
Large language models (LLMs) have demonstrated exceptional capabilities in various applications, but their widespread adoption faces significant challenges. The main concern arises from training data sets that contain varied, unfocused and potentially harmful content, including malicious code and information related to cyber attacks. This creates a critical need to align LLM outcomes with specific user requirements while avoiding misuse. Current approaches such as reinforcement learning from human feedback (RLHF) attempt to address these problems by incorporating human preferences into the model behavior. However, RLHF faces substantial limitations due to its high computational requirements, reliance on complex reward models, and the inherent instability of reinforcement learning algorithms. This situation requires more efficient and reliable methods to refine LLMs while maintaining their performance and ensuring responsible development of ai.
Various alignment methods have emerged to address the challenges of aligning LLMs with human preferences. Initially, RLHF gained prominence by using a reward model trained with human preference data, combined with reinforcement learning algorithms such as PPO to optimize the model's behavior. However, its complex implementation and resource-intensive nature led to the development of Direct Policy Optimization (DPO), which simplifies the process by eliminating the need for a reward model and using binary cross-entropy loss instead. Recent research has explored different measures of divergence to control for production diversity, focusing particularly on α divergence as a way to balance between inverse KL divergence and direct KL divergence. Additionally, researchers have investigated several approaches to improve response diversity, including temperature-based sampling techniques, rapid manipulation, and objective function modifications. The importance of diversity has become increasingly relevant, especially in tasks where coverage (the ability to solve problems across multiple generated samples) is crucial, such as in mathematical and coding applications.
Researchers from the University of Tokyo and Preferred Networks, Inc. present H-DPOa robust modification of the traditional DPO approach that addresses the limitations of mode search behavior. The key innovation lies in controlling the entropy of the resulting policy distribution, allowing for more effective capture of target distribution modes. Traditional inverse KL divergence minimization may sometimes fail to adequately achieve mode search fitting by preserving variance when fitting a unimodal distribution to a multimodal target. H-DPO addresses this by introducing a hyperparameter α that modifies the regularization term, allowing for a deliberate entropy reduction when α < 1. This approach aligns with practical observations that LLMs often perform better with lower temperature values during assessment. Unlike post-training temperature adjustments, H-DPO embeds this distribution adjustment directly into the training target, ensuring optimal alignment with the desired behavior while maintaining simplicity of implementation.
The H-DPO methodology introduces a robust approach to entropy control in language model alignment by modifying the inverse KL divergence regularization term. The method decomposes the inverse KL divergence into entropy and cross-entropy components, introducing a coefficient α that allows precise control over the entropy of the distribution. The objective function for H-DPO is formulated as JH-DPO, which combines the expected reward with the modified divergence term. When α is equal to 1, the function maintains the standard DPO behavior, but setting α below 1 encourages entropy reduction. Through constrained optimization using Lagrangian multipliers, the optimal policy is derived based on the reference policy and the reward, with α controlling the sharpness of the distribution. The implementation requires minimal modification to the existing DPO framework, which essentially involves replacing the coefficient β with αβ in the loss function, making it very practical for real-world applications.
Experimental evaluation of H-DPO demonstrated significant improvements across multiple benchmarks compared to standard DPO. The method was tested on various tasks, including elementary school mathematics problems (GSM8K), coding tasks (HumanEval), multiple-choice questions (MMLU-Pro), and instruction-following tasks (IFEval). By reducing α to values between 0.95 and 0.9, H-DPO achieved performance improvements across all tasks. Diversity metrics showed interesting trade-offs: lower α values resulted in reduced diversity at temperature 1, while higher α values increased diversity. However, the relationship between α and diversity was more complex when temperature variations were considered. On the GSM8K benchmark, H-DPO with α=0.8 achieved optimal coverage at a training temperature of 1, outperforming the best results of the standard DPO at a temperature of 0.5. Importantly, in HumanEval, larger α values (α=1.1) showed superior performance for large sampling scenarios (k>100), indicating that response diversity played a crucial role in performance. of coding tasks.
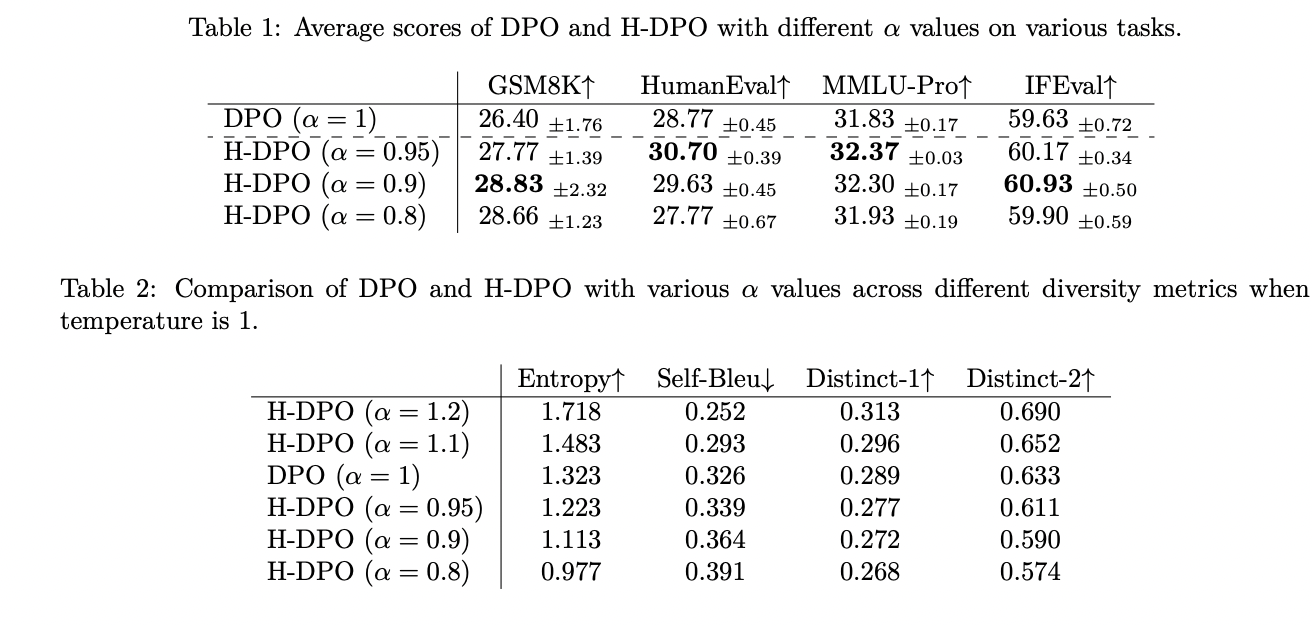
H-DPO represents a significant advance in language model alignment, offering a simple but effective modification to the standard DPO framework. Through its innovative entropy control mechanism via the hyperparameter α, the method achieves superior mode-finding behavior and enables finer control over the output distribution. Experimental results across several tasks demonstrated increased accuracy and diversity in model results, particularly excelling in mathematical reasoning and coverage metrics. While manual tuning of α remains a limitation, H-DPO's simple implementation and impressive performance make it a valuable contribution to the field of language model alignment, paving the way for more effective and controllable ai systems. .
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(<a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=newsletter” target=”_blank” rel=”noreferrer noopener”>FREE WEBINAR on ai) <a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=newsletter” target=”_blank” rel=”noreferrer noopener”>Implementation of intelligent document processing with GenAI in financial services and real estate transactions– <a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=banner-ad-desktop” target=”_blank” rel=”noreferrer noopener”>From framework to production
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}