
El resumen de datos es un primer paso esencial en cualquier flujo de trabajo de análisis de datos. Mientras que los pandas describe() La función ha sido una herramienta de referencia para muchos, su funcionalidad se limita a datos numéricos y solo proporciona estadísticas básicas. Ingrese a Skimpy, una biblioteca de Python diseñada para ofrecer resúmenes de datos detallados, visualmente atractivos y completos para todo tipo de columnas.
En este artículo, exploraremos por qué Skimpy es una alternativa digna a Pandas describe(). Aprenderá cómo instalar y usar Skimpy, explorar sus características y comparar su resultado con describe() a través de ejemplos. Al final, comprenderá completamente cómo Skimpy mejora el análisis de datos exploratorios (EDA).
Resultados de aprendizaje
- Comprender las limitaciones de los pandas
describe()función. - Aprenda a instalar e implementar Skimpy en Python.
- Explore los resultados y conocimientos detallados de Skimpy con ejemplos.
- Comparar resultados de Skimpy y Pandas
describe(). - Comprenda cómo integrar Skimpy en su flujo de trabajo de análisis de datos.
¿Por qué Pandas describe() no es suficiente?
El describe() La función en Pandas se usa ampliamente para resumir datos rápidamente. Si bien sirve como una poderosa herramienta para el análisis de datos exploratorios (EDA), su utilidad es limitada en varios aspectos. Aquí hay un desglose detallado de sus deficiencias y por qué los usuarios suelen buscar alternativas como Skimpy:
Centrarse en datos numéricos de forma predeterminada
Por defecto, describe() solo funciona en columnas numéricas a menos que se configure explícitamente lo contrario.
Ejemplo:
import pandas as pd
data = {
"Name": ("Alice", "Bob", "Charlie", "David"),
"Age": (25, 30, 35, 40),
"City": ("New York", "Los Angeles", "Chicago", "Houston"),
"Salary": (70000, 80000, 120000, 90000),
}
df = pd.DataFrame(data)
print(df.describe()) Producción:
Age Salary
count 4.000000 4.000000
mean 32.500000 90000.000000
std 6.454972 20000.000000
min 25.000000 70000.000000
25% 28.750000 77500.000000
50% 32.500000 85000.000000
75% 36.250000 97500.000000
max 40.000000 120000.000000 Cuestión clave:
Columnas no numéricas (Name y City) se ignoran a menos que llame explícitamente describe(include="all"). Incluso entonces, el resultado sigue siendo de alcance limitado para columnas no numéricas.
Resumen limitado para datos no numéricos
Cuando se incluyen columnas no numéricas usando include="all"el resumen es mínimo. Sólo muestra:
- Contar: Número de valores no perdidos.
- Único: Recuento de valores únicos.
- Arriba: El valor que ocurre con más frecuencia.
- Frecuencia: Frecuencia del valor superior.
Ejemplo:
print(df.describe(include="all")) Producción:
Name Age City Salary
count 4 4.0 4 4.000000
unique 4 NaN 4 NaN
top Alice NaN New York NaN
freq 1 NaN 1 NaN
mean NaN 32.5 NaN 90000.000000
std NaN 6.5 NaN 20000.000000
min NaN 25.0 NaN 70000.000000
25% NaN 28.8 NaN 77500.000000
50% NaN 32.5 NaN 85000.000000
75% NaN 36.2 NaN 97500.000000
max NaN 40.0 NaN 120000.000000 Cuestiones clave:
- Columnas de cadena (
NameyCity) se resumen utilizando métricas demasiado básicas (p. ej.,top,freq). - No hay información sobre longitudes de cadenas, patrones o proporciones de datos faltantes.
No hay información sobre datos faltantes
pandas describe() no muestra explícitamente el porcentaje de datos faltantes para cada columna. Identificar los datos faltantes requiere comandos separados:
print(df.isnull().sum()) Falta de métricas avanzadas
Las métricas predeterminadas proporcionadas por describe() son básicos. Para datos numéricos, muestra:
- Recuento, media y desviación estándar.
- Mínimo, máximo y cuartiles (25%, 50% y 75%).
Sin embargo, carece de detalles estadísticos avanzados como:
- Kurtosis y asimetría: Indicadores de distribución de datos.
- Detección de valores atípicos: No hay indicación de valores extremos más allá de los rangos típicos.
- Agregaciones personalizadas: Flexibilidad limitada para aplicar funciones definidas por el usuario.
Mala visualización de datos
describe() genera un resumen de texto sin formato que, si bien es funcional, no es visualmente atractivo ni fácil de interpretar en algunos casos. Visualizar tendencias o distribuciones requiere bibliotecas adicionales como Matplotlib o Seaborn.
Ejemplo: Un histograma o diagrama de caja representaría mejor las distribuciones, pero describe() no proporciona tales capacidades visuales.
Empezando con Skimpy
Skimpy es una biblioteca de Python diseñada para simplificar y mejorar el análisis de datos exploratorios (EDA). Proporciona resúmenes detallados y concisos de sus datos, manejando columnas numéricas y no numéricas de manera efectiva. A diferencia de los pandas describe()Skimpy incluye métricas avanzadas, información faltante de datos y un resultado más claro e intuitivo. Esto la convierte en una herramienta excelente para comprender rápidamente conjuntos de datos, identificar problemas de calidad de los datos y prepararse para un análisis más profundo.
Instale Skimpy usando pip:
Ejecute el siguiente comando en su terminal o símbolo del sistema:
pip install skimpyVerifique la instalación:
Después de la instalación, puede verificar que Skimpy esté instalado correctamente importándolo en un script de Python o Jupyter Notebook:
from skimpy import skim
print("Skimpy installed successfully!")¿Por qué Skimpy es mejor?
Exploremos ahora varias razones en detalle por las que usar Skimpy es mejor:
Resumen unificado para todos los tipos de datos
Skimpy trata todos los tipos de datos con la misma importancia y proporciona resúmenes completos para columnas numéricas y no numéricas en una única tabla unificada.
Ejemplo:
from skimpy import skim
import pandas as pd
data = {
"Name": ("Alice", "Bob", "Charlie", "David"),
"Age": (25, 30, 35, 40),
"City": ("New York", "Los Angeles", "Chicago", "Houston"),
"Salary": (70000, 80000, 120000, 90000),
}
df = pd.DataFrame(data)
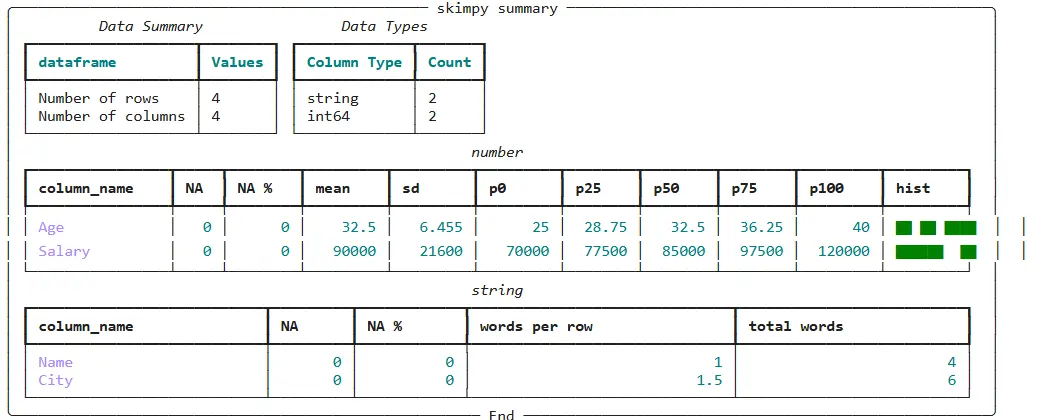
skim(df) Producción:
Skimpy genera una tabla concisa y bien estructurada con información como:
- Datos numéricos: Recuento, media, mediana, desviación estándar, mínimo, máximo y cuartiles.
- Datos no numéricos: Valores únicos, valor (modo) más frecuente, valores faltantes y distribuciones de recuento de caracteres.
Manejo integrado de datos faltantes
Skimpy resalta automáticamente los datos faltantes en su resumen, mostrando el porcentaje y el recuento de valores faltantes para cada columna. Esto elimina la necesidad de comandos adicionales como df.isnull().sum().
Por qué esto es importante:
- Ayuda a los usuarios a identificar problemas de calidad de los datos por adelantado.
- Fomenta decisiones rápidas sobre la imputación o eliminación de datos faltantes.
Información estadística avanzada
Skimpy va más allá de las estadísticas descriptivas básicas al incluir métricas adicionales que brindan información más profunda:
- Curtosis: Indica la “cola” de una distribución.
- Oblicuidad: Mide la asimetría en la distribución de datos.
- Banderas atípicas: Resalta las columnas con posibles valores atípicos.
Resumen enriquecido para columnas de texto
Para datos no numéricos como cadenas, Skimpy ofrece resúmenes detallados que Pandas describe() no puede coincidir:
- Distribución de longitud de cuerda: Proporciona información sobre las longitudes de cadena mínima, máxima y promedio.
- Patrones y variaciones: Identifica patrones comunes en datos de texto.
- Valores y modos únicos: Da una imagen más clara de la diversidad del texto.
Ejemplo de salida para columnas de texto:
| Columna | Valores únicos | Valor más frecuente | Recuento de modos | Longitud promedio |
|---|---|---|---|---|
| Nombre | 4 | Alicia | 1 | 5.25 |
| Ciudad | 4 | Nueva York | 1 | 7.50 |
Imágenes compactas e intuitivas
Skimpy utiliza resultados tabulares y codificados por colores que son más fáciles de interpretar, especialmente para conjuntos de datos grandes. Estas imágenes destacan:
- Valores faltantes.
- Distribuciones.
- Estadísticas resumidas, todo de un solo vistazo.
Este atractivo visual hace que los resúmenes de Skimpy estén listos para la presentación, lo que es particularmente útil para informar los hallazgos a las partes interesadas.
Soporte integrado para variables categóricas
Skimpy proporciona métricas específicas para datos categóricos que Pandas describe() no, como por ejemplo:
- Distribución de categorías.
- Frecuencia y proporciones para cada categoría.
Esto hace que Skimpy sea particularmente valioso para conjuntos de datos que involucran variables demográficas, geográficas u otras variables categóricas.
Usando Skimpy para resumir datos
A continuación, exploramos cómo utilizar Skimpy de forma eficaz para el resumen de datos.
Paso 1: importe Skimpy y prepare su conjunto de datos
Para usar Skimpy, primero debes importarlo junto con tu conjunto de datos. Skimpy se integra perfectamente con Pandas DataFrames.
Conjunto de datos de ejemplo:
Trabajemos con un conjunto de datos simple que contiene datos numéricos, categóricos y de texto.
import pandas as pd
from skimpy import skim
# Sample dataset
data = {
"Name": ("Alice", "Bob", "Charlie", "David"),
"Age": (25, 30, 35, 40),
"City": ("New York", "Los Angeles", "Chicago", "Houston"),
"Salary": (70000, 80000, 120000, 90000),
"Rating": (4.5, None, 4.7, 4.8),
}
df = pd.DataFrame(data)Paso 2: aplicar la función skim()
La función principal de Skimpy es skim(). Cuando se aplica a un DataFrame, proporciona un resumen detallado de todas las columnas.
Uso:
skim(df)Paso 3: interpretar el resumen de Skimpy
Analicemos lo que significa la salida de Skimpy:
| Columna | Tipo de datos | Desaparecido (%) | Significar | Mediana | mín. | máx. | Único | Valor más frecuente | Recuento de modos |
|---|---|---|---|---|---|---|---|---|---|
| Nombre | Texto | 0,0% | — | — | — | — | 4 | Alicia | 1 |
| Edad | Numérico | 0,0% | 32,5 | 32,5 | 25 | 40 | — | — | — |
| Ciudad | Texto | 0,0% | — | — | — | — | 4 | Nueva York | 1 |
| Salario | Numérico | 0,0% | 90000 | 85000 | 70000 | 120000 | — | — | — |
| Clasificación | Numérico | 25,0% | 4.67 | 4.7 | 4.5 | 4.8 | — | — | — |
- Valores faltantes: A la columna “Calificación” le faltan un 25 % de valores, lo que indica posibles problemas de calidad de los datos.
- Columnas numéricas: La media y la mediana de “Salario” son cercanas, lo que indica una distribución aproximadamente simétrica, mientras que “Edad” se distribuye uniformemente dentro de su rango.
- Columnas de texto: La columna “Ciudad” tiene 4 valores únicos, siendo “Nueva York” el más frecuente.
Paso 4: centrarse en conocimientos clave
Skimpy es particularmente útil para identificar:
- Problemas de calidad de datos:
- Valores faltantes en columnas como “Calificación”.
- Valores atípicos a través de métricas como mínimo, máximo y cuartiles.
- Patrones en datos categóricos:
- Categorías más frecuentes en columnas como “Ciudad”.
- Información sobre la longitud de la cadena:
- Para conjuntos de datos con mucho texto, Skimpy proporciona longitudes de cadena promedio, lo que ayuda en tareas de preprocesamiento como la tokenización.
Paso 5: Personalización de la salida Skimpy
Skimpy permite cierta flexibilidad para ajustar su salida según sus necesidades:
- Columnas de subconjunto: Analice solo columnas específicas pasándolas como un subconjunto del DataFrame:
skim(df(("Age", "Salary")))- Centrarse en los datos faltantes: Identifique rápidamente los porcentajes de datos faltantes:
skim(df).loc(:, ("Column", "Missing (%)"))Ventajas de usar Skimpy
- Resumen todo en uno: Skimpy consolida información numérica y no numérica en una sola tabla.
- Ahorro de tiempo: Elimina la necesidad de escribir varias líneas de código para explorar diferentes tipos de datos.
- Legibilidad mejorada: Los resúmenes claros y visualmente atractivos facilitan la identificación de tendencias y valores atípicos.
- Eficiente para grandes conjuntos de datos: Skimpy está optimizado para manejar conjuntos de datos con numerosas columnas sin abrumar al usuario.
Conclusión
Skimpy simplifica el resumen de datos al ofrecer información detallada y legible por humanos sobre conjuntos de datos de todo tipo. A diferencia de los pandas describe()no restringe su enfoque a datos numéricos y proporciona una experiencia de resumen más enriquecida. Ya sea que esté limpiando datos, explorando tendencias o preparando informes, las funciones de Skimpy lo convierten en una herramienta indispensable para los profesionales de datos.
Conclusiones clave
- Skimpy maneja columnas numéricas y no numéricas sin problemas.
- Proporciona información adicional, como valores faltantes y recuentos únicos.
- El formato de salida es más intuitivo y visualmente atractivo que Pandas.
describe().
Preguntas frecuentes
R. Es una biblioteca de Python diseñada para un resumen completo de datos y que ofrece información más allá de Pandas. describe().
describe()?
R. Sí, proporciona una funcionalidad mejorada y puede reemplazar eficazmente describe().
R. Sí, está optimizado para manejar grandes conjuntos de datos de manera eficiente.
A. Instálelo usando pip: pip install skimpy.
describe()?
R. Resume todos los tipos de datos, incluye información sobre los valores faltantes y presenta los resultados en un formato más fácil de usar.

Mi nombre es Ayushi Trivedi. Soy un graduado de B. tech. Tengo 3 años de experiencia trabajando como educador y editor de contenidos. He trabajado con varias bibliotecas de Python, como numpy, pandas, seaborn, matplotlib, scikit, imblearn, linear regression y muchas más. También soy autor. Mi primer libro llamado #turning25 se publicó y está disponible en amazon y Flipkart. Aquí soy editor de contenido técnico en Analytics Vidhya. Me siento orgulloso y feliz de ser AVian. Tengo un gran equipo con el que trabajar. Me encanta construir el puente entre la tecnología y el alumno.




