
The rise of large language models (LLMs) like Gemini and GPT-4 has transformed creative writing and dialogue generation, enabling machines to produce text that closely mirrors human creativity. These models are valuable tools for storytelling, content creation, and interactive systems, but evaluating the quality of their outputs remains challenging. Traditional human evaluation is subjective and labor-intensive, which makes it difficult to objectively compare the models on qualities like creativity, coherence, and engagement.
This blog aims to evaluate Gemini and GPT-4 on creative writing and dialogue generation tasks using an LLM-based reward model as a “judge.” By leveraging this methodology, we seek to provide more objective and repeatable results. The LLM-based model will assess the generated outputs based on key criteria, offering insights into which model excels in coherence, creativity, and engagement for each task.
Learning Objectives
- Learn how large language models (LLMs) can be utilized as “judges” to evaluate other models’ text generation outputs.
- Understand the evaluation metrics such as coherence, creativity, and engagement and how the judge models score these factors
- Gain insight into the strengths and weaknesses of Gemini and GPT-4o Mini for creative writing and dialogue generation tasks.
- Understand the process of generating text using Gemini and GPT-4o Mini, including creative writing and dialogue generation tasks.
- Learn how to implement and use an LLM-based reward model, like NVIDIA’s Nemotron-4-340B, to evaluate the text quality generated by different models.
- Understand how these judge models provide a more consistent, objective, and comprehensive evaluation of text generation quality across multiple metrics.
This article was published as a part of the Data Science Blogathon.
Introduction to LLMs as Judges
An LLM-based judge is a specialized language model trained to evaluate the performance of other models on various dimensions of text generation, such as coherence, creativity, and engagement. These judge models function similarly to human evaluators, but instead of subjective opinions, they provide quantitative scores based on established criteria. The advantage of using LLMs as judges is that they offer consistency and objectivity in the evaluation process, making them ideal for assessing large volumes of generated content across different tasks.
To train an LLM as a judge, the model is fine-tuned on a specific dataset that includes feedback about the quality of text generated in areas such as logical consistency, originality, and the capacity to captivate readers. This allows the judging model to automatically assign scores based on how well the text adheres to predefined standards for each attribute.
In this context, the LLM-based judge evaluates generated text from models like Gemini or GPT-4o Mini, providing insights into how well these models perform on subjective qualities that are otherwise challenging to measure.
Why Use an LLM as a Judge?
Using an LLM as a judge comes with many benefits, especially in tasks requiring complex assessments of generated text. Some key advantages of using an LLM-based judge are:
- Consistency: Unlike human evaluators, who may have varying opinions depending on their experiences and biases, LLMs provide consistent evaluations across different models and tasks. This is especially important in comparative analysis, where multiple outputs must be evaluated on the same criteria.
- Objectivity: LLM judges can assign scores based on hard, quantifiable factors such as logical consistency or originality, making the evaluation process more objective. This marked improvement over human-based evaluations, which may vary in subjective interpretation.
- Scalability: Evaluating many generated outputs manually is time-consuming and impractical. LLMs can automatically evaluate hundreds or thousands of responses, providing a scalable solution for large-scale analysis across multiple models.
- Versatility: LLM-based reward models can evaluate text based on several criteria, allowing researchers to assess models in various dimensions simultaneously, including:
Example of Judge Models
One prominent example of an LLM-based reward model is NVIDIA’s Nemotron-4-340B Reward Model. This model is designed to assess text generated by other LLMs and assign scores based on various dimensions. The NVIDIA’s Nemotron-4-340B model evaluates responses based on helpfulness, correctness, coherence, complexity, and verbosity. It assigns a numerical score that reflects the quality of a given response across these criteria. For example, it might score a creative writing piece higher on creativity if it introduces novel concepts or vivid imagery while penalizing a response that lacks logical flow or introduces contradictory statements.
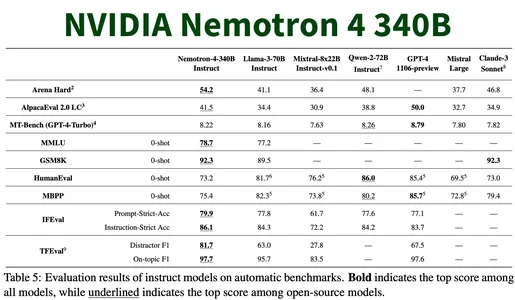
The scores provided by such judge models can help inform the comparative analysis between different LLMs, providing a more structured approach to evaluating their outputs. This contrasts with relying on human ratings, which are often subjective and inconsistent.
Setting Up the Experiment: Text Generation with Gemini and GPT-4o Mini
In this section, we will walk through the process of generating text from Gemini and GPT-4o Mini for both creative writing and dialogue generation tasks. We will generate responses to a creative writing prompt and a dialogue generation prompt from both models so we can later evaluate these outputs using a judge model (like NVIDIA’s Nemotron-4-340B).
Text Generation
- Creative Writing Task: The first task is to generate a creative story. In this case, we will prompt both models with the task:”Write a creative story on a lost spaceship in 500 words.” The goal is to evaluate the creativity, coherence, and narrative quality of the generated text.
- Dialogue Generation Task: The second task is to generate a dialogue between two characters. We prompt both models with:”A conversation between an astronaut and an alien. Write in a dialogue format between Astronaut and Alien.” This allows us to evaluate how well the models handle dialogue, including the interaction between characters and the flow of conversation.
Code Snippet: Generating Text from Gemini and GPT-4o Mini
The following code snippet demonstrates how to invoke Gemini and GPT-4o Mini APIs to generate responses for the two tasks.
# Import necessary libraries
import openai
from langchain_google_genai import ChatGoogleGenerativeAI
# Set the OpenAI and Google API keys
OPENAI_API_KEY = 'your_openai_api_key_here'
GOOGLE_API_KEY = 'your_google_api_key_here'
# Initialize the Gemini model
gemini = ChatGoogleGenerativeAI(model="gemini-1.5-flash-002")
# Define the creative writing and dialogue prompts
story_question = "your_story_prompt"
dialogue_question = "your_dialogue_prompt"
# Generate text from Gemini for creative writing and dialogue tasks
gemini_story = gemini.invoke(story_question).content
gemini_dialogue = gemini.invoke(dialogue_question).content
# Print Gemini responses
print("Gemini Creative Story: ", gemini_story)
print("Gemini Dialogue: ", gemini_dialogue)
# Initialize the GPT-4o Mini model (OpenAI API)
openai.api_key = OPENAI_API_KEY
# Generate text from GPT-4o Mini for creative writing and dialogue tasks
gpt_story1 = openai.chat.completions.create(
model="gpt-4o-mini",
messages=({"role": "user", "content": story_question1}),
max_tokens=500, # Maximum length for the creative story
temperature=0.7, # Control randomness
top_p=0.9, # Nucleus sampling
n=1 # Number of responses to generate
).choices(0).message
gpt_dialogue1 = openai.chat.completions.create(
model="gpt-4o-mini",
messages=({"role": "user", "content": dialogue_question1}),
temperature=0.7, # Control randomness
top_p=0.9, # Nucleus sampling
n=1 # Number of responses to generate
).choices(0).message
# Print GPT-4o Mini responses
print("GPT-4o Mini Creative Story: ", gpt_story1)
print("GPT-4o Mini Dialogue: ", gpt_dialogue1)Explanation
- Gemini API Call: The ChatGoogleGenerativeAI class from the langchain_google_genai library is used to interact with the Gemini API. We provide the creative writing and dialogue prompts to Gemini and retrieve its responses using the invoke method.
- GPT-4o Mini API Call: The OpenAI API is used to generate responses from GPT-4o Mini. We provide the same prompts for creative writing and dialogue and specify additional parameters such as max_tokens (to limit the length of the response), temperature (for controlling randomness), and top_p (for nucleus sampling).
- Outputs: The generated responses from both models are printed out, which will then be used for evaluation by the judge model.
This setup enables us to gather outputs from both Gemini and GPT-4o Mini, ready to be evaluated in the subsequent steps based on coherence, creativity, and engagement, among other attributes.
Using LLM as a Judge: Evaluation Process
In the realm of text generation, evaluating the quality of outputs is as important as the models themselves. Using Large Language Models (LLMs) as judges offers a novel approach to assessing creative tasks, allowing for a more objective and systematic evaluation. This section delves into the process of using LLMs, such as NVIDIA’s Nemotron-4-340B reward model, to evaluate the performance of other language models in creative writing and dialogue generation tasks.
Model Selection
For evaluating the text generated by Gemini and GPT-4o Mini, we utilize NVIDIA’s Nemotron-4-340B Reward Model. This model is designed to assess text quality on multiple dimensions, providing a structured, numerical scoring system for various aspects of text generation. By using NVIDIA’s Nemotron-4-340B, we aim to achieve a more standardized and objective evaluation compared to traditional human ratings, ensuring consistency across model outputs.
The Nemotron model assigns scores based on five key factors: helpfulness, correctness, coherence, complexity, and verbosity. These factors are essential in determining the overall quality of the generated text, and each plays a vital role in ensuring that the model’s evaluation is thorough and multidimensional.
Metrics for Evaluation
The NVIDIA’s Nemotron-4-340B Reward Model evaluates generated text across several key metrics:
- Helpfulness: This metric assesses whether the response provides value to the reader, answering the question or fulfilling the task’s intent.
- Correctness: This measures the factual accuracy and consistency of the text.
- Coherence: Coherence measures how logically and smoothly the ideas in the text are connected.
- Complexity: Complexity evaluates how advanced or sophisticated the language and ideas are.
- Verbosity: Verbosity measures how concise or wordy the text is.
Scoring Process
Each score is assigned on a 0 to 5 scale, with higher scores reflecting better performance. These scores allow for a structured comparison of different LLM-generated outputs, providing insights into where each model excels and improvements are needed.
Below is the code used to score the responses from both models using NVIDIA’s Nemotron-4-340B Reward Model:
import json
import os
from openai import OpenAI
from langchain_google_genai import ChatGoogleGenerativeAI
# Set up API keys and model access
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=os.environ('Nvidia_API_Key') # Accessing the secret key
)
def score_responses(model_responses_json):
with open(model_responses_json, 'r') as file:
data = json.load(file)
for item in data:
question = item('question') # Extract the question
answer = item('answer') # Extract the answer
# Prepare messages for the judge model
messages = (
{"role": "user", "content": question},
{"role": "assistant", "content": answer}
)
# Call the Nemotron model to get scores
completion = client.chat.completions.create(
model="nvidia/nemotron-4-340b-reward",
messages=messages
)
# Access the scores from the response
scores_message = completion.choices(0).message(0).content # Accessing the score content
scores = scores_message.strip() # Clean up the content if needed
# Print the scores for the current question-answer pair
print(f"Question: {question}")
print(f"Scores: {scores}")
# Example of using the scoring function on responses from Gemini or GPT-4o Mini
score_responses('gemini_responses.json') # For Gemini responses
score_responses('gpt_responses.json') # For GPT-4o Mini responsesThis code loads the question-answer pairs from the respective JSON files and then sends them to the NVIDIA’s Nemotron-4-340B Reward Model for evaluation. The model returns scores for each response, which are printed to give an insight into how each generated text performs across the various dimensions. In the subsequent section, we will use the codes of both section 2 and section 3 to experiment and derive conclusions about the LLM capabilities and learn how to use another large language model as a judge.
Experimentation and Results: Comparing Gemini and GPT-4
This section presents a detailed comparison of how the Gemini and GPT-4 models performed across five creative story prompts and five dialogue prompts. These tasks assessed the models’ creativity, coherence, complexity, and engagement abilities. Each prompt is followed by specific scores evaluated on helpfulness, correctness, coherence, complexity, and verbosity. The following sections will break down the results for each prompt type. Note the hyperparameters of both LLMs were kept the same for the experiments.
Creative Story Prompts Evaluation
Evaluating creative story prompts with LLMs involves assessing the originality, structure, and engagement of the narratives. This process ensures that ai-generated content meets high creative standards while maintaining coherence and depth.
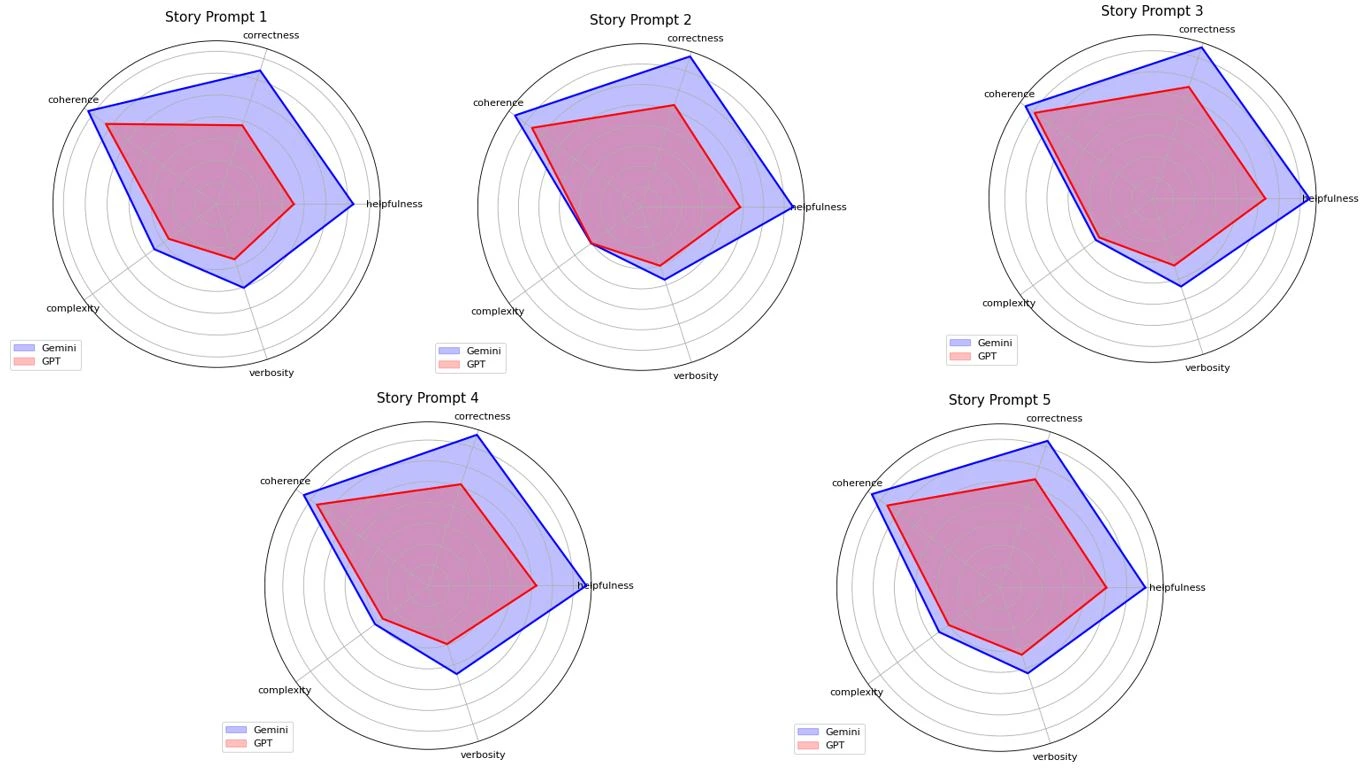
Story Prompt 1
Prompt: Write a creative story on a lost spaceship in 500 words.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.1 | 3.2 | 3.6 | 1.8 | 2.0 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 1.7 | 1.8 | 3.1 | 1.3 | 1.3 |
Output Explanation and Analysis
- Gemini’s Performance: Gemini received moderate scores across the board, with a helpfulness score of 3.1, coherence of 3.6, and correctness of 3.2. These scores suggest that the response is fairly structured and accurate in its representation of the prompt. However, it scored low in complexity (1.8) and verbosity (2.0), indicating that the story lacked depth and intricate details, which could have made it more engaging. Despite this, it performs better than GPT-4o Mini in terms of coherence and correctness.
- GPT-4o Mi’s Performance: GPT-4o, on the other hand, received lower scores overall: 1.7 for helpfulness, 1.8 for correctness, 3.1 for coherence, and relatively low scores for complexity (1.3) and verbosity (1.3). These low scores suggest that GPT-4o Mini’s response was less effective in terms of accurately addressing the prompt, offering less complexity and less detailed descriptions. The coherence score of 3.1 implies the story is fairly understandable, but the response lacks the depth and detail that would elevate it beyond a basic response.
- Analysis: While both models produced readable content, Gemini’s story appears to have a better overall structure, and it fits the prompt more effectively. However, both models show room for improvement in terms of adding complexity, creativity, and engaging descriptions to make the story more immersive and captivating.
Story Prompt 2
Prompt: Write a short fantasy story set in a medieval world.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.7 | 3.8 | 3.8 | 1.5 | 1.8 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 2.4 | 2.6 | 3.2 | 1.5 | 1.5 |
Output Explanation and Analysis
- Gemini’s Performance: Gemini performed better across most metrics, scoring 3.7 for helpfulness, 3.8 for correctness, and 3.8 for coherence. These scores suggest that the story is clear, coherent, and well-aligned with the prompt. However, the complexity score of 1.5 and verbosity score of 1.8 indicate that the story may be relatively simplistic, lacking in depth and detail, and could benefit from more elaborate world-building and complex narrative elements typical of the fantasy genre.
- GPT-4o’s Performance: GPT-4o received lower scores, with a helpfulness score of 2.4, correctness of 2.6, and coherence of 3.2. These scores reflect a decent overall understanding of the prompt but with room for improvement in how well the story adheres to the medieval fantasy setting. Its complexity and verbosity scores were both lower than Gemini’s (1.5 for both), suggesting that the response may have lacked the intricate descriptions and varied sentence structures that are expected in a more immersive fantasy narrative.
- Analysis: While both models generated relatively coherent responses, Gemini’s output is notably stronger in helpfulness and correctness, implying a more accurate and fitting response to the prompt. However, both stories could benefit from more complexity and detail, especially in creating a rich, engaging medieval world. Gemini’s slightly higher verbosity score indicates a better attempt at creating a more immersive narrative, although both models fell short of creating truly complex and captivating fantasy worlds.
Story Prompt 3
Prompt: Create a story about a time traveler discovering a new civilization.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.7 | 3.8 | 3.7 | 1.7 | 2.1 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 2.7 | 2.8 | 3.4 | 1.6 | 1.6 |
Output Explanation and Analysis
- Gemini’s Performance: Gemini scored high in helpfulness (3.7), correctness (3.8), and coherence (3.7), which shows a good alignment with the prompt and clear narrative structure. These scores indicate that Gemini generated a story that was not only helpful and accurate but also easy to follow. However, the complexity score of 1.7 and verbosity score of 2.1 suggest that the story may have been somewhat simplistic and lacked the depth and richness expected in a time-travel narrative. While the story might have had a clear plot, it could have benefitted from more complexity in terms of the civilizations’ features, cultural differences, or the time travel mechanics.
- GPT-4o’s Performance: GPT-4o performed slightly lower, with a helpfulness score of 2.7, correctness of 2.8, and coherence of 3.4. The coherence score is still fairly good, suggesting that the narrative was logical, but the lower helpfulness and correctness scores indicate some areas of improvement, especially regarding the accuracy and relevance of the story details. The complexity score of 1.6 and verbosity score of 1.6 are notably low, suggesting that the narrative may have been quite straightforward, without much exploration of the time travel concept or the new civilization in depth.
- Analysis: Gemini’s output is stronger in terms of helpfulness, correctness, and coherence, indicating a more solid and fitting response to the prompt. However, both models exhibited limitations in terms of complexity and verbosity, which are crucial for crafting intricate, engaging time-travel narratives. More detailed exploration of the time travel mechanism, the discovery process, and the new civilization’s attributes could have added depth and made the stories more immersive. While GPT-4o’s coherence is commendable, its lower scores in helpfulness and complexity suggest that the story might have felt more simplistic in comparison to Gemini’s more coherent and accurate response.
Story Prompt 4
Prompt: Write a story where two friends explore a haunted house.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.8 | 3.8 | 3.7 | 1.5 | 2.2 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 2.6 | 2.5 | 3.3 | 1.3 | 1.4 |
Output Explanation and Analysis
Gemini provided a more detailed and coherent response, lacking complexity and a deeper exploration of the haunted house theme. GPT-4o was less helpful and correct, with a simpler, less developed story. Both could have benefited from more atmospheric depth and complexity.
Story Prompt 5
Prompt: Write a tale about a scientist who accidentally creates a black hole.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.4 | 3.6 | 3.7 | 1.5 | 2.2 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 2.5 | 2.6 | 3.2 | 1.5 | 1.7 |
Output Explanation and Analysis
Gemini provided a more coherent and detailed response, albeit with simpler scientific concepts. It was a well-structured tale but lacked complexity and scientific depth. GPT-4o, while logically coherent, did not provide as much useful detail and missed opportunities to explore the implications of creating a black hole, offering a simpler version of the story. Both could benefit from further development in terms of scientific accuracy and narrative complexity.
Dialogue Prompts Evaluation
Evaluating dialogue prompts with LLMs focuses on the natural flow, character consistency, and emotional depth of conversations. This ensures the generated dialogues are authentic, engaging, and contextually relevant.
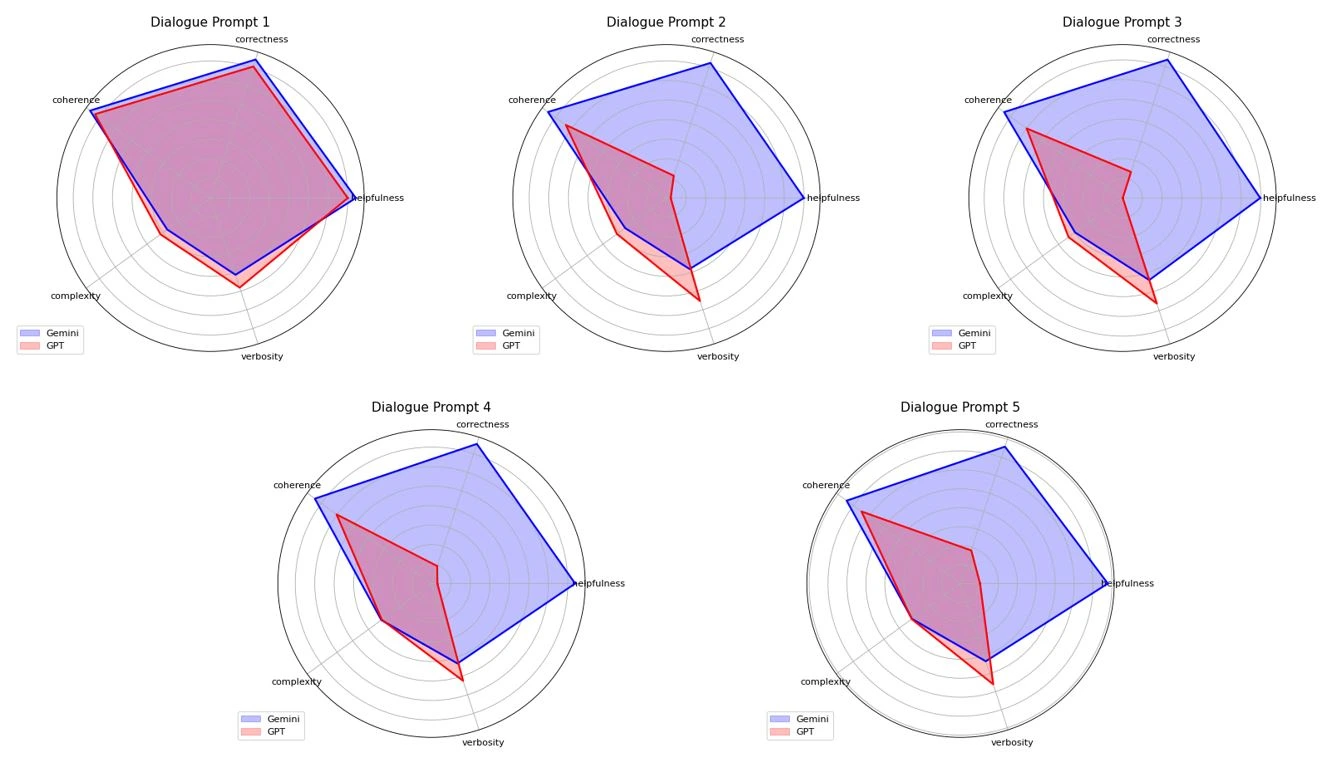
Dialogue Prompt 1
Prompt: A conversation between an astronaut and an alien. Write in a dialogue format between an Astronaut and an Alien.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.7 | 3.7 | 3.8 | 1.3 | 2.0 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.5 | 3.5 | 3.6 | 1.5 | 2.4 |
Output Explanation and Analysis
Gemini provided a more coherent and slightly more complex dialogue between the astronaut and the alien, focusing on communication and interaction in a structured manner. The response, while simple, was consistent with the prompt, offering a clear flow between the two characters. However, the complexity and depth were still minimal.
GPT-4o, on the other hand, delivered a slightly less coherent response but had better verbosity and maintained a smoother flow in the dialogue. Its complexity was somewhat limited, but the character interactions had more potential for depth. Both models performed similarly in terms of helpfulness and correctness, though both could benefit from more intricate dialogue or exploration of themes such as communication challenges or the implications of encountering an alien life form.
Dialogue Prompt 2
Prompt: Generate a dialogue between a knight and a dragon in a medieval kingdom.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.5 | 3.6 | 3.7 | 1.3 | 1.9 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 0.1 | 0.5 | 3.1 | 1.5 | 2.7 |
Output Explanation and Analysis
Gemini demonstrated a solid level of coherence, with clear and relevant interactions in the dialogue. The complexity and verbosity remained controlled, aligning well with the prompt. The response showed a good balance between clarity and structure, though it could have benefited from more engaging or detailed content.
GPT-4o, however, struggled significantly in this case. Its response was notably less coherent, with issues in maintaining a smooth conversation flow. While the complexity was relatively consistent, the helpfulness and correctness were low, resulting in a dialogue that lacked the depth and clarity expected from a model with its capabilities. It also showed high verbosity that didn’t necessarily add value to the content, indicating room for improvement in relevance and focus.
In this case, Gemini outperformed GPT-4o regarding coherence and overall dialogue quality.
Dialogue Prompt 3
Prompt: Create a conversation between a detective and a suspect at a crime scene.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.4 | 3.6 | 3.7 | 1.4 | 2.1 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 0.006 | 0.6 | 3.0 | 1.6 | 2.8 |
Output Explanation and Analysis
Gemini delivered a well-rounded and coherent dialogue, maintaining clarity and relevance throughout. The complexity and verbosity were balanced, making the interaction engaging without being overly complicated.
GPT-4o, on the other hand, struggled in this case, particularly with helpfulness and correctness. The response lacked cohesion, and while the complexity was moderate, the dialogue failed to meet expectations in terms of clarity and effectiveness. The verbosity was also high without adding value, which detracted from the overall quality of the response.
Dialogue Prompt 4
Prompt: Write a conversation about its purpose between a robot and its creator.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.6 | 3.8 | 3.7 | 1.5 | 2.1 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 0.1 | 0.6 | 3.0 | 1.6 | 2.6 |
Output Explanation and Analysis
Gemini exhibited strong performance with clarity and coherence, producing a well-structured and relevant dialogue. It balanced complexity and verbosity effectively, contributing to a good flow and easy readability.
GPT-4o, however, fell short, especially in terms of helpfulness and correctness. While it maintained coherence, the dialogue lacked the depth and clarity of Gemini’s response. The response was verbose without adding to the overall quality, and the helpfulness score was low, indicating that the content didn’t provide sufficient value or insight.
Dialogue Prompt 5
Prompt: Generate a dialogue between a teacher and a student discussing a difficult subject.
Gemini Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 3.8 | 3.7 | 3.7 | 1.5 | 2.1 |
GPT-4 Response and Judge Scores:

| Helpfulness | Corectness | Coherence | Complexity | Verbosity |
|---|---|---|---|---|
| 0.5 | 0.9 | 3.2 | 1.5 | 2.7 |
Output Explanation and Analysis
Gemini provided a clear, coherent dialogue with a good balance between complexity and verbosity, creating an informative and relatable exchange between the teacher and the student. It scored well across all aspects, indicating a strong response.
GPT-4o, on the other hand, struggled in terms of helpfulness and correctness, offering a less structured and informative dialogue. The response was still coherent, but the complexity and verbosity did not enhance the quality, leading to a less engaging and less valuable output overall.
Graphical Representation of Model Performance
To help visualize each model’s performance, we include radar plots comparing the scores of Gemini and GPT-4 for creative story prompts and dialogue prompts. These plots show how the models differ in their performance based on the five evaluation metrics: helpfulness, correctness, coherence, complexity, and verbosity.
Below you can see dialogue prompt model performance:
Discussion: Insights from the Evaluation
Creative Story Evaluation:
- Gemini’s Strengths: Gemini consistently performed well in correctness and coherence for the story prompts, often producing more logical and structured narratives. However, it was less creative than GPT-4, especially in the more abstract story prompts.
- GPT-4’s Strengths: GPT-4 excelled at creativity, often creating more imaginative and original narratives. However, its responses were sometimes less coherent, showing a weaker structure in the storyline.
Dialogue Evaluation:
- Gemini’s Strengths: Gemini performed better in engagement and coherence when generating dialogues, as its responses were well-aligned with the conversational flow.
- GPT-4’s Strengths: GPT-4 produced more varied and dynamic dialogues, demonstrating creativity and verbosity, but sometimes at the expense of coherence or relevance to the prompt.
Overall Insights:
- Creativity vs. Coherence: While GPT-4 favors creativity, producing more abstract and inventive responses, Gemini’s strengths are maintaining coherence and correctness, especially useful for more structured tasks.
- Verbosity and Complexity: Both models exhibit their unique strengths in terms of verbosity and complexity. Gemini maintains clarity and conciseness, while GPT-4 occasionally becomes more verbose, contributing to more complex and nuanced dialogues and stories.
Conclusion
The comparison between Gemini and GPT-4 for creative writing and dialogue generation tasks highlights key differences in their strengths. Both models exhibit impressive abilities in text generation, but their performance varies in terms of specific attributes such as coherence, creativity, and engagement. Gemini excels in creativity and engagement, generating more imaginative and interactive content, while GPT-4o Mini stands out for its coherence and logical flow. The use of an LLM-based reward model as a judge provided an objective and multi-dimensional evaluation, offering deeper insights into the nuances of each model’s output. This method allows for a more thorough assessment than traditional metrics and human evaluation.
The results underline the importance of selecting the right model based on task requirements, with Gemini being suitable for more creative tasks and GPT-4o Mini being better for tasks requiring structured and coherent responses. Additionally, the application of an LLM as a judge can help refine model evaluation processes, ensuring consistency and improving decision-making in selecting the most appropriate model for specific applications in creative writing, dialogue generation, and other natural language tasks.
Additional Note: If you feel inquisitive about exploring further, feel free to use the colab notebook for the blog.
Key Takeaways
- Gemini excels in creativity and engagement, making it ideal for tasks requiring imaginative and captivating content.
- GPT-4o Mini offers superior coherence and logical structure, making it better suited for tasks needing clarity and precision.
- Using an LLM-based judge ensures an objective, consistent, and multi-dimensional evaluation of model performance, especially for creative and conversational tasks.
- LLMs as judges enable informed model selection, providing a clear framework for choosing the most suitable model based on specific task requirements.
- This approach has real-world applications in entertainment, education, and customer service, where the quality and engagement of generated content are paramount.
Frequently Asked Questions
A. An LLM can act as a judge to evaluate the output of other models, scoring them on coherence, creativity, and engagement. Using fine-tuned reward models, this approach ensures consistent and scalable assessments, highlighting strengths and weaknesses in text generation beyond just fluency, including originality and reader engagement.
A. Gemini excels in creative, engaging tasks, producing imaginative and interactive content, while GPT-4o Mini shines in tasks needing logical coherence and structured text, ideal for clear, logical applications. Each model offers unique strengths depending on the project’s needs.
A. Gemini excels in generating creative, attention-grabbing content, ideal for tasks like creative writing, while GPT-4o Mini focuses on coherence and structure, making it better for tasks like dialogue generation. Using an LLM-based judge helps users understand these differences and choose the right model for their needs.
A. An LLM-based reward model offers a more objective and comprehensive text evaluation than human or rule-based methods. It assesses multiple dimensions like coherence, creativity, and engagement, ensuring consistent, scalable, and reliable insights into model output quality for better decision-making.
A. NVIDIA’s Nemotron-4-340B serves as a sophisticated ai evaluator, assessing the creative outputs of models like Gemini and GPT-4. It analyzes key aspects such as coherence, originality, and engagement, providing an objective critique of ai-generated content.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.

Neil is a research professional currently working on the development of ai agents. He has successfully contributed to various ai projects across different domains, with his works published in several high-impact, peer-reviewed journals. His research focuses on advancing the boundaries of artificial intelligence, and he is deeply committed to sharing knowledge through writing. Through his blogs, Neil strives to make complex ai concepts more accessible to professionals and enthusiasts alike.





