
Large language models (LLMs) are increasingly used for complex reasoning tasks, requiring them to provide accurate answers in various challenging scenarios. These tasks include logical reasoning, complex mathematics, and complex planning applications, requiring the ability to perform multi-step reasoning and solve problems in domains such as decision making and predictive modeling. However, when LLMs attempt to meet these demands, they encounter significant problems, particularly in balancing their ability to answer questions assertively with the risk of generating “mind-blowing” information, answers that seem plausible but lack precision, and falling into patterns of ” laziness”. ” where models frequently resort to saying “I don't know” when they are unsure. Finding a method that allows LLMs to provide accurate and balanced answers without undue conservatism or inaccuracy has been a persistent goal.
LLMs face two central problems when performing these high-stakes reasoning tasks: either they overestimate their abilities, leading to hallucinations, or they become overly cautious and by default reject situations that they could handle effectively. These behaviors arise from the models' need to manage complex, multi-step reasoning processes that accumulate errors at each stage, compounding inaccuracies and reducing reliability. Techniques designed to mitigate hallucinations have primarily focused on factual errors through the integration of external knowledge, retrieval-based strategies, or reinforcement learning (RL) approaches. However, these techniques are better suited for factual tasks and struggle in reasoning-based contexts, where inaccuracies result from failures in logical progression rather than factual errors.
Researchers from the National University of Singapore and Salesforce ai Research have proposed an innovative approach called Carmatic douricle myexpert Yoteration (AUTO-THOSE). This new method introduces a structured “curriculum” approach to LLM training that dynamically adjusts based on model performance, allowing LLMs to align their answers with their actual capabilities. AUTO-CEI leverages a specialized reinforcement learning technique, expert iteration (EI), which iteratively refines the model policy by resampling responses and guiding them along correct reasoning paths. This iterative approach promotes assertive responses within the boundaries of the model and appropriate rejections for complex tasks beyond those boundaries, improving overall reasoning ability.
The AUTO-CEI process begins by training the LLM to evaluate their performance limits. Use the average number of reasoning steps required to arrive at a correct answer as an indicator of the difficulty of the problem. Expert Iteration works within this curriculum, exploring possible paths of reasoning to identify optimal and accurate answers. Correct responses receive positive rewards in this framework, while overly conservative or assertively incorrect responses incur penalties. Furthermore, the curriculum adapts these rewards over time, incentivizing the LLM to engage in extensive reasoning before choosing to reject an answer, thus pushing the limits of the model incrementally and avoiding premature rejections. Through repeated cycles of expert iteration, the curriculum refines the model's ability to handle progressively complex reasoning tasks more robustly.
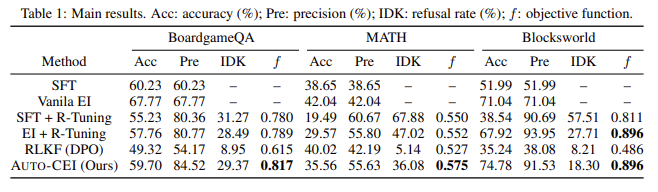
In empirical tests conducted on several benchmarks, including BoardgameQA, MATH, and Blocksworld, AUTO-CEI outperformed other state-of-the-art methods. BoardgameQA, which involves logical reasoning tasks based on rule-based deductions, saw a 10% increase in accuracy from baseline when AUTO-CEI was used, with the model achieving an accuracy of 84.5% and a rate rejection rate of only 29.4%. On MATH, a challenging data set that requires long chains of reasoning in algebra and geometry, AUTO-CEI achieved an accuracy of 35.6%, indicating significant improvements in LLMs' ability to navigate and conclude complex calculations. Meanwhile, in Blocksworld, a planning task where the model must sequence actions to achieve a specific block configuration, AUTO-CEI achieved a rejection rate of only 18.3%, balancing conservatism with the need for assertive reasoning. .
AUTO-CEI's contributions have led to a robust solution to mitigate both hallucinations and excessive denials. The model demonstrates the highest accuracy in reasoning tasks, maintaining a conservative rejection rate and avoiding unnecessary rejections in scenarios where possible solutions exist. AUTO-CEI has achieved accuracy rates that exceed existing reinforcement learning techniques by 10% to 24%, while maintaining rejection rates between 18% and 36%, significantly reducing the model error rate. This marks an improvement over techniques such as Vanilla Expert Iteration and retrieval-based reinforcement learning methods that lack the required assertive control or do not meet the complexity of the task.
The key conclusions of this research are:
- Improved accuracy and precision: AUTO-CEI demonstrates a substantial increase in accuracy, achieving improvements of up to 24% on certain benchmarks, with accuracy rates of up to 80% in complex reasoning contexts.
- Effective balance between assertiveness and conservatism: By refining LLM responses to be assertive within the limits of their ability and appropriately cautious for complex tasks, AUTO-CEI strikes an ideal balance, with rejection rates ranging from 18% to 36%, depending on the complexity of the task.
- Improved robustness in multi-step reasoning: AUTO-CEI reduces incremental errors in long chains of reasoning by rewarding sustained reasoning efforts, thereby minimizing the probability of prematurely incorrect responses.
- Reference performance: AUTO-CEI's accuracy rates on BoardgameQA (84.5%), MATH (35.6%), and Blocksworld (91.5%) show its effective application in various reasoning tasks, establishing it as a versatile solution. for ai-powered reasoning.
In conclusion, AUTO-CEI represents a significant advance in LLM training methodologies by balancing assertive and conservative behaviors based on limits of reasoning. By gradually improving the model's problem-solving ability while mitigating hallucinations and rejections, AUTO-CEI sets a new standard in reliable LLM reasoning on complex tasks, offering a scalable and adaptable solution for future ai development. . This iterative, reward-based approach aligns LLM behaviors with its constraints, ensuring more reliable and effective performance in critical applications across fields that demand precision and insight.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Trend) LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLM) for Intel PCs
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}