 NEWSLETTER
NEWSLETTER
Large language models (LLMs) are widely used in natural language tasks, from question answering to conversational ai. However, a persistent problem with LLMs is “hallucination,” where the model generates answers that are factually incorrect or unfounded in reality. These hallucinations can decrease the reliability of LLMs, posing challenges for practical applications, particularly in fields that require precision, such as medical diagnosis and legal reasoning. To improve the reliability of LLMs, researchers have focused on understanding the causes of hallucinations. They classify hallucinations as arising from a lack of knowledge or from errors that occur despite correct information from the model. By focusing on the roots of these errors, researchers hope to improve the effectiveness of LLMs in several domains.
Researchers address two distinct phenomena by distinguishing between hallucinations caused by missing information and misapplied knowledge. The first type occurs when the model lacks necessary information, such as when it is asked questions about specific, lesser-known facts. In this case, LLMs tend to make up answers that sound plausible but incorrect. The second type arises when the model has the knowledge but still generates an incorrect answer. Such hallucinations indicate a problem with the way the model processes or retrieves its stored knowledge, rather than a question of knowledge scarcity. This distinction is essential since different errors require different interventions.
Traditional methods to mitigate hallucinations in LLM do not adequately address these various causes. Previous approaches often combine both errors into a single category, leading to “one-size-fits-all” detection strategies that rely on large generic data sets. However, this combination limits the ability of these approaches to identify and address the different mechanisms underlying each type of error. Generic data sets cannot account for errors that occur within the model's existing knowledge, meaning valuable data on model processing errors is lost. Without specialized data sets that focus on errors arising from the misapplication of knowledge, researchers have not been able to effectively address the full scope of hallucinations in LLMs.
Researchers from Technion – Israel Institute of technology and Google Research presented the BIZARRE (W.rong TOReply despite docorrect kknowledge) methodology. This approach creates model-specific data sets to differentiate between hallucinations due to missing information and those arising from processing errors. WACK data sets are tailored to the unique knowledge and error patterns of each model, ensuring that hallucinations are analyzed within the context of the model's strengths and weaknesses. By isolating these errors, researchers can gain insight into the different internal mechanisms that give rise to each type of hallucination and develop more effective interventions accordingly.
The WACK methodology uses two experimental setups, “bad shot prompts” and “Alice-Bob prompts,” to induce hallucinations in models with the correct knowledge. These settings create prompts that simulate scenarios in which users or models make subtle errors that cause hallucinations, even when the model theoretically knows the correct answer. In “incorrect prompts,” false responses that resemble correct ones are deliberately introduced into the prompt, simulating a “snowball” effect in which one incorrect response leads to another. In the “Alice-Bob requests” setting, incorrect information is subtly added via a story-like prompt to mimic minor errors a user might enter. Using these techniques, WACK captures how LLMs respond to contextually confusing scenarios, generating data sets that provide more nuanced information about the causes of hallucinations.
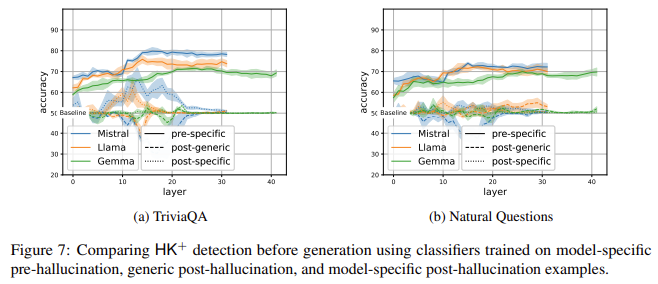
The results of the WACK methodology demonstrated that model-specific data sets significantly outperform generic data sets in detecting hallucinations related to misapplication of knowledge. Experiments with models such as Mistral-7B, Llama-3.1-8B, and Gemma-2-9B showed marked improvements in detecting “hallucinations despite knowledge” (HK+) errors using WACK data sets. For example, while the generic data sets returned 60% to 70% accuracy in identifying these errors, the WACK model-specific data sets achieved detection rates of up to 95% in different configurations. messages. Furthermore, tests using WACK data revealed that the models were able to identify HK+ errors preemptively, based solely on the initial question, a result unattainable with traditional post-response assessments. This high level of accuracy highlights the need for customized data sets to capture nuanced model-specific behaviors and achieve superior hallucination detection.
The WACK research highlights several key insights into the dynamics of LLM hallucinations:
- Accuracy in differentiating errors: Model-specific data sets capture subtle differences in the causes of hallucinations that generic data sets miss, allowing for interventions targeting knowledge shortages and processing errors.
- High precision in HK+ detection: WACK demonstrated up to 95% accuracy in knowledge-based hallucination identification across different LLMs, outperforming traditional detection methods by up to 25%.
- Scalability and applicability: The ability of the WACK methodology to generalize across models shows its adaptability for many LLM architectures, providing an effective model for future LLM improvements.

In conclusion, by distinguishing between hallucinations due to absent knowledge and those arising from misapplied knowledge, the WACK methodology offers a robust solution to improve the accuracy and reliability of LLM. The model-specific, customized data sets provide the nuanced detection needed to address each type of hallucination, marking a significant advance over generic approaches. The researchers' work with WACK has set a new standard for understanding and mitigating hallucinations, improving the reliability of LLMs, and expanding their application in knowledge-intensive fields.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Trend) LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLM) for Intel PCs
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}