
This is the third article of the series, Agentic ai Design Patterns; here, we will talk about the Agentic ai Planning Pattern. Let’s refresh what we have learned in the two articles – We have studied how agents can reflect and use tools to access information. In the Reflection pattern, we have seen the ai agents using the iterative process of generation and self-assessment to improve the output quality. Next, the Tool use pattern is a crucial mechanism that enables ai to interact with external systems, APIs, or resources beyond its internal capabilities.
You can find both the articles here:
Also, here are the 4 Agentic ai Design Patterns: Top 4 Agentic ai Design Patterns for Architecting ai Systems.
Now, talking about the Planning Pattern. Let’s take an example of a smart assistant who doesn’t only reflect and pull in outside information when needed but also decides the sequence of steps to solve a bigger problem. Pretty cool, right? But here’s where it gets really interesting: how does this assistant decide on the best sequence of steps to accomplish big, multi-layered goals? Effective planning is determining a structured sequence of actions to complete complex, multi-step objectives.
What does a planning pattern provide?
Planning Patterns provide strategies for language models to divide large tasks into manageable subgoals, enabling them to tackle intricate challenges step-by-step while keeping the overarching goal in focus. This article will discuss the Planning pattern in detail with the ReAct and ReWOO techniques.
<h2 class="wp-block-heading" id="h-agentic-ai-planning-pattern-an-overview”>Agentic ai Planning Pattern: An Overview
The Agentic ai Planning Pattern is a framework that focuses on breaking down a larger problem into smaller tasks, managing those tasks effectively, and ensuring continuous improvement or adaptation based on task outcomes. The process is iterative and relies on a structured flow to ensure that the ai system can adjust its plan as needed, moving closer to the desired goal with each iteration.
The Planning Pattern has the following main components:
- Planning
- Generate Task
- Single Task Agent
- The Single Task Agent is responsible for completing each task generated in the previous step.
- This agent executes each task using predefined methods like ReAct (reflect-then-act) or ReWOo (rework-oriented operations).
- Once a task is completed, the agent returns a Task Result, which is sent back to the planning loop.
- Replan
- The Replan stage evaluates the Task Result to determine if any adjustments are needed.
- If the task execution does not fully meet the desired outcome, the system will replan and possibly modify the tasks or strategies.
- This feedback loop allows the ai system to learn and improve its approach iteratively, making it more adaptable to changing requirements or unexpected outcomes.
- Iterate:
- This part of the pattern is a loop connecting Generate Task and Replan.
- It signifies the iterative nature of the process, where the ai system continuously re-evaluates and adjusts its approach until it achieves satisfactory results.
The Agentic ai Planning Pattern leverages a structured loop of planning, task generation, execution, and replanning to ensure that ai systems can autonomously work towards complex goals. This pattern supports adaptability by allowing the ai to modify its approach in response to task outcomes, making it robust and responsive to dynamic environments or changing objectives.
<h2 class="wp-block-heading" id="h-example-of-an-agentic-ai-planning-pattern”>Example of an Agentic ai Planning Pattern
The above-given illustration depicts a sequential image understanding process, with steps that align with the agentic ai planning pattern. In agentic ai, an “agent” takes actions based on observations and planned responses to achieve a specific goal. Here’s how each step in the image fits into the agentic ai framework:
1. Goal Setting (Understanding the Task)
- Prompt: The task begins with a question: “Can you describe this picture and count how many objects are in the picture?”
- Agentic ai Element: The ai agent interprets this goal as a directive to analyze the image for both object recognition and description. The goal is to answer the question comprehensively by identifying, counting, and describing objects.
2. Planning and Subgoal Formation
- Process Breakdown:
- To accomplish this goal, the agent breaks the task down into specific subtasks:
- Object Detection (identify and localize objects)
- Classification (identify what each object is)
- Caption Generation (generate a natural language description of the scene)
- To accomplish this goal, the agent breaks the task down into specific subtasks:
- Agentic ai Element: An agent plans its actions by setting intermediate subgoals in the agentic ai planning pattern. Here, detecting objects is a subgoal required to complete the ultimate objective (generating a descriptive caption that includes a count of objects).
3. Perception and Action (Detecting and Describing)
- Tools and Models Used:
- The agent utilises the facebook/detr-resnet-101 model for detection, which identifies and locates objects (e.g., giraffes and zebras) and assigns confidence scores.
- After detection, the agent uses nlpconnect/vit-gpt2-image-captioning to generate a descriptive caption.
- Agentic ai Element: The agent “perceives” its environment (the image) using specific perception modules (pre-trained models) that allow it to gather necessary information. In agentic ai, perception is an active, goal-oriented process. Here, the models act as perception tools, processing visual information to achieve the overall objective.
4. Evaluation and Iteration (Combining Results)
- Processing and Aggregating Information: The results from detection (bounding boxes and object types) and captioning (descriptive text) are combined. The agent evaluates its outputs, confirming both object detection confidence levels and the coherence of the description.
- Agentic ai Element: Agentic ai involves continuously evaluating and adjusting responses based on feedback and information aggregation. The agent reviews its predictions (detection scores and bounding boxes) to ensure they align with the task’s demands.
5. Goal Achievement (Answer Presentation)
- Output Presentation: The agent finally provides an answer that includes a count of detected objects, a list of identified objects with confidence scores, and a descriptive caption.
- Agentic ai Element: The agent completes the goal by synthesising its perception and planning outcomes into a coherent response. In agentic ai, this step is about achieving the task’s overarching goal and generating an output that addresses the user’s initial question.
<h2 class="wp-block-heading" id="h-task-decomposition-for-agentic-ai-planning”>Task Decomposition for Agentic ai Planning
There are two different approaches to task decomposition for agentic ai planning, specifically designed for handling complex tasks in dynamic and variable real-world environments. Given the limitations of attempting a single-step plan for complex objectives, decomposition into manageable parts becomes essential. This process, akin to the “divide and conquer” strategy, involves breaking down a complex goal into smaller, more achievable sub-goals.
Here’s an explanation of each approach:
(a) Decomposition-First Approach
- Decompose Step: In this method, the LLM Agent begins by fully decomposing the main goal into sub-goals (Sub Goal-1, Sub Goal-2, …, Sub Goal-n) before initiating sub-tasks. This step is indicated by 1 in the diagram.
- Sub-Plan Step: After decomposing the task, the agent creates sub-plans for each sub-goal independently. These sub-plans define the specific actions needed to achieve each sub-goal. This planning process is marked as 2 in the image.
- Sequential Execution: Each sub-plan is executed one after the other in sequence, completing each sub-goal in order until the main goal is accomplished.
In essence, the decomposition-first method separates the stages of decomposition and execution: it completes all planning for the sub-goals before any execution begins. This approach can be effective in stable environments where changes are minimal during the planning process.
(b) Interleaved Approach
The interleaved approach, decomposition and execution occur in a more intertwined manner:
- Simultaneous Planning and Execution: Instead of fully decomposing the task before taking action, the LLM Agent begins with a partial decomposition (e.g., starting with Sub Goal-1) and immediately starts planning and executing actions related to this sub-goal.
- Adaptive Decomposition: As each sub-goal is worked on, new sub-goals might be identified and planned for, adapting as the agent progresses. The agent continues decomposing, planning, and executing in cycles, allowing flexibility to respond to changes or unexpected environmental complexities.
- Dynamic Execution: This method is more adaptive and responsive to changing environments, as planning and execution are interleaved. This allows the agent to adjust to real-time feedback, modifying sub-goals or actions as necessary.
In a nutshell,
- Decomposition-First: A structured, step-by-step approach where all sub-goals are planned before any execution. Suitable for stable environments where the task is well-defined and unlikely to change during execution.
- Interleaved: A flexible, adaptive method where planning and execution happen concurrently. This approach is ideal for dynamic environments where real-time feedback and adjustments are essential.
In complex ai planning, choosing between these approaches depends on the environment and the task’s variability. The decomposition-first approach emphasises structure and pre-planning, while the interleaved method prioritises adaptability and real-time responsiveness.
Both approaches have their own strengths, but they also bring unique challenges when faced with highly dynamic and unpredictable scenarios. To navigate such complexity, an emerging framework known as ReAct (Reasoning and Acting) has become increasingly popular in ai research. ReAct synthesizes reasoning and acting in a way that enables agents to think critically about their actions, adjusting their strategies based on immediate feedback. This framework, which blends structured planning with real-time adjustments, allows agents to make more sophisticated decisions and handle variability in diverse environments.
What is ReAct?
As we already know, LLMs showcase impressive capabilities in providing language understanding and decision-making. However, their ability to reason and act has been studied as separate topics. This section will discuss how LLMs can use reasoning and action planning to handle complex tasks with greater synergy with the ReAct approach. Here’s the evolution and significance of the ReAct (Reason + Act) framework in language model (LM) systems. It contrasts traditional approaches (reasoning-only and action-only models) with ReAct, which combines reasoning and acting capabilities. Let’s break down each part of the ReAct architecture to understand what it conveys.
Workflow of ReAct
1. Reason Only
- This model focuses solely on reasoning and thought processing within the language model. An example of this approach is Chain-of-Thought (CoT) prompting, where the language model goes through logical steps to solve a problem but does not interact directly with the environment.
- In this reasoning-only mode, the model generates a sequence of thoughts or “reasoning traces” but is unable to take action or receive feedback from an external environment. It’s limited to internal contemplation without engagement.
- Limitation: Since it only reasons, this model can’t adapt its behaviour based on real-time feedback or interact with external systems, making it less dynamic for tasks that require interaction.
2. Act Only
- This model is designed purely for acting in an environment. Examples include systems like WebGPT and SayCan, which can perform actions (e.g., making web searches and controlling robots) based on prompts.
- Here, the language model acts in an external environment (Env), takes actions, and observes the results of these actions. However, it doesn’t have a reasoning trace to guide its actions logically; it relies more on straightforward action-response without deeper planning.
- Limitation: Without reasoning, this approach lacks the capacity for complex, multi-step problem-solving. The actions may be reactive but need more strategic thought that could improve long-term effectiveness.
3. ReAct
- The ReAct framework combines Reasoning and Acting within a single loop. Here, the language model alternates between Reasoning Traces and Actions in the environment.
- Process:
- The model first reasons about the task, creating a “thought” or hypothesis about what should be done next.
- It then takes an action in the environment based on its reasoning.
- After performing the action, the model observes the outcome in the environment, which it incorporates into its next reasoning step.
- This cycle of reasoning, acting, and observing continues iteratively, allowing the model to learn and adapt based on real-time feedback from the environment.
- Significance: By integrating reasoning and acting, ReAct allows the model to break down complex, multi-step tasks into manageable steps, adjust based on outcomes, and work towards solutions that require both planning and interaction. This combination makes ReAct well-suited for dynamic, multi-step tasks where the model must continuously adapt and refine its approach.
Why ReAct Is Powerful?
- The ReAct framework answers the question posed at the bottom of the diagram: What if we combine reasoning and acting?
- By integrating these two capabilities, ReAct enables the model to think and act in a coordinated manner. This enhances its ability to:
- Solve complex problems.
- Adjust actions based on feedback.
- Operate effectively in environments where sequential decision-making is required.
In essence, ReAct provides a more holistic approach to task completion by combining internal reasoning with external action-taking, making it more flexible and effective in real-world applications where purely reasoning or acting models fall short.
Also, here is the comparison of 4 prompting methods: (a) Standard, (b) Chain-of-thought (CoT, Reason Only), (c) Act-only, and (d) ReAct (Reason+Act), solving a HotpotQA (Yang et al., 2018) question. (2) Comparison of (a) Act-only and (b) ReAct prompting to solve an AlfWorld (Shridhar et al., 2020b) game.
The ReACT (Reason + Act) approach outperforms the others by leveraging reasoning and actions in tandem. This allows the ai to adapt to dynamic environments and complex questions. This framework leads to more sophisticated and accurate outcomes, making it highly suitable for tasks that require both thought and interaction.
Also read: Implementation of ReAct Agent using LlamaIndex and Gemini
Planning Pattern Using OpenAI API and httpx Library
This section aims to outline the process of building an ai agent that leverages the OpenAI API and the httpx library. It introduces the basic structure of creating a chatbot class capable of handling user inputs and executing responses through OpenAI’s language model. The section explains implementing the ReAct pattern to enable a loop of thought, action, pause, and observation. It describes registering custom actions (e.g., Wikipedia search, calculation, blog search) for enhanced functionality. This facilitates dynamic interaction where the agent can use external actions to refine and complete its answers. Let’s get straight to the Basic Structure of building ai Agent:
This code defines a ChatBot class for interacting with OpenAI’s GPT model. It initialises with an optional system prompt, stores conversation history, processes user input, and retrieves responses from the model using OpenAI’s API, simulating conversational capabilities for various applications or chatbot functionalities.
import openai
import re
import httpx
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = ()
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=self.messages)
return completion.choices(0).message.contentHere’s how you can implement the ReAct Pattern:
The code outlines a structured process for answering questions using a loop of Thought, Action, PAUSE, and Observation. It defines how an ai agent should think through a question, take appropriate actions (calculations or information searches), pause for results, observe outcomes, and ultimately provide an answer.
prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer.
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point
syntax if necessary
wikipedia:
e.g. wikipedia: Django
Returns a summary from searching Wikipedia
simon_blog_search:
e.g. simon_blog_search: Django
Search Simon's blog for that term
Example session:
Question: What is the capital of France?
Thought: I should look up France on Wikipedia
Action: wikipedia: France
PAUSE
You will be called again with this:
Observation: France is a country. The capital is Paris.
You then output:
Answer: The capital of France is Paris
""".strip()After implementation of the ReAct Pattern, we will implement the actions:
- Action: Wikipedia Search,
- Action: Blog Search,
- Action: Calculation.
<h4 class="wp-block-heading" id="h-adding-actions-to-the-ai-agent”>Adding Actions to the ai Agent
Next, we need to register these actions in a dictionary so the ai agent can use them:
known_actions = {
"wikipedia": wikipedia,
"calculate": calculate,
"simon_blog_search": simon_blog_search
}Here’s how you can complete the integration
This code defines a function or query that simulates a chatbot interaction with a user-specified question. It iteratively processes responses up to a maximum number of turns, extracting and executing specific actions using known handlers and updating prompts based on observations until a final result is returned or printed.
def query(question, max_turns=5):
i = 0
bot = ChatBot(prompt)
next_prompt = question
while i < max_turns:
i += 1
result = bot(next_prompt)
print(result)
actions = (action_re.match(a) for a in result.split('\n') if action_re.match(a))
if actions:
action, action_input = actions(0).groups()
if action not in known_actions:
raise Exception(f"Unknown action: {action}: {action_input}")
print(" -- running {} {}".format(action, action_input))
observation = known_actions(action)(action_input)
print("Observation:", observation)
next_prompt = f"Observation: {observation}"
else:
return result
print(query("What does England share borders with?"))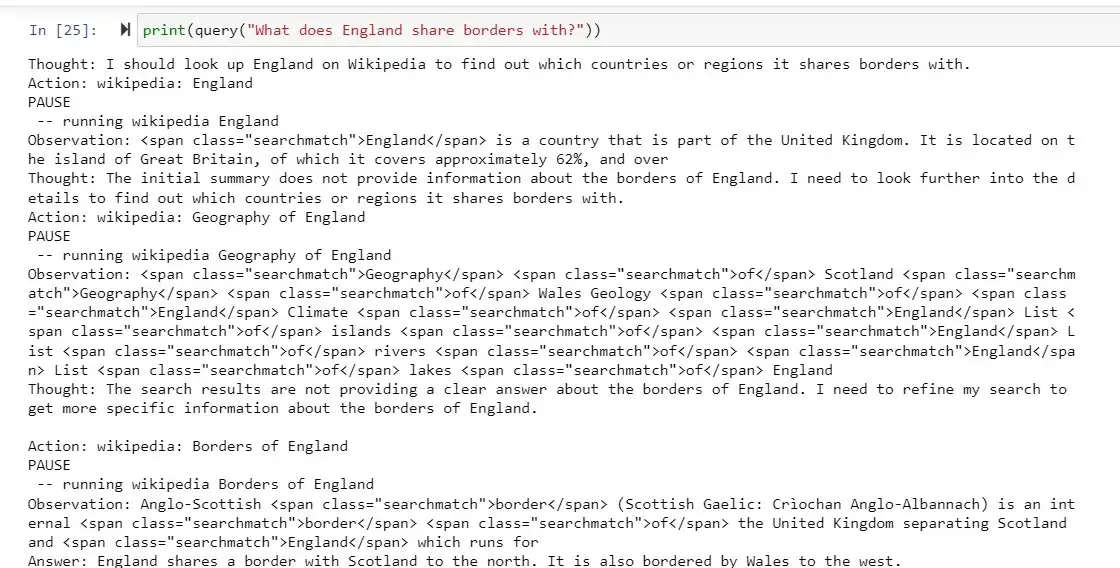
For full code implementation, refer to this article: Comprehensive Guide to Build ai Agents from Scratch.
Let’s see the implementation of the Planning Pattern using ReAct with LangChain:
Planning Pattern using ReAct with LangChain
The objective is to implement a tool-augmented ai agent using LangChain and OpenAI’s GPT models that can autonomously conduct research and answer complex questions by integrating custom tools like web search through the Tavily API. This agent is designed to simulate human-like problem-solving by executing a planning pattern called ReAct (Reasoning and Action). It builds a loop of reasoning and action steps, evaluates responses, and makes decisions to gather and analyze information effectively. The setup supports real-time data queries and structured decision-making, enabling enhanced responses to questions like “What are the names of Ballon d’Or winners since its inception?”
Install OpenAI and LangChain Dependencies
!pip install langchain==0.2.0
!pip install langchain-openai==0.1.7
!pip install langchain-community==0.2.0<h3 class="wp-block-heading" id="h-enter-open-ai-api-key”>Enter Open ai API Key
from getpass import getpass
OPENAI_KEY = getpass('Enter Open ai API Key: ')Struggling with finding the OpenAI API key? Check out this article – How to Generate Your Own OpenAI API Key and Add Credits?
Enter Tavily Search API Key
Get a free API key from here
TAVILY_API_KEY = getpass('Enter Tavily Search API Key: ')Setup Environment Variables
import os
os.environ('OPENAI_API_KEY') = OPENAI_KEY
os.environ('TAVILY_API_KEY') = TAVILY_API_KEYCreate Tools
Here, we create custom tools which are wrappers on top of the Tavily API.
Simple Web Search tool
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
import requests
import json
tv_search = TavilySearchResults(max_results=3, search_depth="advanced",
max_tokens=10000)
@tool
def search_web(query: str) -> list:
"""Search the web for a query."""
tavily_tool = TavilySearchResults(max_results=2)
results = tavily_tool.invoke(query)
return resultsTest Tool Calling with LLM
from langchain_openai import ChatOpenAI
chatgpt = ChatOpenAI(model="gpt-4o", temperature=0)
tools = (search_web)
chatgpt_with_tools = chatgpt.bind_tools(tools)
prompt = "What are the names of Ballon d'Or winners since its inception?"
response = chatgpt_with_tools.invoke(prompt)
response.tool_callsOutput
({'name': 'search_web',
'args': {'query': "list of Ballon d'Or winners"},
'id': 'call_FW0h6OpObqVQAIJnOtGLJAXe',
'type': 'tool_call'})
<h3 class="wp-block-heading" id="h-build-and-test-ai-agent”>Build and Test ai Agent
Now that we have defined the tools and the LLM, we can create the agent. We will use a tool-calling agent to bind the tools to the agent with a prompt. We will also add the capability to store historical conversations as memory.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
SYS_PROMPT = """You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop, you output an Answer.
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
wikipedia:
e.g. wikipedia: Ballon d'Or
Returns a summary from searching Wikipedia.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of (Wikipedia, duckduckgo_search, Calculator)
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
"""
prompt_template = ChatPromptTemplate.from_messages(
(
("system", SYS_PROMPT),
MessagesPlaceholder(variable_name="history", optional=True),
("human", "{query}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
)
)
prompt_template.messagesOutput

Now, we can initiate the agent with the LLM, the prompt, and the tools. The agent is responsible for taking in input and deciding what actions to take. REMEMBER the Agent does not execute those actions – that the AgentExecutor does
Note that we are passing in the model chatgpt, not chatgpt_with_tools.
That is because create_tool_calling_agent will call .bind_tools for us under the hood. This should ideally be used with an LLM which supports tool \ function calling.
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(chatgpt, tools, prompt_template)
agent
Finally, we combine the agent (the brains) with the tools inside the AgentExecutor (which will repeatedly call the agent and execute tools).
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose = True)
agent_executor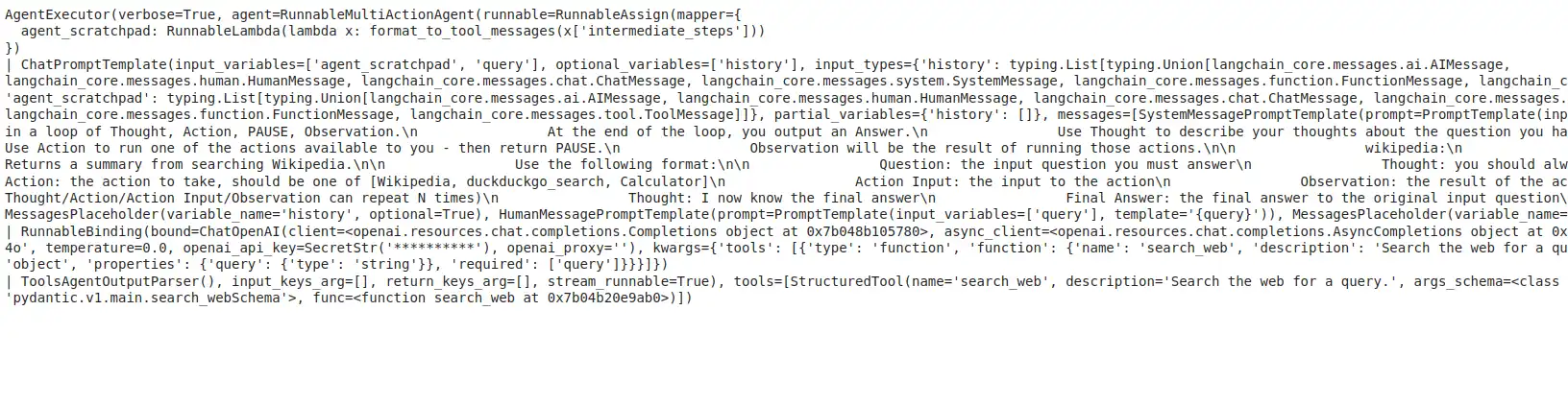
query = """Tell me the Ballon d'Or winners since it started?
"""
response = agent_executor.invoke({"query": query})
from IPython.display import display, Markdown
display(Markdown(response('output')))
Also read: Comprehensive Guide to Build ai Agents from Scratch
If you want to dig deep into Generative ai then explore: GenAI Pinnacle Program!
Workflow of ReWOO (Reasoning Without Observation)
ReWOO (Reasoning without Observation) is a new agent architecture proposed by Xu et al. that emphasises an efficient approach to multi-step planning and variable substitution in large language model (LLM) systems. It addresses some of the limitations in ReAct-style agent architectures, particularly around execution efficiency and model fine-tuning. Here’s a breakdown of how ReWOO improves over traditional approaches:
How ReWOO Works?
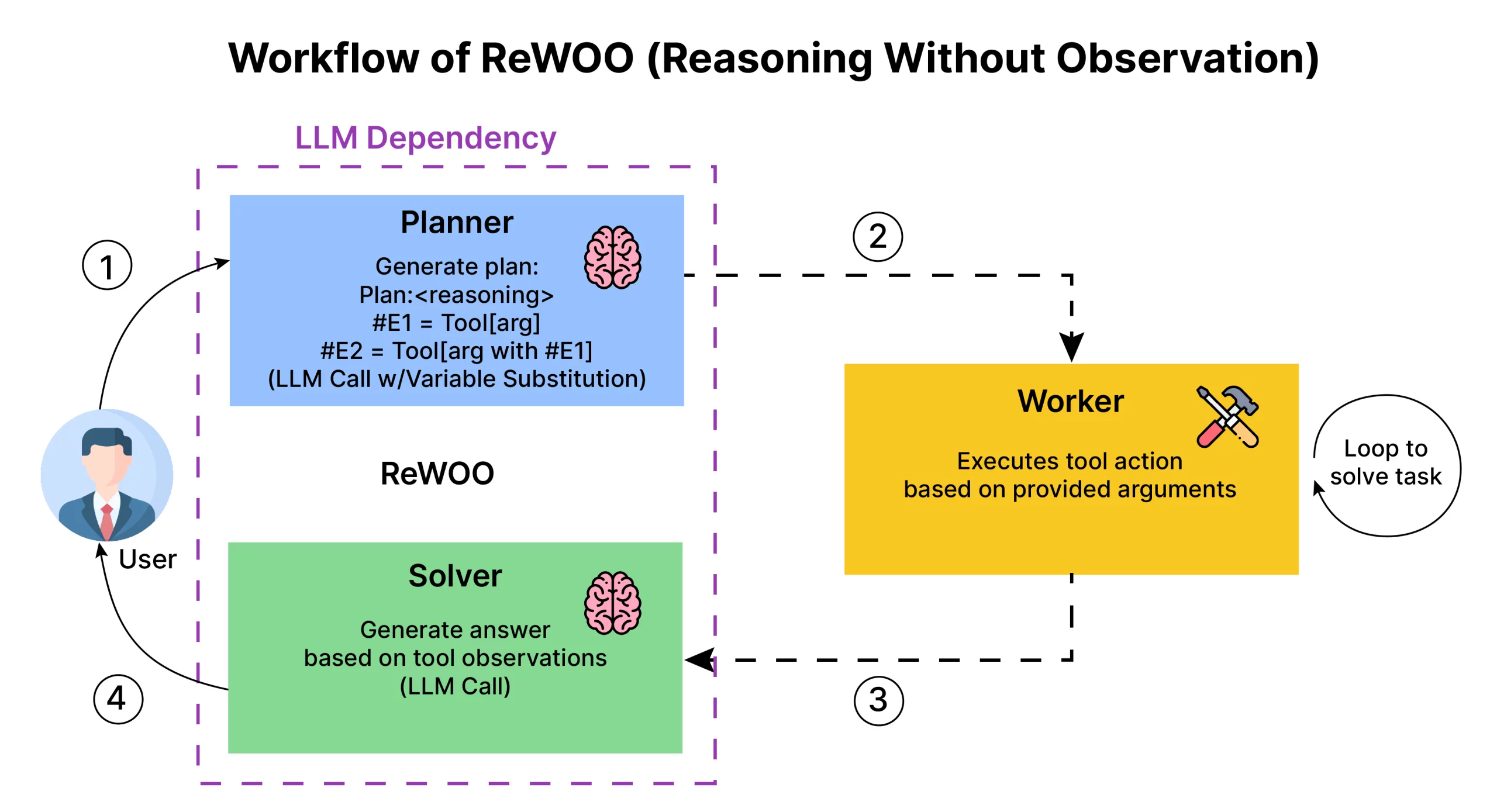
Here’s the workflow of the ai.github.io/langgraph/tutorials/rewoo/rewoo/” target=”_blank” rel=”noreferrer noopener nofollow”>ReWOO (Reasoning Without Observation) agent model. This model is designed to improve efficiency in multi-step reasoning and tool usage by minimizing redundant observations and focusing on planned sequences of actions. Here’s a step-by-step explanation of each component and the flow of information:
Components of ReWOO
- Planner:
- The Planner is responsible for creating an entire plan at the beginning. It determines the sequence of actions or steps needed to solve the task.
- For each action step, the Planner specifies:
- Tool: The specific tool or function required for the step.
- Arguments (args): The input values or variables needed for the tool.
- The plan is defined using variable substitution, where the output of one tool (e.g., #E1) can be used as an argument in another tool (e.g., #E2), creating dependencies across steps.
- Importantly, this planning process occurs in a single LLM call, making it more efficient by reducing token consumption than iterative, observation-based reasoning.
- Worker:
- The Worker is responsible for executing the actions per the plan the Planner generated.
- The Worker takes the arguments provided for each step, invokes the specified tool, and returns the result.
- This execution can be looped until the task is solved, ensuring each tool action is completed in the correct order as outlined in the plan.
- The Worker functions independently of the LLM, meaning it simply follows the Planner’s instructions without additional calls to the LLM at each step.
- Solver:
- The Solver is the final component that interprets the results of the tools used by the Worker.
- Based on the observations gathered from tool executions, the Solver generates the final answer to the user’s query or task.
- This part may involve a final LLM call to synthesize the information into a coherent response.
Key Enhancements of ReWOO
Here are the key enhancements of ReWOO:
- Efficient Tool Use and Reduced Token Consumption:
- Single-Pass Tool Generation: Unlike ReAct-style agents, which require multiple LLM calls for each reasoning step (and therefore repeat the entire system prompt and previous steps for each call), ReWOO generates the full sequence of required tools in one pass.
- This approach drastically reduces token consumption and cuts down execution time, making it more suitable for complex tasks that involve multiple steps or tools.
- Streamlined Fine-Tuning Process:
- Decoupled Planning from Tool Outputs: Since ReWOO’s planning data is not dependent on the actual outputs of tools, it allows for a more straightforward fine-tuning process.
- Fine-Tuning Without Tool Execution: In theory, the model can be fine-tuned without invoking any tools, as it relies on planned actions and substitutions rather than actual tool responses.
Workflow Process
The process flows through the following steps:
- Step 1 – User Input:
- The user submits a question or task to ReWOO.
- The input is passed to the Planner to initiate the planning phase.
- Step 2 – Planner Creates Plan:
- The Planner formulates a multi-step plan, specifying which tools to use and the required arguments.
- The plan may involve variable substitution, where outputs from one tool are used as inputs for another.
- The Planner then provides this complete plan to the Worker.
- Step 3 – Worker Executes Actions:
- The Worker carries out each step of the plan by calling the specified tools with the appropriate arguments.
- This looped process ensures each tool action is completed sequentially until the task is finished.
- Step 4 – Solver Generates Answer:
- Once all necessary actions are executed, the Solver interprets the results and generates the final answer for the user.
- This answer is then returned to the user, completing the workflow.
In essence, ReWOO enhances the agent’s efficiency by separating the reasoning (Planner) and execution (Worker) phases, thereby creating a faster and more resource-efficient framework for complex tasks.
Comparison of Reasoning with Observation and ReWOO
Two distinct methods for task reasoning in a system involving large language models (LLMs) are (a) Reasoning with Observation and (b) ReWOO (Reasoning with Observations and Organized Evidence). Here’s a comparison based on the given diagram:
1. Observation-Dependent Reasoning (Left Panel)
- Setup and Process Flow:
- The task from the user is first enhanced with context and exemplars (examples or prompts to aid the LLM’s reasoning) and is then inputted into the LLM to begin the reasoning process.
- The LLM generates two key outputs:
- T (Thought): Represents the internal thought or understanding derived from the LLM’s initial processing.
- A (Action): This is the action the LLM decides to take based on its thought, typically involving querying tools for information.
- After each action, the observation (O) from the tools is received. This observation acts as a feedback loop and is appended to the prompt history, forming an updated input for the next LLM call.
- Iterative Nature:
- This setup is iterative, meaning the LLM repeatedly cycles through thoughts, actions, and observations until sufficient reasoning is achieved.
- Each cycle relies on the continuous stacking of observations in the prompt history, creating prompt redundancy as more information is accumulated over time.
- Limitation:
- This approach can lead to prompt redundancy and possible inefficiencies due to the repetitive input of context and exemplars with each cycle, as the same data (context and exemplars) is repeatedly fed back into the system.
2. ReWOO (Right Panel)
- Enhanced Structure:
- Unlike the observation-dependent reasoning setup, ReWOO introduces a more structured approach by separating roles:
- Planner: Responsible for creating a sequence of interdependent plans (P).
- Worker: Fetches evidence (E) from various tools according to the Planner’s instructions.
- The Planner generates plans that are then passed to the Worker. The Worker executes these plans by gathering the necessary evidence through tool interactions.
- Unlike the observation-dependent reasoning setup, ReWOO introduces a more structured approach by separating roles:
- Role of Plans and Evidence:
- Plans (P): These are predefined, interdependent steps outlining the system’s reasoning path.
- Evidence (E): This is the specific information or data retrieved based on the Planner’s instructions.
- The combination of plans (P) and evidence (E) forms a more organized input, which, alongside the original task and context, is finally processed by a Solver LLM to produce the user’s output.
- Solver:
- The Solver serves as the final reasoning module, integrating the task, context, plans, and evidence to generate a coherent answer.
- Since the context and exemplars are not repeatedly fed into the LLM, ReWOO reduces the issue of prompt redundancy.
Key Differences and Advantages of ReWOO
- Prompt Efficiency:
- Observation-dependent reasoning suffers from prompt redundancy due to repeated cycles of the same context and exemplars, potentially overloading the prompt and increasing processing time.
- ReWOO, on the other hand, avoids this redundancy by separating the planning and evidence-gathering stages, making the prompt more efficient.
- Structured Task Execution:
- ReWOO’s design introduces a Planner and Worker, allowing for a clear distinction between task planning and evidence collection. This structured flow ensures that each step is executed logically, making it easier to manage complex tasks.
- Scalability:
- With its modular setup, ReWOO can effectively handle more complex tasks. Its structured approach to planning and evidence retrieval allows it to scale better with complex reasoning tasks, as each component (Planner, Worker, Solver) has a defined role.
Summary
- Observation-Dependent Reasoning: Cycles through thoughts, actions, and observations, creating prompt redundancy but maintaining simplicity.
- ReWOO: Uses a more organized structure by employing a Planner, Worker, and Solver to streamline reasoning, reduce prompt redundancy, and improve efficiency in handling complex tasks.
Code Implementation of ReWoo
For the Hands-on ReWoo, I am referring to ai/langgraph/blob/main/docs/docs/tutorials/rewoo/rewoo.ipynb”>the ReWOO recipe from Vadym Barda using LangGraph. For now, I am not mentioning the libraries and other requirements, but I will dig into defining the graph state, planner, executor, and solver.
In LangGraph, each node updates a shared graph state, which serves as input whenever a node is activated. Below, the state dictionary is defined to contain essential task details, such as task, plan, steps, and other necessary variables.
from typing import List
from typing_extensions import TypedDict
class ReWOO(TypedDict):
task: str
plan_string: str
steps: List
results: dict
result: strPlanner: Generating Task Plans
The planner module uses a language model to generate a structured plan in the form of a task list. Each task in the plan is represented by strings that can include special variables (like #E{0-9}+) for substituting values from previous results. In this example, the agent has access to two tools:
- Google: It acts as a search engine, and it is represented here by Tavily.
- LLM: A large language model tool to interpret and analyze data, providing reasoning from previous outputs efficiently.
The prompt instructs the model on how to create a plan, specifying which tools to use and how to reference prior results using variables.
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
prompt = """For the following task, make plans that can solve the problem step by step. For each plan, indicate \
which external tool together with tool input to retrieve evidence. You can store the evidence into a \
variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...)
# Task Example
task = "what is the exact hometown of the 2024 mens australian open winner"
result = model.invoke(prompt.format(task=task))
print(result.content)Output
Plan: Use Google to search for the 2024 Australian Open winner.#E1 = Google(2024 Australian Open winner)
Plan: Retrieve the name of the 2024 Australian Open winner from the search results.
#E2 = LLM(What is the name of the 2024 Australian Open winner, given #E1)
...
Planner Node
The planner node connects to the graph, creating a get_plan node that receives the ReWOO state and updates it with new steps and plan_string.
import re
from langchain_core.prompts import ChatPromptTemplate
regex_pattern = r"Plan:\s*(.+)\s*(#E\d+)\s*=\s*(\w+)\s*\(((^\))+)\)"
prompt_template = ChatPromptTemplate.from_messages((("user", prompt)))
planner = prompt_template | model
def get_plan(state: ReWOO):
task = state("task")
result = planner.invoke({"task": task})
matches = re.findall(regex_pattern, result.content)
return {"steps": matches, "plan_string": result.content}Executor: Executing Planned Tasks
The executor iterates through each planned task, executing specified tools sequentially. It uses helper functions to determine the current task and performs variable substitution before each tool call.
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()
def _get_current_task(state: ReWOO):
if "results" not in state or state("results") is None:
return 1
if len(state("results")) == len(state("steps")):
return None
else:
return len(state("results")) + 1
def tool_execution(state: ReWOO):
_step = _get_current_task(state)
_, step_name, tool, tool_input = state("steps")(_step - 1)
_results = (state("results") or {}) if "results" in state else {}
for k, v in _results.items():
tool_input = tool_input.replace(k, v)
if tool == "Google":
result = search.invoke(tool_input)
elif tool == "LLM":
result = model.invoke(tool_input)
else:
raise ValueError
_results(step_name) = str(result)
return {"results": _results}Solver: Synthesizing Final Output
The solver aggregates results from each executed tool and generates a conclusive answer based on the evidence collected.
solve_prompt = """Solve the following task or problem. To solve the problem, we have made step-by-step Plan and \
retrieved corresponding Evidence to each Plan. Use them with caution since long evidence might \
contain irrelevant information.
{plan}
Now solve the question or task according to provided Evidence above. Respond with the answer
directly with no extra words.
Task: {task}
Response:"""
def solve(state: ReWOO):
plan = ""
for _plan, step_name, tool, tool_input in state("steps"):
_results = (state("results") or {}) if "results" in state else {}
for k, v in _results.items():
tool_input = tool_input.replace(k, v)
step_name = step_name.replace(k, v)
plan += f"Plan: {_plan}\n{step_name} = {tool}({tool_input})"
prompt = solve_prompt.format(plan=plan, task=state("task"))
result = model.invoke(prompt)
return {"result": result.content}Defining the Graph Workflow
The graph is a directed workflow that coordinates interactions between the planner, tool executor, and solver nodes. Conditional edges ensure the process loops until all tasks are completed.
def _route(state):
_step = _get_current_task(state)
if _step is None:
return "solve"
else:
return "tool"
from langgraph.graph import END, StateGraph, START
graph = StateGraph(ReWOO)
graph.add_node("plan", get_plan)
graph.add_node("tool", tool_execution)
graph.add_node("solve", solve)
graph.add_edge("plan", "tool")
graph.add_edge("solve", END)
graph.add_conditional_edges("tool", _route)
graph.add_edge(START, "plan")
app = graph.compile()
# Stream output to visualize final results
for s in app.stream({"task": task}):
print(s)
print("---")
#Input: task = "what is the exact hometown of the 2024 mens australian open winner"
from IPython.display import Image, display
from langchain_core.runnables.graph import MermaidDrawMethod
display(
Image(
app.get_graph().draw_mermaid_png(
draw_method=MermaidDrawMethod.API,
)
)
)
print(s("solve")("result"))Output
San Candido, Italy
<h2 class="wp-block-heading" id="h-benefits-and-limitations-of-agentic-ai-planning-pattern”>Benefits and Limitations of Agentic ai Planning Pattern
The agentic ai planning pattern offers significant advantages, especially when a task’s complexity prevents predetermined step-by-step decomposition. Planning enables agents to dynamically decide their course of action, allowing for adaptive and context-aware problem-solving. It enhances flexibility and capability in handling unpredictable tasks, making it a powerful tool in situations demanding strategic foresight and decision-making.
However, this capability comes with notable limitations. The dynamic nature of planning introduces unpredictability, making it harder to foresee how an agent might behave in any given scenario. Unlike more deterministic agentic workflows, such as Reflection or Tool Use—which are reliable and effective—planning remains less mature and can yield inconsistent results. While current planning capabilities present challenges, the rapid advancements in ai research suggest that these limitations will likely diminish over time, leading to more robust and predictable planning functionalities.
Know more about it ai/the-batch/agentic-design-patterns-part-4-planning/” target=”_blank” rel=”noreferrer noopener nofollow”>here.
Also, to understand the Agent ai better, explore: The Agentic ai Pioneer Program
Conclusion
We explored the Agentic ai Planning Pattern, which is fundamental for structuring and executing complex, multi-step tasks in ai systems. This pattern enables ai to decompose large goals into smaller, manageable sub-goals, ensuring that the overall objective is approached methodically while remaining adaptable to real-time feedback and changes. We discussed two primary decomposition approaches: Decomposition-First, which emphasizes pre-planning for stable environments, and Interleaved, which allows for flexible execution and adaptive planning in dynamic settings. Additionally, we touched on the ReAct framework, showcasing how combining reasoning and acting can create a more interactive and iterative ai problem-solving approach. Lastly, we introduced ReWOO, an advanced architecture that enhances efficiency by minimizing redundant observations and focusing on planned sequences, thus optimizing task completion in complex environments.
These frameworks collectively highlight the power of integrating structured planning, iterative execution, and adaptive strategies for robust agentic ai systems capable of handling complex real-world challenges.
In our next article, we will be talking about the Multi-Agent Pattern!
If you’re interested in learning more about Agentic ai Planning Patterns, I recommend:
- MichaelisTrofficus: For building the Planning Pattern from Scratch
- ReAct: Synergizing Reasoning and Acting in Language Models
- ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
- Reasoning without Observation by ai/langgraph/blob/main/docs/docs/tutorials/rewoo/rewoo.ipynb” target=”_blank” rel=”noreferrer noopener nofollow”>vbarda
- ai/en/stable/examples/cookbooks/oreilly_course_cookbooks/Module-6/Agents/#with-react-agent” target=”_blank” rel=”noreferrer noopener nofollow”>LlamaIndex with With ReAct Agent
- “HuggingGPT: Solving ai Tasks with ChatGPT and its Friends in Hugging Face,” Shen et al. (2023)
- “Understanding the planning of LLM agents: A survey,” by Huang et al. (2024)
Frequently Asked Questions
Ans. An Agentic ai Planning Pattern refers to a structured approach or framework that ai systems use to make decisions and execute plans autonomously, aiming to achieve specific objectives while interacting with the environment.
Ans. These patterns are crucial for developing ai systems that can operate independently, adapt to new information, and efficiently solve complex problems without direct human input.
Ans. Unlike basic ai algorithms that may operate based on pre-programmed instructions, Agentic ai Planning Patterns allow for dynamic decision-making and long-term strategic planning, giving ai systems the ability to act with a degree of autonomy.
Ans. Key components typically include goal-setting mechanisms, decision-making algorithms, resource allocation strategies, and adaptive learning capabilities to update plans based on real-time data.
Ans. They are commonly applied in areas such as robotics, autonomous vehicles, strategic game-playing AIs, and complex simulation systems where independent problem-solving is required.

Hi, I am Pankaj Singh Negi – Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.





