
Language models have demonstrated remarkable capabilities in processing various types of data, including multilingual text, code, mathematical expressions, images, and audio. However, a fundamental question arises: how do these models effectively handle such heterogeneous inputs using a single set of parameters? While one approach suggests developing specialized subspaces for each type of data, this overlooks the inherent semantic connections that exist between seemingly different forms of data. For example, equivalent sentences in different languages, image-title pairs, or code snippets with natural language descriptions share conceptual similarities. Like the cross-modal semantic center of the human brain that integrates information from various sensory inputs, there is an opportunity to develop models that can project different types of data into a unified representation space, perform calculations, and generate appropriate results. The challenge lies in creating an architecture that can effectively utilize these structural commonalities while maintaining the unique characteristics of each data type.
Previous attempts to address cross-data type representation have primarily focused on aligning single-data type models trained separately using transformation techniques. Research has demonstrated success in aligning word embeddings in different languages using mapping methods, and similar approaches have been applied to connect visual and textual representations from different models. Some studies have explored minimal tuning of language-only models to handle multimodal tasks. Additional research has investigated the evolution of representation through transformative layers, examining its impact on reasoning, factuality, and knowledge processing. Studies of layer pruning and early exit have also provided insight into representation dynamics. However, these approaches typically require separate models or transformations between representations, limiting their efficiency and potentially missing deeper connections between different types of data. Furthermore, the need for explicit alignment mechanisms adds complexity and computational overhead to systems.
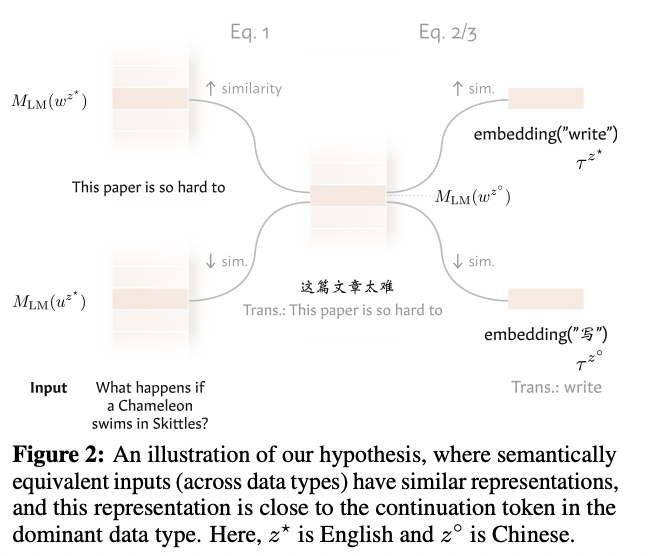
Researchers from MIT, the University of Southern California, and the Allen Institute for ai propose a robust approach to understanding how language models process multiple types of data across a shared representation space. The methodology focuses on investigating the existence of a “semantic center”: a unified representation space structured by the dominant data type of the model, typically English. This approach examines three key aspects: first, it analyzes how semantically similar inputs from different data types (languages, arithmetic expressions, code, and multimodal inputs) are grouped into intermediate layers of the model; second, investigate how these hidden representations can be interpreted through the dominant language of the model using the logit lens technique; and third, conduct intervention experiments to demonstrate that this shared representation space actively influences model behavior rather than being a passive byproduct of training. Unlike previous approaches that focused on aligning separately trained models, this methodology examines how a single model naturally develops and uses a unified representation space without requiring explicit alignment mechanisms.
The semantic center hypothesis testing framework employs a sophisticated mathematical architecture built on domain-specific functions and representation spaces. For any data type z in the set Z supported by the model, the framework defines a domain Xz (such as Chinese tokens for language or RGB values for images) and two crucial functions: Mz, which maps input sequences to a space of semantic representation Sz, and Vz, which transforms these representations back to the original data type format. The testing methodology evaluates two fundamental equations: first, it compares the similarity between semantically related inputs of different data types using hidden state cosine similarity measures, and second, it examines the relationship between these representations and the dominant language of the model through the logit lens technique. This technique analyzes hidden states in intermediate layers by applying the output token embedding matrix, producing probability distributions that reveal the internal processing of the model. The architecture has been rigorously tested on multiple data types, including various languages, arithmetic expressions, code, semantic structures, and multimodal input, consistently demonstrating the existence of a unified semantic representation space.
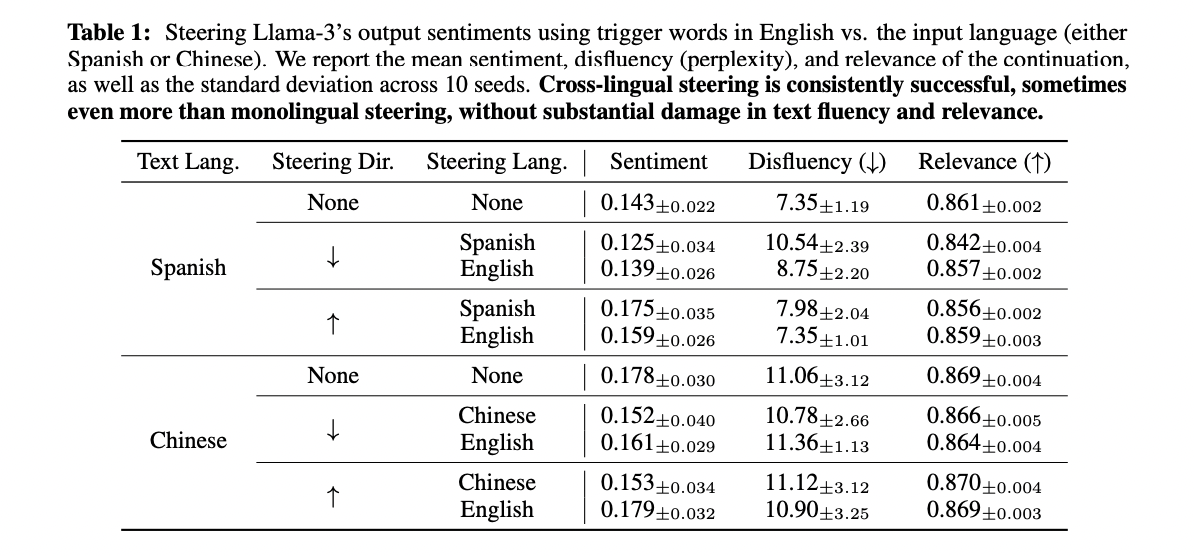
The research presents compelling results from intervention experiments that validate the causal impact of the semantic center on model behavior. In multilingual experiments using the Additive Activation technique, interventions in the English representation space effectively drove model results even when processing Spanish and Chinese texts. By testing 1,000 prefixes from both the InterTASS dataset (Spanish) and the multilingual corpus of amazon reviews (Chinese), the study compared model results with and without interventions using language-specific sentiment trigger words (Good/ Bad, Good/Bad, 好/坏). These experiments demonstrated that English-based interventions achieved sentiment-directing effects comparable to interventions using the native language of the text, while maintaining fluency and generational relevance. The researchers evaluated the quality of the generated text using three key metrics: sentiment alignment with the desired direction, fluidity of the generated text, and relevance to the original prefix. The results strongly support the hypothesis that the semantic center is not simply a byproduct of training, but actively influences the cross-linguistic processing capabilities of the model.
Research advances the understanding of how language models process various types of data through a unified semantic hub. The study conclusively demonstrates that models naturally develop a shared representation space where semantically related inputs are grouped together, regardless of their original modality. This discovery, validated in multiple models and data types, opens new possibilities for the interpretation and control of models through specific interventions in the dominant linguistic space.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(ai Magazine/Report) Read our latest report on 'SMALL LANGUAGE MODELS'
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}