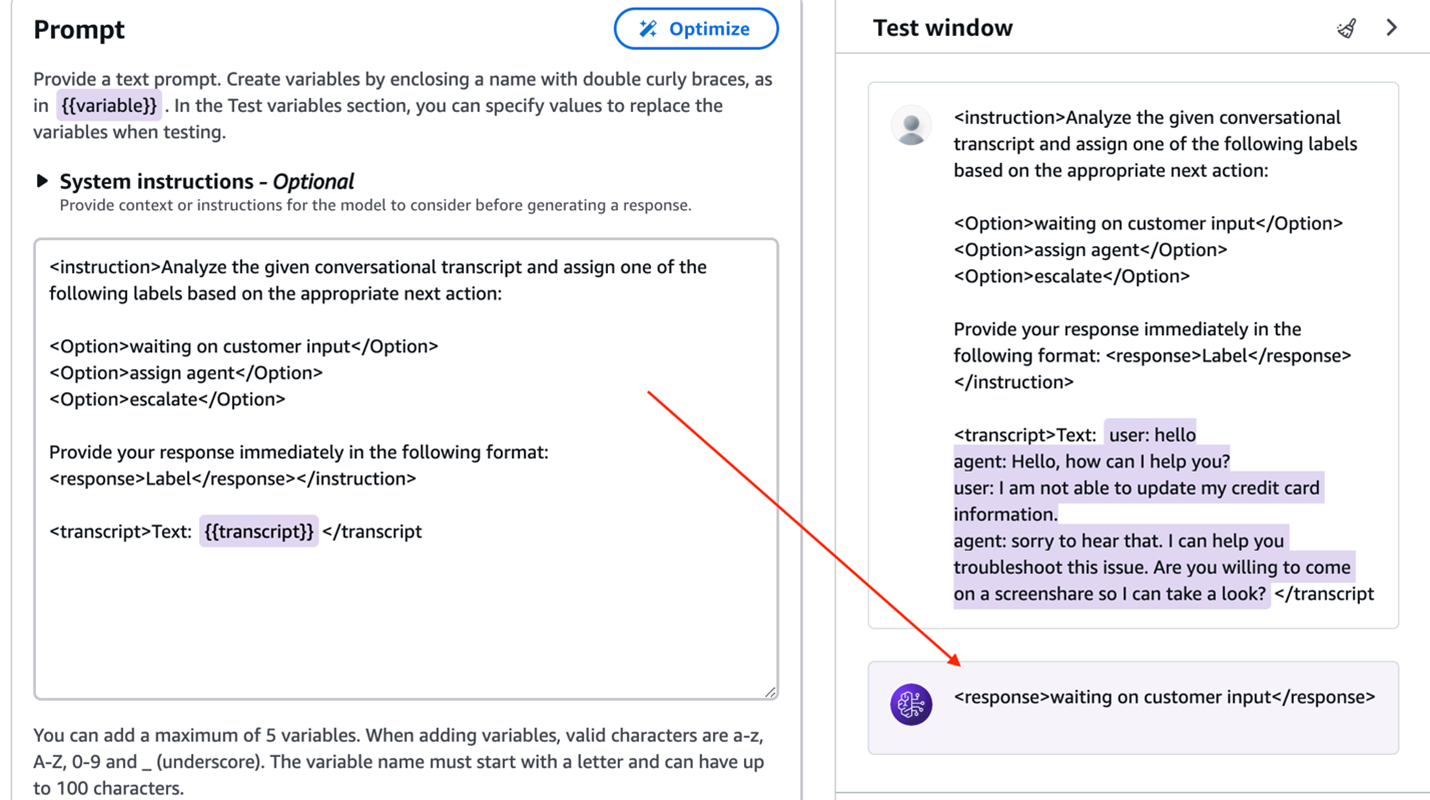
As we can see in this example, the message is more explicit, with clear instructions on how to process the original transcript provided as a variable. This results in the correct classification, in the required output format. Once a message has been optimized, it can be deployed to an application by creating a version that generates a snapshot of its configuration. Multiple versions can be stored to allow switching between different use case prompt configurations. See Notice Management for more details on notice versioning and control.
Performance Benchmarks
We ran the fast optimization function on several open source data sets. We're excited to share improvements seen in some important and common use cases we see our customers working with:
To measure the performance improvement over the baseline, we use ROUGE-2 F1 for the summary use case, HELM-F1 for the dialog continuation use case, and HELM-F1 and JSON matching for the call of functions. We saw an 18% performance improvement in the summary use case, 8% in dialog completion, and 22% in the function call benchmarks. The following table contains the detailed results.
| Use case | original notice | Optimized message | Performance improvement |
| Summary | First, please read the article below. {context} Now, can you write me an extremely short abstract for it? |
Your task is to provide a concise 1-2 sentence summary of the given text that captures the main points or key information.{context}Please read the provided text carefully and thoroughly to understand its content. Then, generate a brief summary in your own words that is much shorter than the original text while still preserving the core ideas and essential details. The summary should be concise yet informative, capturing the essence of the text in just 1-2 sentences.Summary: (WRITE YOUR 1-2 SENTENCE SUMMARY HERE) |
18.04% |
| Dialog continuation | Functions available:{available_functions}Examples of calling functions:Input:Functions: ({"name": "calculate_area", "description": "Calculate the area of a shape", "parameters": {"type": "object", "properties": {"shape": {"type": "string", "description": "The type of shape (e.g. rectangle, triangle, circle)"}, "dimensions": {"type": "object", "properties": {"length": {"type": "number", "description": "The length of the shape"}, "width": {"type": "number", "description": "The width of the shape"}, "base": {"type": "number", "description": "The base of the shape"}, "height": {"type": "number", "description": "The height of the shape"}, "radius": {"type": "number", "description": "The radius of the shape"}}}}, "required": ("shape", "dimensions")}})Conversation history: USER: Can you calculate the area of a rectangle with a length of 5 and width of 3?Output:{"name": "calculate_area", "arguments": {"shape": "rectangle", "dimensions": {"length": 5, "width": 3}}}Input:Functions: ({"name": "search_books", "description": "Search for books based on title or author", "parameters": {"type": "object", "properties": {"search_query": {"type": "string", "description": "The title or author to search for"}}, "required": ("search_query")}})Conversation history: USER: I am looking for books by J.K. Rowling. Can you help me find them?Output:{"name": "search_books", "arguments": {"search_query": "J.K. Rowling"}}Input:Functions: ({"name": "calculate_age", "description": "Calculate the age based on the birthdate", "parameters": {"type": "object", "properties": {"birthdate": {"type": "string", "format": "date", "description": "The birthdate"}}, "required": ("birthdate")}})Conversation history: USER: Hi, I was born on 1990-05-15. Can you tell me how old I am today?Output:{"name": "calculate_age", "arguments": {"birthdate": "1990-05-15"}}Current chat history:{conversation_history}Respond to the last message. Call a function if necessary. |
|
8.23% |
| Function call |
|
You are an advanced question-answering system that utilizes information from a retrieval augmented generation (RAG) system to provide accurate and relevant responses to user queries.1. Carefully review the provided context information:Domain: Restaurant Entity: THE COPPER KETTLE Review: My friend Mark took me to the copper kettle to celebrate my promotion. I decided to treat myself to Shepherds Pie. It was not as flavorful as I'd have liked and the consistency was just runny, but the servers were awesome and I enjoyed the view from the patio. I may come back to try the strawberries and cream come time for Wimbledon..Highlight: It was not as flavorful as I'd have liked and the consistency was just runny, but the servers were awesome and I enjoyed the view from the patio.Domain: Restaurant Entity: THE COPPER KETTLE Review: Last week, my colleagues and I visited THE COPPER KETTLE that serves British cuisine. We enjoyed a nice view from inside of the restaurant. The atmosphere was enjoyable and the restaurant was located in a nice area. However, the food was mediocre and was served in small portions.Highlight: We enjoyed a nice view from inside of the restaurant.2. Analyze the user's question:user: Howdy, I'm looking for a British restaurant for breakfast.agent: There are several British restaurants available. Would you prefer a moderate or expensive price range?user: Moderate price range please.agent: Five restaurants match your criteria. Four are in Centre area and one is in the West. Which area would you prefer?user: I would like the Center of town please.agent: How about The Copper Kettle?user: Do they offer a good view?
|
22.03% |
Consistent improvements across different tasks highlight the robustness and effectiveness of prompt optimization in improving prompt performance for various natural language processing (NLP) tasks. This shows that prompt optimization can save you considerable time and effort while achieving better results when testing models with optimized prompts that implement best practices for each model.
Conclusion
Ad optimization in amazon Bedrock allows you to effortlessly improve the performance of your ads across a wide range of use cases with just an API call or a few clicks in the amazon Bedrock console. The substantial improvements demonstrated in open source benchmarks for tasks such as summarization, dialog continuation, and function calls underscore the ability of this new feature to significantly streamline the rapid engineering process. Rapid Optimization in amazon Bedrock allows you to easily test many different models for your generative ai application, following rapid engineering best practices for each model. Reducing manual effort will greatly accelerate the development of generative ai applications in your organization.
We recommend that you try Rapid Optimization with your own use cases and contact us for feedback and collaboration.
About the authors
 Shreyas Subramanian is a Principal Data Scientist, helping customers use generative ai and deep learning to solve their business challenges using AWS services. Shreyas has experience in large-scale optimization and ML and using ML and reinforcement learning to accelerate optimization tasks.
Shreyas Subramanian is a Principal Data Scientist, helping customers use generative ai and deep learning to solve their business challenges using AWS services. Shreyas has experience in large-scale optimization and ML and using ML and reinforcement learning to accelerate optimization tasks.
 Chris Pecora is a Generative ai Data Scientist at amazon Web Services. He is passionate about creating innovative products and solutions while focusing on customer-obsessed science. When not running experiments and keeping up with the latest advances in generative ai, he loves spending time with his children.
Chris Pecora is a Generative ai Data Scientist at amazon Web Services. He is passionate about creating innovative products and solutions while focusing on customer-obsessed science. When not running experiments and keeping up with the latest advances in generative ai, he loves spending time with his children.
 Zheng Yuan Shen is an applied scientist at amazon Bedrock specializing in fundamental models and machine learning modeling for complex tasks including natural language and structured data understanding. He is passionate about leveraging innovative machine learning solutions to improve products or services, thereby simplifying customers' lives through a seamless combination of science and engineering. Outside of work, he enjoys sports and cooking.
Zheng Yuan Shen is an applied scientist at amazon Bedrock specializing in fundamental models and machine learning modeling for complex tasks including natural language and structured data understanding. He is passionate about leveraging innovative machine learning solutions to improve products or services, thereby simplifying customers' lives through a seamless combination of science and engineering. Outside of work, he enjoys sports and cooking.
 Shipra Kanoria He is a Principal Product Manager at AWS. He is passionate about helping clients solve their most complex problems with the power of machine learning and artificial intelligence. Prior to joining AWS, Shipra spent over 4 years at amazon Alexa, where she launched many productivity-related features in the Alexa voice assistant.
Shipra Kanoria He is a Principal Product Manager at AWS. He is passionate about helping clients solve their most complex problems with the power of machine learning and artificial intelligence. Prior to joining AWS, Shipra spent over 4 years at amazon Alexa, where she launched many productivity-related features in the Alexa voice assistant.






{kind=link}