
In this guide, I will walk you through the process of adding a custom evaluation metric to LLaMA-Factory. LLaMA-Factory is a versatile tool that allows users to tune large language models (LLMs) with ease, thanks to its easy-to-use web user interface and comprehensive set of scripts for training, deploying and evaluating models. A key feature of LLaMA-Factory is the LLaMA Board, an integrated dashboard that also displays evaluation metrics, providing valuable information on model performance. While standard metrics are available by default, the ability to add custom metrics allows us to evaluate models in ways that are directly relevant to our specific use cases.
We'll also cover the steps to create, integrate, and view a custom metric in LLaMA Board. By following this guide, you'll be able to monitor additional metrics tailored to your needs, whether you're interested in domain-specific accuracy, nuanced error types, or user-centric evaluations. This customization allows you to evaluate model performance more effectively, ensuring it aligns with the unique goals of your application. Let's dive in!
Learning outcomes
- Understand how to define and integrate a custom evaluation metric in LLaMA-Factory.
- Acquire practical skills to modify
metric.pyto include custom metrics. - Learn how to view custom metrics in LLaMA Board for enhanced model insights.
- Gain knowledge on how to adapt model evaluations to align with specific project needs.
- Explore ways to monitor specific domain model performance using custom metrics.
This article was published as part of the Data Science Blogathon.
What is LLaMA-Factory?
LLaMA-Factory, developed by hiyouga, is an open source project that allows users to fine-tune language models through an easy-to-use WebUI interface. It offers a complete set of tools and scripts for tuning, chatboting, serving and benchmarking LLM.
Designed with beginners and non-technical users in mind, LLaMA-Factory simplifies the process of fitting open source LLMs on custom data sets, eliminating the need to understand complex ai concepts. Users can simply select a model, upload their dataset, and adjust a few settings to begin training.
Once completed, the web application also allows you to test the model, providing a quick and efficient way to tune LLMs on a local machine.
While standard metrics provide valuable information about the overall performance of a tuned model, custom metrics offer a way to directly evaluate the effectiveness of a model in your specific use case. By customizing metrics, you can better evaluate how well your model meets unique requirements that generic metrics might miss. Custom metrics are invaluable because they offer the flexibility to create and track measures specifically aligned to practical needs, enabling continuous improvement based on relevant and measurable criteria. This approach allows you to focus on domain-specific precision, weighted importance, and user experience alignment.
Getting started with LLaMA-Factory
For this example, we will use a Python environment. Make sure you have Python 3.8 or higher and the necessary dependencies installed based on the repository requirements.
Facility
First we will install all the requirements.
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".(torch,metrics)"Fine tuning with the LLaMA board GUI (powered by Gradio)
llamafactory-cli webuiNote: You can find the official setup guide in more detail here at GitHub.
Understanding evaluation metrics in LLaMA-Factory
Learn about the default evaluation metrics provided by LLaMA-Factory, such as BLEU and ROUGE scores, and why they are essential for evaluating model performance. This section also presents the value of customizing metrics.
BLUE Score
The BLEU (Bilingual Assessment Student) score is a metric used to evaluate the quality of text generated by machine translation models by comparing it to a reference (or human-translated) text. The BLEU score primarily evaluates how similar the generated translation is to one or more reference translations.
blush score
The ROUGE (Retrieval Oriented Substitute for Gisting Evaluation) score is a set of metrics used to evaluate the quality of text summaries by comparing them to reference summaries. It is widely used for summary tasks and measures word and phrase overlap between generated and reference texts.
These metrics are available by default, but you can also add custom metrics tailored to your specific use case.
Prerequisites for adding a custom metric
This guide assumes that LLaMA-Factory is already configured on your machine. Otherwise, refer to the LLaMA-Factory documentation for installation and configuration.
In this example, the function returns a random value between 0 and 1 to simulate a precision score. However, you can replace this with your own evaluation logic to calculate and return a precision value (or any other metric) based on your specific requirements. This flexibility allows you to define custom evaluation criteria that best reflect your use case.
Defining your custom metric
To get started, let's create a Python file called custom_metric.py and define our custom metric function inside it.
In this example, our custom metric is called unknown_score. This metric will take pres (predicted values) and labels (ground truth values) as inputs and return a score based on your custom logic.
import random
def cal_x_score(preds, labels):
"""
Calculate a custom metric score.
Parameters:
preds -- list of predicted values
labels -- list of ground truth values
Returns:
score -- a random value or a custom calculation as per your requirement
"""
# Custom metric calculation logic goes here
# Example: return a random score between 0 and 1
return random.uniform(0, 1)
You can replace the random score with your specific calculation logic.
Modifying sft/metric.py to integrate custom metric
To ensure that the LLaMA Board recognizes our new metric, we will need to integrate it into the metric calculation process within src/llamafactory/train/sft/metric.py
Add your metric to the scoring dictionary:
- Locate the ComputeSimilarity function inside sft/metric.py
- Update self.score_dict to include your new metric as follows:
self.score_dict = {
"rouge-1": (),
"rouge-2": (),
"bleu-4": (),
"x_score": () # Add your custom metric here
}
Calculate and add the custom metric in the __call__ method:
- inside the __call__ method, calculate your custom metric and add it to the opinion_score. Below is an example of how to do it:
from .custom_metric import cal_x_score
def __call__(self, preds, labels):
# Calculate the custom metric score
custom_score = cal_x_score(preds, labels)
# Append the score to 'extra_metric' in the score dictionary
self.score_dict("x_score").append(custom_score * 100)
This integration step is essential for the custom metric to appear in LLaMA Board.
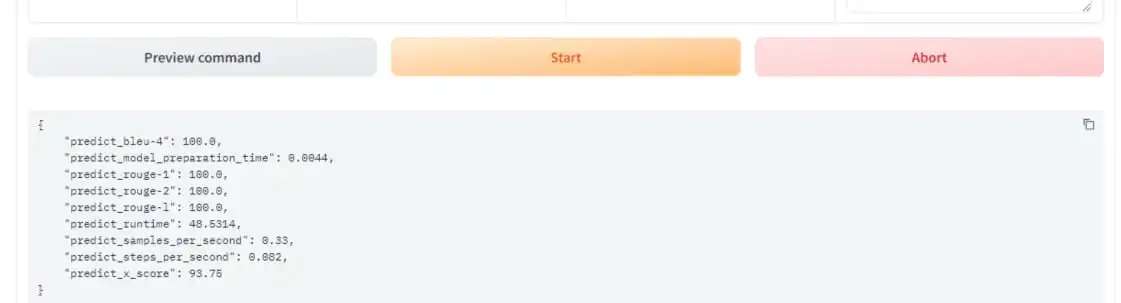
He predict_x_score The metric now appears correctly and shows an accuracy of 93.75% for this model and validation data set. This integration provides a simple way to evaluate each fitted model directly within the evaluation process.
Conclusion
After setting up your custom metric, you should see it in LLaMA Board after running the assessment process. Additional metric scores will be updated for each assessment.
With these steps, you have successfully integrated a custom evaluation metric into LLaMA-Factory! This process gives you the flexibility to go beyond predetermined metrics and tailor model evaluations to meet the unique needs of your project. By defining and implementing metrics specific to your use case, you'll gain more meaningful insights into model performance, highlighting strengths and areas of improvement in ways that matter most to your goals.
Adding custom metrics also allows for a continuous improvement cycle. As you tune and train models with new data or modify parameters, these custom metrics offer a consistent way to evaluate progress. Whether you focus on domain-specific accuracy, user experience alignment, or nuanced scoring methods, LLaMA Board provides a visual and quantitative way to compare and track these results over time.
By improving model evaluation with custom metrics, LLaMA-Factory enables you to make data-driven decisions, accurately refine models, and better align results with real-world applications. This customization capability allows you to create models that work effectively, optimize toward relevant goals, and provide added value in practical implementations.
Key takeaways
- Custom metrics in LLaMA-Factory improve model evaluations by aligning them with the unique needs of the project.
- LLaMA Board allows easy visualization of custom metrics, providing deeper insights into model performance.
- Modifying
metric.pyallows for seamless integration of custom evaluation criteria. - Custom metrics support continuous improvement, tailoring assessments to evolving model goals.
- Customizing metrics allows you to make data-driven decisions, optimizing models for real-world applications.
Frequently asked questions
A. LLaMA-Factory is an open source tool for tuning large language models through an easy-to-use web user interface, with functions for training, deploying, and evaluating models.
A. Custom metrics allow you to evaluate model performance based on criteria specific to your use case, providing insights that standard metrics may not capture.
A. Define your metric in a Python file, specifying the logic for how it should calculate performance based on your data.
A. Add your metric to the sft/metric.py file and update the punctuation dictionary and calculation process to include it.
A. Yes, once you integrate your custom metric, LLaMA Board displays it, allowing you to view your results alongside other metrics.
The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.





{kind=link}