
In the world of software development, there is a constant need for smarter, more capable and specialized coding language models. While existing models have made significant progress in automating code generation, completion, and reasoning, several problems remain. Key challenges include inefficiency in addressing a wide range of coding tasks, lack of domain-specific expertise, and difficulty in applying models to real-world coding scenarios. Despite the rise of many large language models (LLMs), code-specific models have often struggled to compete with their proprietary counterparts, especially in terms of versatility and applicability. The need for a model that not only performs well on standard benchmarks but also adapts to diverse environments has never been greater.
Qwen2.5-Coder: a new era of open source LLM
Qwen has opened the “powerful”, “diverse” and “practical” Qwen2.5-Coder series, dedicated to continuously promoting the development of open CodeLLM. The Qwen2.5-Coder series is based on the Qwen2.5 architecture and leverages its advanced architecture and expansive tokenizer to improve the efficiency and accuracy of coding tasks. Qwen has taken a significant step in opening up these models, making them accessible to developers, researchers, and industry professionals. This family of encoder models offers a variety of sizes, from 0.5B to 32B parameters, providing flexibility for a wide variety of coding needs. The launch of Qwen2.5-Coder-32B-Instruct comes at an opportune time, presenting itself as the most capable and practical encoder model in the Qwen series. It highlights Qwen's commitment to fostering innovation and advancing the field of open source coding models.
Technical details
Technically, Qwen2.5-Coder models have undergone extensive pre-training on a vast corpus of over 5.5 trillion tokens, including public code repositories and large-scale web-crawled data containing related texts. with codes. The model architecture is shared between different model sizes (parameters 1.5B and 7B) and features 28 layers with variations in hidden sizes and attention heads. Additionally, Qwen2.5-Coder has been refined using synthetic datasets generated by its predecessor, CodeQwen1.5, incorporating an executor to ensure that only executable code is retained, thus reducing the risks of hallucinations. The models are also designed to be versatile and support various pre-training objectives, such as code generation, completion, reasoning, and editing.
Next-generation performance
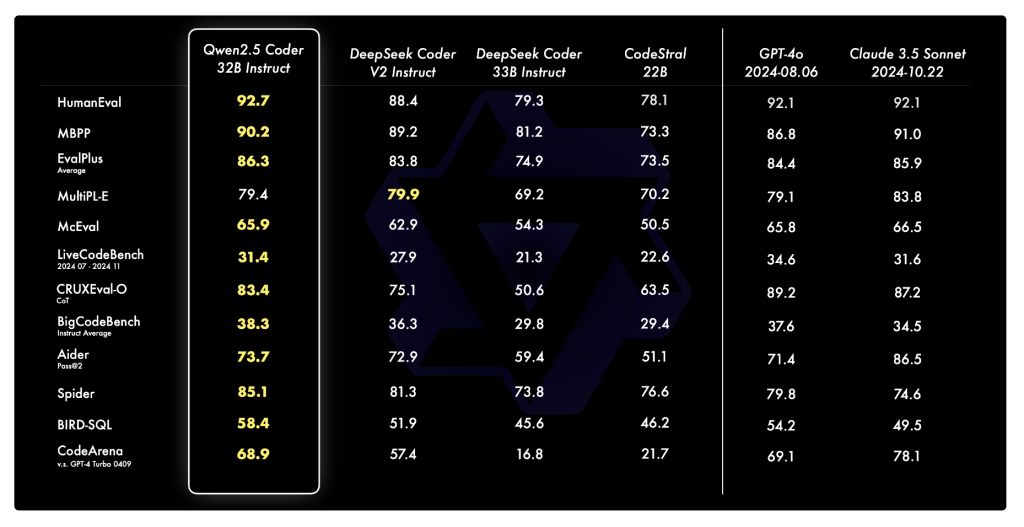
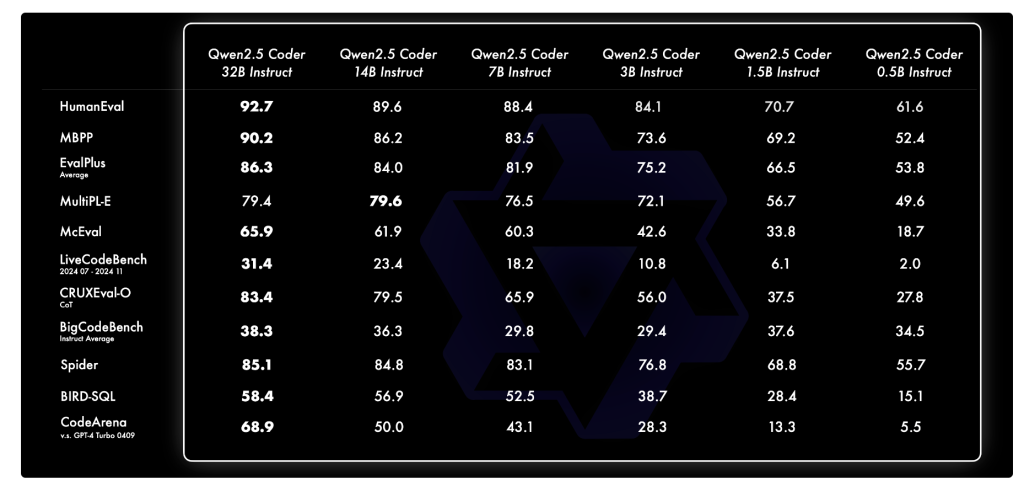
One of the reasons Qwen2.5-Coder stands out is its proven performance across multiple evaluation benchmarks. It has consistently achieved state-of-the-art (SOTA) performance on more than 10 benchmarks, including HumanEval and BigCodeBench, outperforming even some larger models. Specifically, Qwen2.5-Coder-7B-Base achieved higher accuracy on the HumanEval and MBPP benchmarks compared to models such as StarCoder2 and DeepSeek-Coder of comparable or even larger sizes. The Qwen2.5-Coder series also excels in multi-programming language capabilities, demonstrating balanced proficiency in eight languages, such as Python, Java and TypeScript. Additionally, Qwen2.5-Coder's long context capabilities are remarkably robust, making it suitable for handling code at the repository level and effectively supporting inputs of up to 128k tokens.
Scalability and Accessibility
Additionally, the availability of models in various parameter sizes (ranging from 0.5B to 32B), along with the option of quantized formats such as GPTQ, AWQ and GGUF, ensure that Qwen2.5-Coder can meet a wide range of requirements. computational. This scalability is crucial for developers and researchers who may not have access to high-end computational resources but still need to benefit from powerful coding capabilities. The versatility of Qwen2.5-Coder in supporting different formats makes it more accessible for practical use, allowing for wider adoption in various applications. This adaptability makes the Qwen2.5-Coder family a vital tool for promoting the development of open source coding assistants.
Conclusion
The Qwen2.5-Coder series open source marks an important step forward in the development of coding language models. By releasing powerful, diverse and practical models, Qwen has addressed the key limitations of existing code-specific models. The combination of next-generation performance, scalability and flexibility makes the Qwen2.5-Coder family a valuable asset to the global developer community. Whether you're looking to take advantage of the capabilities of a 0.5B model or need the expansive power of a 32B variant, the Qwen2.5-Coder family aims to meet the needs of a wide range of users. In fact, now is the perfect time to explore the possibilities with Qwen's top encoder model, the Qwen2.5-Coder-32B-Instruct, as well as its versatile family of smaller encoders. Let's welcome this new era of open source coding language models that continue to push the boundaries of innovation and accessibility.
look at the Paper, Models hugging faces, Manifestation, and Details. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Next LinkedIn Live Event) 'One Platform, Multimodal Possibilities,' where Encord CEO Eric Landau and Head of Product Engineering Justin Sharps will talk about how they are reinventing the data development process to help teams quickly build data models. Innovative multimodal ai.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}