
As generative ai models advance in creating multimedia content, the difference between good and great output often lies in the details that only human feedback can capture. Audio and video segmentation provides a structured way to gather this detailed feedback, allowing models to learn through reinforcement learning from human feedback (RLHF) and supervised fine-tuning (SFT). Annotators can precisely mark and evaluate specific moments in audio or video content, helping models understand what makes content feel authentic to human viewers and listeners.
Take, for instance, text-to-video generation, where models need to learn not just what to generate but how to maintain consistency and natural flow across time. When creating a scene of a person performing a sequence of actions, factors like the timing of movements, visual consistency, and smoothness of transitions contribute to the quality. Through precise segmentation and annotation, human annotators can provide detailed feedback on each of these aspects, helping models learn what makes a generated video sequence feel natural rather than artificial. Similarly, in text-to-speech applications, understanding the subtle nuances of human speech—from the length of pauses between phrases to changes in emotional tone—requires detailed human feedback at a segment level. This granular input helps models learn how to produce speech that sounds natural, with appropriate pacing and emotional consistency. As large language models (LLMs) increasingly integrate more multimedia capabilities, human feedback becomes even more critical in training them to generate rich, multi-modal content that aligns with human quality standards.
The path to creating effective ai models for audio and video generation presents several distinct challenges. Annotators need to identify precise moments where generated content matches or deviates from natural human expectations. For speech generation, this means marking exact points where intonation changes, where pauses feel unnatural, or where emotional tone shifts unexpectedly. In video generation, annotators must pinpoint frames where motion becomes jerky, where object consistency breaks, or where lighting changes appear artificial. Traditional annotation tools, with basic playback and marking capabilities, often fall short in capturing these nuanced details.
amazon SageMaker Ground Truth enables RLHF by allowing teams to integrate detailed human feedback directly into model training. Through custom human annotation workflows, organizations can equip annotators with tools for high-precision segmentation. This setup enables the model to learn from human-labeled data, refining its ability to produce content that aligns with natural human expectations.
In this post, we show you how to implement an audio and video segmentation solution in the accompanying GitHub repository using SageMaker Ground Truth. We guide you through deploying the necessary infrastructure using AWS CloudFormation, creating an internal labeling workforce, and setting up your first labeling job. We demonstrate how to use Wavesurfer.js for precise audio visualization and segmentation, configure both segment-level and full-content annotations, and build the interface for your specific needs. We cover both console-based and programmatic approaches to creating labeling jobs, and provide guidance on extending the solution with your own annotation needs. By the end of this post, you will have a fully functional audio/video segmentation workflow that you can adapt for various use cases, from training speech synthesis models to improving video generation capabilities.
Feature Overview
The integration of Wavesurfer.js in our UI provides a detailed waveform visualization where annotators can instantly see patterns in speech, silence, and audio intensity. For instance, when working on speech synthesis, annotators can visually identify unnatural gaps between words or abrupt changes in volume that might make generated speech sound robotic. The ability to zoom into these waveform patterns means they can work with millisecond precision—marking exactly where a pause is too long or where an emotional transition happens too abruptly.
In this snapshot of audio segmentation, we are capturing a customer-representative conversation, annotating speaker segments, emotions, and transcribing the dialogue. The UI allows for playback speed adjustment and zoom functionality for precise audio analysis.
The multi-track feature lets annotators create separate tracks for evaluating different aspects of the content. In a text-to-speech task, one track might focus on pronunciation accuracy, another on emotional consistency, and a third on natural pacing. For video generation tasks, annotators can mark segments where motion flows naturally, where object consistency is maintained, and where scene transitions work well. They can adjust playback speed to catch subtle details, and the visual timeline for precise start and end points for each marked segment.
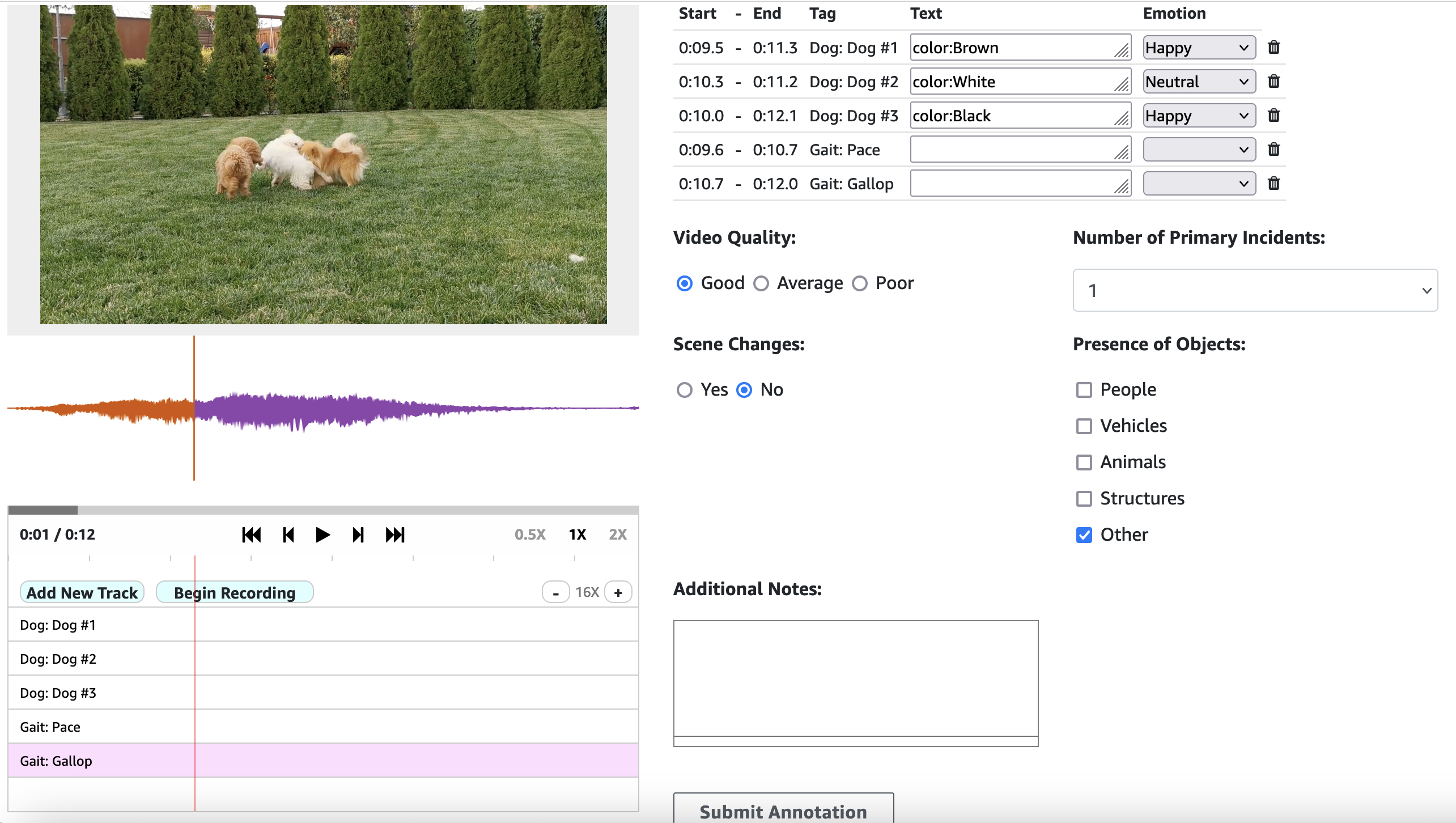
In this snapshot of video segmentation, we’re annotating a scene with dogs, tracking individual animals, their colors, emotions, and gaits. The UI also enables overall video quality assessment, scene change detection, and object presence classification.
Annotation process
Annotators begin by choosing Add New Track and selecting appropriate categories and tags for their annotation task. After you create the track, you can choose Begin Recording at the point where you want to start a segment. As the content plays, you can monitor the audio waveform or video frames until you reach the desired end point, then choose Stop Recording. The newly created segment appears in the right pane, where you can add classifications, transcriptions, or other relevant labels. This process can be repeated for as many segments as needed, with the ability to adjust segment boundaries, delete incorrect segments, or create new tracks for different annotation purposes.

Importance of high-quality data and reducing labeling errors
High-quality data is essential for training generative ai models that can produce natural, human-like audio and video content. The performance of these models depends directly on the accuracy and detail of human feedback, which stems from the precision and completeness of the annotation process. For audio and video content, this means capturing not just what sounds or looks unnatural, but exactly when and how these issues occur.
Our purpose built UI in SageMaker Ground Truth addresses common challenges in audio and video annotation that often lead to inconsistent or imprecise feedback. When annotators work with long audio or video files, they need to mark precise moments where generated content deviates from natural human expectations. For example, in speech generation, an unnatural pause might last only a fraction of a second, but its impact on perceived quality is significant. The tool’s zoom functionality allows annotators to expand these brief moments across their screen, making it possible to mark the exact start and end points of these subtle issues. This precision helps models learn the fine details that separate natural from artificial-sounding speech.
Solution overview
This audio/video segmentation solution combines several AWS services to create a robust annotation workflow. At its core, amazon Simple Storage Service (amazon S3) serves as the secure storage for input files, manifest files, annotation outputs, and the web UI components. SageMaker Ground Truth provides annotators with a web portal to access their labeling jobs and manages the overall annotation workflow. The following diagram illustrates the solution architecture.
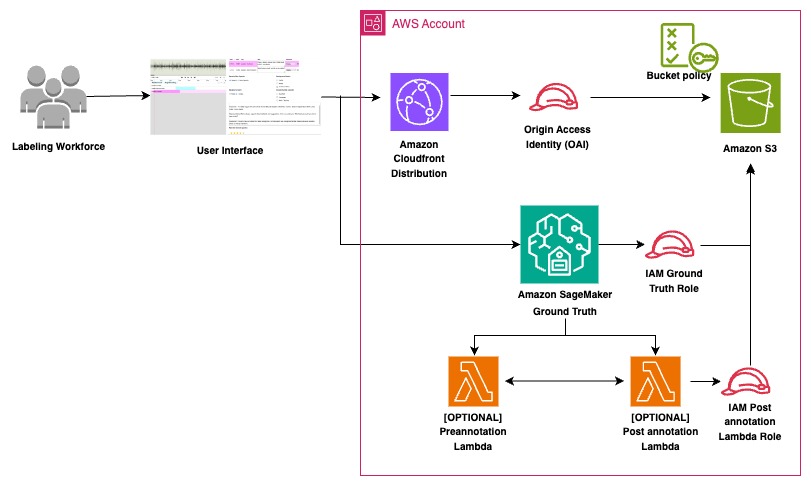
The UI template, which includes our specialized audio/video segmentation interface built with Wavesurfer.js, requires specific JavaScript and CSS files. These files are hosted through amazon CloudFront distribution, providing reliable and efficient delivery to annotators’ browsers. By using CloudFront with an origin access identity and appropriate bucket policies, we allow the UI components to be served to annotators. This setup follows AWS best practices for least-privilege access, making sure CloudFront can only access the specific UI files needed for the annotation interface.
Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. The pre-annotation Lambda function can process the input manifest file before data is presented to annotators, enabling any necessary formatting or modifications. Similarly, the post-annotation Lambda function can transform the annotation outputs into specific formats required for model training. These functions provide flexibility to adapt the workflow to specific needs without requiring changes to the core annotation process.
The solution uses AWS Identity and Access Management (IAM) roles to manage permissions:
- A SageMaker Ground Truth IAM role enables access to amazon S3 for reading input files and writing annotation outputs
- If used, Lambda function roles provide the necessary permissions for preprocessing and postprocessing tasks
Let’s walk through the process of setting up your annotation workflow. We start with a simple scenario: you have an audio file stored in amazon S3, along with some metadata like a call ID and its transcription. By the end of this walkthrough, you will have a fully functional annotation system where your team can segment and classify this audio content.
Prerequisites
For this walkthrough, make sure you have the following:
Create your internal workforce
Before we dive into the technical setup, let’s create a private workforce in SageMaker Ground Truth. This allows you to test the annotation workflow with your internal team before scaling to a larger operation.
- On the SageMaker console, choose Labeling workforces.
- Choose Private for the workforce type and create a new private team.
- Add team members using their email addresses—they will receive instructions to set up their accounts.
Deploy the infrastructure
Although this demonstrates using a CloudFormation template for quick deployment, you can also set up the components manually. The assets (JavaScript and CSS files) are available in our GitHub repository. Complete the following steps for manual deployment:
- Download these assets directly from the GitHub repository.
- Host them in your own S3 bucket.
- Set up your own CloudFront distribution to serve these files.
- Configure the necessary permissions and CORS settings.
This manual approach gives you more control over infrastructure setup and might be preferred if you have existing CloudFront distributions or a need to customize security controls and assets.
The rest of this post will focus on the CloudFormation deployment approach, but the labeling job configuration steps remain the same regardless of how you choose to host the UI assets.

This CloudFormation template creates and configures the following AWS resources:
- S3 bucket for UI components:
- Stores the UI JavaScript and CSS files
- Configured with CORS settings required for SageMaker Ground Truth
- Accessible only through CloudFront, not directly public
- Permissions are set using a bucket policy that grants read access only to the CloudFront Origin Access Identity (OAI)
- CloudFront distribution:
- Provides secure and efficient delivery of UI components
- Uses an OAI to securely access the S3 bucket
- Is configured with appropriate cache settings for optimal performance
- Access logging is enabled, with logs being stored in a dedicated S3 bucket
- S3 bucket for CloudFront logs:
- Stores access logs generated by CloudFront
- Is configured with the required bucket policies and ACLs to allow CloudFront to write logs
- Object ownership is set to ObjectWriter to enable ACL usage for CloudFront logging
- Lifecycle configuration is set to automatically delete logs older than 90 days to manage storage
- Lambda function:
- Downloads UI files from our GitHub repository
- Stores them in the S3 bucket for UI components
- Runs only during initial setup and uses least privilege permissions
- Permissions include amazon CloudWatch Logs for monitoring and specific S3 actions (read/write) limited to the created bucket
After the CloudFormation stack deployment is complete, you can find the CloudFront URLs for accessing the JavaScript and CSS files on the AWS CloudFormation console. You need these CloudFront URLs to update your UI template before creating the labeling job. Note these values—you will use them when creating the labeling job.
Prepare your input manifest
Before you create the labeling job, you need to prepare an input manifest file that tells SageMaker Ground Truth what data to present to annotators. The manifest structure is flexible and can be customized based on your needs. For this post, we use a simple structure:
You can adapt this structure to include additional metadata that your annotation workflow requires. For example, you might want to add speaker information, timestamps, or other contextual data. The key is making sure your UI template is designed to process and display these attributes appropriately.
Create your labeling job
With the infrastructure deployed, let’s create the labeling job in SageMaker Ground Truth. For full instructions, refer to Accelerate custom labeling workflows in amazon SageMaker Ground Truth without using AWS Lambda.
- On the SageMaker console, choose Create labeling job.
- Give your job a name.
- Specify your input data location in amazon S3.
- Specify an output bucket where annotations will be stored.
- For the task type, select Custom labeling task.
- In the UI template field, locate the placeholder values for the JavaScript and CSS files and update as follows:
- Replace
audiovideo-wavesufer.jswith your CloudFront JavaScript URL from the CloudFormation stack outputs. - Replace
audiovideo-stylesheet.csswith your CloudFront CSS URL from the CloudFormation stack outputs.
- Replace
- Before you launch the job, use the Preview feature to verify your interface.
You should see the Wavesurfer.js interface load correctly with all controls working properly. This preview step is crucial—it confirms that your CloudFront URLs are correctly specified and the interface is properly configured.
Programmatic setup
Alternatively, you can create your labeling job programmatically using the CreateLabelingJob API. This is particularly useful for automation or when you need to create multiple jobs. See the following code:
The API approach offers the same functionality as the SageMaker console, but allows for automation and integration with existing workflows. Whether you choose the SageMaker console or API approach, the result is the same: a fully configured labeling job ready for your annotation team.
Understanding the output
After your annotators complete their work, SageMaker Ground Truth will generate an output manifest in your specified S3 bucket. This manifest contains rich information at two levels:
- Segment-level classifications – Details about each marked segment, including start and end times and assigned categories
- Full-content classifications – Overall ratings and classifications for the entire file
Let’s look at a sample output to understand its structure:
This two-level annotation structure provides valuable training data for your ai models, capturing both fine-grained details and overall content assessment.
Customizing the solution
Our audio/video segmentation solution is designed to be highly customizable. Let’s walk through how you can adapt the interface to match your specific annotation requirements.
Customize segment-level annotations
The segment-level annotations are controlled in the report() function of the JavaScript code. The following code snippet shows how you can modify the annotation options for each segment:






{kind=link}