 NEWSLETTER
NEWSLETTER
This article delves into Retrieval-Augmented Generation , an advanced ai technique that improves response accuracy by combining retrieval and generation capabilities. You’ll explore how RAG works by first retrieving relevant, up-to-date information from a knowledge base before generating responses, enabling it to provide more reliable and contextually relevant answers. The content covers the RAG workflow in detail, including the use of vector databases for efficient data retrieval, the role of distance metrics for similarity matching, and how RAG mitigates common ai pitfalls like hallucinations and confabulations. Additionally, it outlines practical steps to set up and implement RAG, making this a comprehensive guide for anyone looking to enhance ai-based knowledge retrieval.
Learning Outcomes
- Understand the core principles and architecture of Retrieval-Augmented Generation (RAG) systems.
- Understand the strategies for improving ai hallucinations by implementing RAG, focusing on grounding ai responses in real-time data to enhance factual accuracy and relevance.
- Explore the role of vector databases and distance metrics in data retrieval within RAG workflows.
- Identify strategies to reduce ai hallucinations and improve factual consistency in RAG outputs.
- Gain practical insights into setting up and implementing RAG for enhanced knowledge retrieval.
This article was published as a part of the Data Science Blogathon.
What is Retrieval-Augmented Generation
RAG is an ai technique that improves the accuracy of answers by retrieving relevant information before generating a response. Instead of creating answers based on what the ai model learns from its training, RAG first searches for up-to-date or specific information from a database or knowledge source. It then uses that information to generate a better, more reliable answer. The RAG ai approach combines retrieval-based models with generation-based models to improve the quality and accuracy of generated content, particularly in natural language processing tasks.
Recommended Reading: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Unpacking RAG Architecture
The RAG (Retrieval-Augmented Generation) workflow involves two main stages: retrieval and generation. Below is an overview of how the RAG workflow operates, step by step.
User Query/Prompt
A user query or questions like the one below would act as a prompt.
“What are the most recent developments in quantum computing?”
Retrieval Phase
In the retrieval phase, the three steps below will happen.
- Input: User query/prompt
- Search: The system searches for relevant documents or information in a knowledge base, database, or document collection (often stored as vectors for efficient similarity search, e.g., using a vector database).
- Retrieve Top Results: The system retrieves the most relevant documents or chunks of information that match the user’s query from a vector database (for example). These are usually the top n results (e.g., top 5 or top 10 documents).
Generation Phase
In the retrieval phase, the three steps below will happen.
- Combine Retrieved Information: The system combines the retrieved documents with the input query to provide additional context.
- Generate Answer: A generative model (such as GPT or another transformer-based model) generates a response based on the input query and the retrieved data. This step involves leveraging the model’s learned knowledge and the specific details from the retrieved documents.
- Output: The model produces the final, contextually relevant response, ensuring greater accuracy by grounding it in the retrieved information.
Response Output
The system returns a final response to the user that is more factually accurate and up-to-date than what a purely generative model could produce.
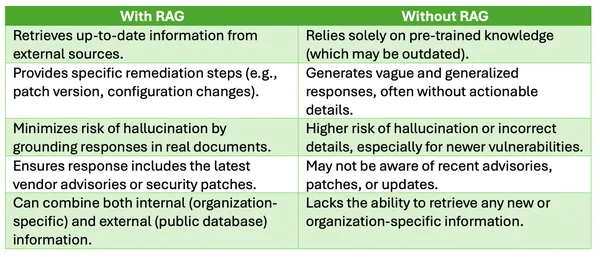
With RAG vs. Without RAG
Exploring ai with and without RAG reveals the transformative impact of Retrieval-Augmented Generation: while traditional models rely solely on pre-trained data, RAG enhances responses with real-time, relevant information retrieval, bridging the gap between static knowledge and dynamic, contextually aware outputs.
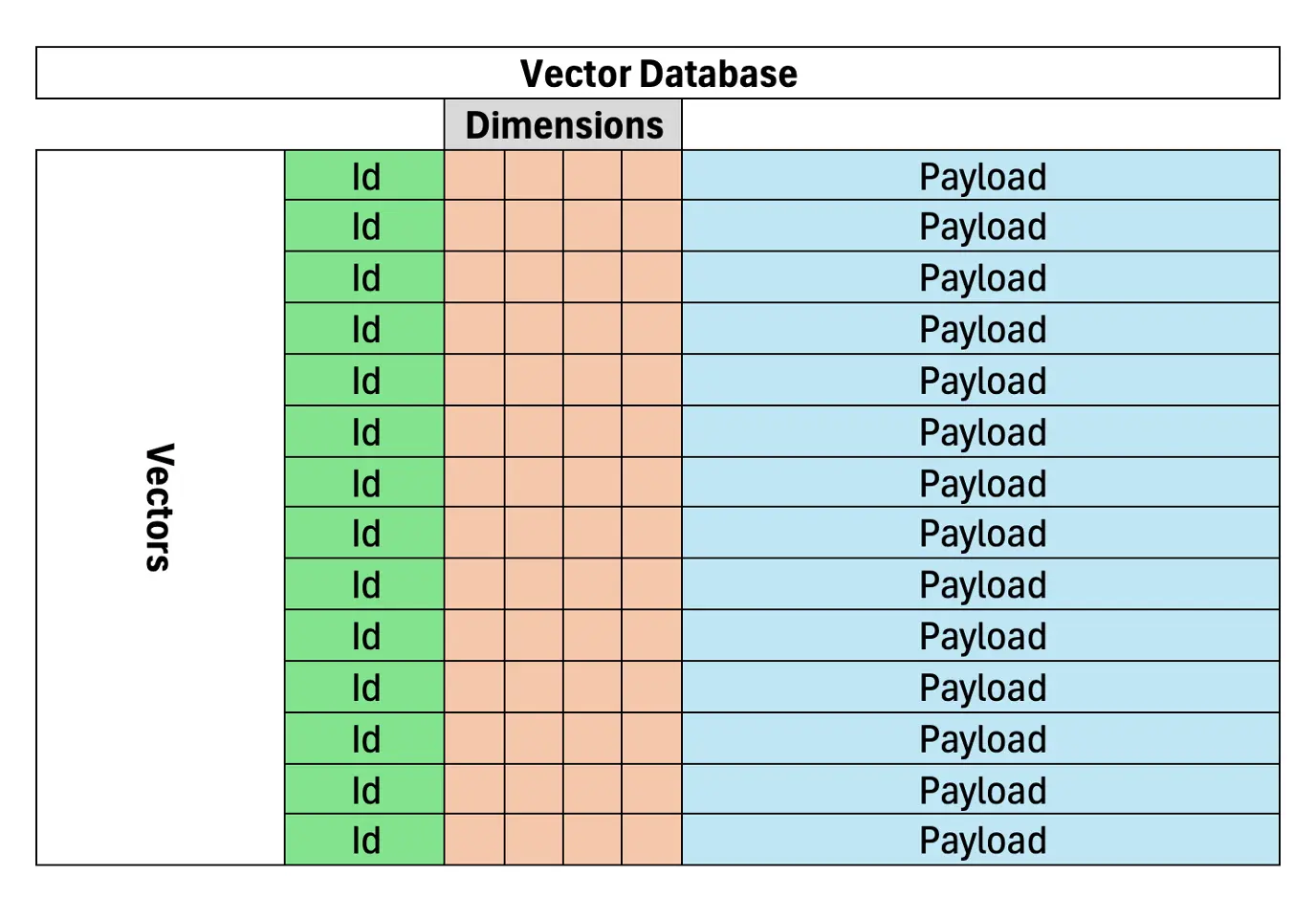
What is a Vector Database?
A vector database plays a critical role in the RAG (Retrieval-Augmented Generation) workflow by enabling efficient and accurate retrieval of relevant documents or data based on semantic similarity. In traditional keyword-based search systems, users retrieve information by matching exact terms, which can cause them to miss pertinent data that uses different wording. A vector database addresses this problem by representing text as vectors in a high-dimensional space, placing similar meanings close to each other and making it highly suitable for RAG-based systems. A vector database is a search engine or database that stores vectorized documents, enabling more accurate information retrieval for ai models. The structure of a vector database looks like the one below.
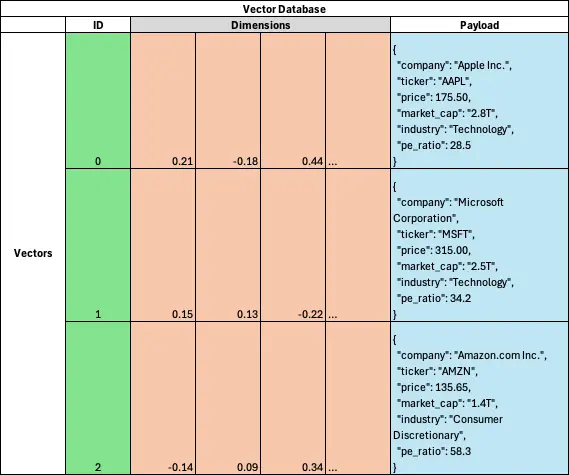
Example of Vector Database
The below example represents how each vector gets stored in a vector database.
{
"id": 0,
"vector": (0.01, -0.03, 0.15, ..., -0.08), // A list of floating-point numbers representing the vector
"payload": {
"company": "Apple Inc.",
"ticker": "AAPL",
"price": 175.50,
"market_cap": "2.8T",
"industry": "technology",
"pe_ratio": 28.5
}
}- ID: 0 — This is the index or ID assigned to this particular point. In the code, this was generated using the enumerate function.
- Vector: (0.01, -0.03, 0.15, …, -0.08) — This is an example vector generated using your chosen encoder (e.g., “all-MiniLM-L6-v2”). The exact values will differ based on the content of the “company” field and the specific encoding model.
- Payload: Contains the original stock information associated with this vector, including details like “company”, “ticker”, “price”, “market_cap”, “industry”, and “pe_ratio”.
- Embeddings: Representing text data as vectors in a high-dimensional space allows similar comparisons between different pieces of text.
- Dimensions: These correspond to the individual components of each vector, where each row represents a vector with multiple dimensions.
When you run the upsert function, Qdrant stores these components as part of a point in a collection. The collection (in this case, “top_stocks”) is designed to organize and manage these points based on the vectors, payloads, and IDs. The data below shows how it looks: It has 384 dimensions in our example, but the diagram below shows only three dimensions for demonstration purposes.
Vector Database vs. OLAP vs. OLTP
Vector databases, OLAP (Online Analytical Processing), and OLTP (Online Transaction Processing) serve different data storage and processing purposes. Here’s a comparison of these systems:
A vector database stores data as high-dimensional vectors or embeddings. Users typically use vector databases for tasks involving semantic search and machine learning applications. These databases perform fast similarity searches, which are essential for ai-based systems like RAG (Retrieval-Augmented Generation). They are also ideal for ai-driven applications requiring semantic search, image recognition, or natural language processing tasks (e.g., search recommendations and Retrieval-Augmented Generation). Examples include Qdrant, Pinecone, FAISS, and Milvus.
OLAP is designed for analytical queries, often over large datasets. OLAP databases support complex queries for data analysis, business intelligence, and reporting. They are best for analyzing large datasets to generate business insights, where complex queries, summarizations, and historical data analysis are necessary (e.g., business intelligence and reporting). Examples: Google BigQuery, amazon Redshift, Snowflake.
OLTP databases efficiently handle high volumes of transactional workloads in real-time, including financial transactions, inventory management, and customer data processing. They excel in real-time, high-volume transactions that require consistent and fast read/write operations, making them ideal for banking systems, inventory management, and e-commerce transactions. Examples: MySQL, PostgreSQL, SQL Server, and Oracle.
Distance Metrics used for RAG
In a vector database, distance metrics measure the similarity or dissimilarity between vectors (high-dimensional representations of data such as text, images, or other forms of unstructured data). These distance metrics are critical for tasks like semantic search and nearest neighbor search because they allow the system to find the most relevant vectors (e.g., documents, images) based on how “close” they are in the vector space to a given query. Common Distance Metrics in Vector Databases are given below:
- Euclidean Distance (L2 Norm)
- Cosine Similarity
- Manhattan Distance (L1 Norm)
- Inner Product (Dot Product)
- Hamming Distance
Table for Function and Use Cases
| Distance Metric | Function | Use Case |
| Euclidean Distance (L2 Norm) | Measures straight-line distance in vector space. | Image retrieval: Finds similar images; Document similarity: Compares document vectors. |
| Cosine Similarity | Measures the cosine angle between vectors, focusing on direction. | Text retrieval: Finds similar texts in NLP; Recommendations: Recommends items based on vector similarity. |
| Manhattan Distance (L1 Norm) | Sum of absolute differences along vector axes. | Robotics/pathfinding: Used in grid maps; Sparse vectors: Suitable for high-dimensional sparse data. |
| Inner Product (Dot Product) | Measures interaction or similarity by multiplying and summing vector components. | Recommendations: Calculates item-user similarity; Neural networks: Activates between layers. |
| Hamming Distance | Counts differing positions in binary vectors. | Error detection: Used in communication; Binary classification: Compares binary vectors in bioinformatics or security. |
Hallucinations and Confabulations
Hallucinations in ai-generated content refer to instances when a language model generates plausible-sounding but incorrect or fabricated information. This happens because models like GPT, BERT, and other large language models (LLMs) are trained on vast datasets but can only access real-time data, databases, or specific facts from their training. They rely on statistical patterns learned from the data, which means that when a prompt doesn’t closely match something the model “knows,” it may create information that fits linguistically but lacks factual grounding.
Example:
- Query: “What is the capital of Australia?”
- Hallucination: “The capital of Australia is Sydney.” (Incorrect – the capital is Canberra.)
Hallucinations happen because the model tries to predict the next word or phrase based on learned patterns but doesn’t always have access to the correct information.
Confabulation is when a model generates plausible but incorrect or fabricated information, like hallucinations. These inaccuracies often arise when the model tries to fill in gaps in its knowledge, leading to outputs that may sound convincing but lack grounding in reality or facts.
Example:
- Query: “Who invented Python?”
- Confabulation: “Python was invented by Linus Torvalds in 1991 as a scripting language for Unix systems.” (Incorrect – Python was invented by Guido van Rossum, not Linus Torvalds, and the reasoning is wrong.)
In confabulation, the ai confidently gives a wrong answer and incorrect justification, making it seem believable. Hallucinations and confabulations refer to errors in ai-generated content but differ in nature and context.
- Hallucinations involve fabricating information that sounds plausible but is incorrect.
- Confabulations involve presenting incorrect information with false confidence, often with incorrect justifications or reasoning.
- RAG helps mitigate both issues by grounding the model’s responses in real time, verifying data from external sources, and ensuring more accurate and reliable answers.
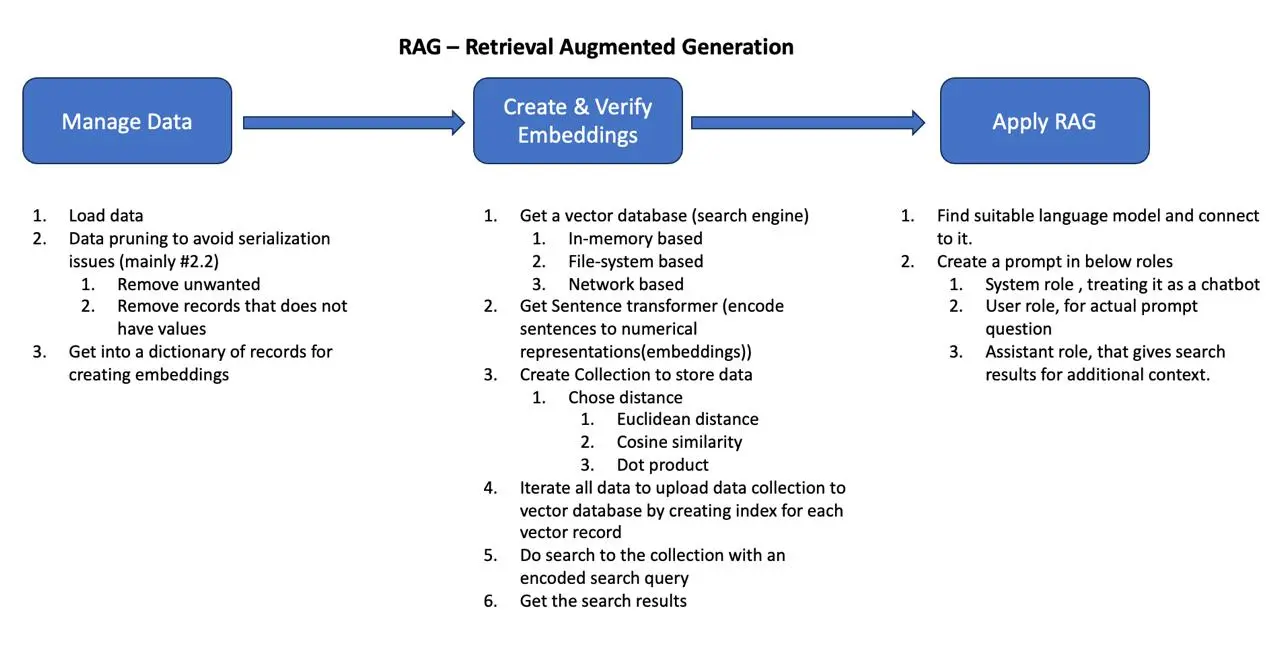
How RAG Works?
To effectively use RAG in your applications, follow the steps below.
- Data management
- Create and Verify Embeddings
- Apply RAG
Below is the workflow for how data gets pruned, embeddings are created, and applied to an LLM/FMHow
Step1: Initial Setup and Configuration
The below example uses Python 3.12 and related frameworks.
- pandas==1.3.5
- ipykernel
- ipywidgets
- qdrant-client==1.9.0
- sentence-transformers==2.2.2
- openai==1.11.1
We recommend using IPython notebooks (interactive Python notebooks) and the Jupyter server for better productivity with any data-oriented programs.
Step2: Data Pruning
Data can come from various sources, such as .csv, .json, and .xml. The Pandas library can load files and supports multiple data formats. We need to do data pruning to make sure there are no missing data.
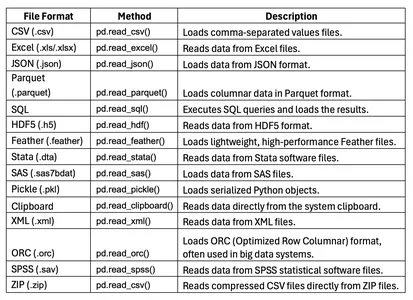
- The code snippet loads the data in .json format.
import pandas as pd
# Step 1: Load and Flatten the JSON Data
df = pd.read_json('../../stock_data.json')
# Normalize the nested JSON structure
df = pd.json_normalize(df('stocks'))
# Step 2: Print columns to verify the structure
print(df.columns)
# Step 3: Filter out any NaN values in 'company' or other fields (if needed)
df = df(df('company').notna())
# Step 4: Convert the DataFrame to a list of dictionaries
data = df.to_dict('records')
df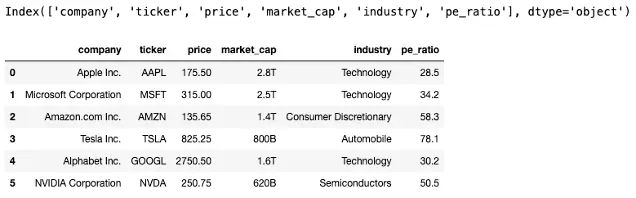
Step3: Initiate Vector Database
We will use Qdrant, a vector database, to demonstrate the RAG. We will also use a sentence transformer to encode sentences into numerical representations (embeddings), allowing us to compare them using cosine similarity or other distance metrics.
from qdrant_client import models, QdrantClient
from sentence_transformers import SentenceTransformer
# Initialize SentenceTransformer model
# Model to create embeddings
encoder = SentenceTransformer('all-MiniLM-L6-v2') The above line is loading the all-MiniLM-L6-v2 model from the sentence-transformers library, a pre-trained model designed for creating text embeddings. This model is lightweight and efficient for many NLP tasks. The all-MiniLM-L6-v2 is a MiniLM model that has been fine-tuned for tasks like sentence embeddings, semantic search, and sentence similarity. It’s part of the Sentence Transformers library, which provides a simple API for generating dense vector representations (embeddings) for text. Initializing the SentenceTransformer object with the model name downloads the pre-trained model from Hugging Face’s model hub. If it hasn’t already been downloaded, it loads it into memory. When you run this sentence transformer line, you will see output like below.
Step4: Create Vector Database Client
# Create the vector database client (In-Memory instance for demonstration)
qdrant = QdrantClient(":memory:")creates an in-memory instance of the Qdrant vector database. Qdrant is a vector search engine that helps store, search, and manage embeddings (vector representations of data) efficiently, typically used for tasks like semantic search, nearest neighbor search, and similarity matching. Below are the different options you can pass to QdrantClient:
qdrant = QdrantClient(“:memory:”)
This creates a temporary, in-memory instance of Qdrant where all data is lost once the program terminates. It’s ideal for prototyping, testing, or short-term use cases.
qdrant = QdrantClient(“http://localhost:6333″)
This connects to a locally running Qdrant instance. You’ll need to install and run the Qdrant server on your machine before connecting to it. The default port for Qdrant is 6333. You can change the port number if you’ve configured Qdrant to run on a different port.
qdrant = QdrantClient(“http://:”)
You can connect to a remote Qdrant server hosted on a different machine or cloud server by specifying the remote server’s IP address and port. If the remote instance requires authentication (API tokens or credentials), you can pass additional arguments for secure access.
Step5: Create Collection
A vector database collection is a specialized data structure that stores high-dimensional vector representations (embeddings) of data along with associated metadata. It allows for efficient similarity searches, which are essential for tasks like semantic search, recommendation systems, and content-based retrieval. Vector databases design collections to manage large-scale data efficiently and return highly relevant, similar items based on vector comparisons. You can create a collection in the following way.
# Create collection in Qdrant
qdrant.recreate_collection(
collection_name="top_stocks",
vectors_config=models.VectorParams(
size=encoder.get_sentence_embedding_dimension(), # Vector size defined by the model
distance=models.Distance.COSINE
)
)This snippet of code is using the QdrantClient to create (or recreate) a collection called “top_stocks” in the Qdrant vector database. Once collection created successfully, it return “True”.
- recreate_collection: This method ensures that if the collection “top_data” already exists, it will be deleted and recreated with the specified configuration.
- collection_name=”top_data”: The name of the collection where the vector data (embeddings) will be stored. In this case, it’s named “top_wines”, which presumably stores embeddings related to wine data.
The configuration of vectors in the collection is set using models.VectorParams, which defines:
- size: The dimensionality of each vector (i.e., how many numbers are in each vector).
- distance: The metric to use for measuring the similarity between vectors (in this case,
Step6: Vectorize Data
Iterate/enumerate the loaded data to create a collection with vectors of dimensions with their id’s and payloads. This can be done in below way.
# Vectorize only valid entries with non-empty "company" values
valid_data = (doc for doc in data if isinstance(doc.get("company", ""), str) and doc("company").strip())
# Proceed to upload points to Qdrant
qdrant.upsert(
collection_name="top_stocks",
points=(
models.PointStruct(
id=idx,
vector=encoder.encode(doc("company")).tolist(), # Encode the "company" name as the vector
payload=doc
) for idx, doc in enumerate(valid_data)
)
)
# Check if the data is successfully uploaded to Qdrant
collection_info = qdrant.get_collection("top_stocks")
print(collection_info)
# Verify if the vectors are uploaded by inspecting the number of points
points = qdrant.scroll(
collection_name="top_stocks",
limit=5,
with_payload=True
)
print(points)The above code uploads points (vectors) to a collection in Qdrant using the upload_points method. Each point comprises an ID, a vector (embedding), and an associated payload (metadata). This takes some time, depending on the data as it loads to the vector database.
Step7: Search Vector Database for a Prompt/Query
# Define the query
query_prompt = "technology company with a high market cap"
# Step 1: Encode the query using the same encoder
query_vector = encoder.encode(query_prompt).tolist()
# Step 2: Search the Qdrant collection for the closest vectors
search_results = qdrant.search(
collection_name="top_stocks",
query_vector=query_vector,
limit=2, # Retrieve the top 5 most similar results
with_payload=True # Include the payload (metadata) in the search results
)
# Step 3: Print the search results
for result in search_results:
print(f"Company: {result.payload('company')}")
print(f"Ticker: {result.payload('ticker')}")
print(f"Industry: {result.payload('industry')}")
print(f"Market Cap: {result.payload('market_cap')}")
print(f"Similarity Score: {result.score}")
print("-" * 30)Using an embedding query string, the above code performs a search query in the Qdrant vector database against the “top_stocks” collection. It retrieves the top 3 most similar vectors and prints each hit’s associated payload (metadata) and similarity score.
Step8: Get Search Results/Hits
search_results_payload = (result.payload for result in search_results)
print(search_results_payload)Extracts the payload (metadata or additional information) from each of the search results (hits) returned by the Qdrant search and stores them in the list search_results.
Step9: Augment Search Results to an LLM
from openai import OpenAI
# Initialize the OpenAI client for the local API server
client = OpenAI(
base_url="http://127.0.0.1:8080/v1", # Local API server
api_key="your api key" # Placeholder API key for local server
)
# Create the completion request (chat)
completion = client.chat.completions.create(
model="LLaMA_CPP", # Using a local model
messages=(
{"role": "system", "content": "You are chatbot, stocks specialist. Your top priority is to help guide users into selecting stocks and guide them with their requests."},
{"role": "user", "content": "What is the market cap of NVIDIA and its P/E ratio?"},
{"role": "assistant", "content": str(search_results)} # Providing search results in the assistant's message
)
)
# Print the assistant's generated message
print(completion.choices(0).message("content"))Output : ChatCompletionMessage(content= ‘The market cap of NVIDIA Corporation is 620B and its P/E ratio is 50.5.’)
Without RAG the output was:
ChatCompletionMessage(content= ‘As of 2021, NVIDIA had a market capitalization of approximately $500 billion and a P/E ratio of around 40’)
The above code uses the OpenAI Python client to interact with a local API server using its API key and generate a response using a locally deployed LLaMA_CPP model (a local version of an LLaMA model).
- System Role: The system message tells the model how to behave, setting it up as a wine specialist chatbot.
- User Role: The user asks for a question or recommendation.
- Assistant Role: The assistant responds with the search_results retrieved from Qdrant (or possibly generated via the model), which will contain relevant information about top data.
Conclusion
In an era where the accuracy and reliability of ai-generated content are paramount, Retrieval-Augmented Generation (RAG) emerges as a breakthrough technique that overcomes key limitations of traditional language models. By integrating real-time data retrieval from external knowledge sources, RAG enhances the factual correctness of ai responses, significantly reducing the risk of hallucinations, confabulations, and data accuracy. This approach empowers models to generate more contextually relevant and precise answers, especially in knowledge-intensive domains.
Moreover, vector databases are indispensable in the RAG workflow, enabling efficient semantic search through high-dimensional embeddings. This ensures that ai systems can retrieve and utilize the most relevant and up-to-date information for generation tasks. RAG represents a critical step forward in pursuing more trustworthy, actionable, and grounded ai outputs as ai evolves. The combination of retrieval and generation phases of RAG enhances the user experience and sets a new standard for ai-driven decision-making and content creation.
Key Takeaways
- RAG improves response accuracy by retrieving relevant information before generating answers.
- It combines retrieval and generation to leverage up-to-date data, producing responses that are more factually grounded than those generated purely by models.
- The workflow includes a retrieval phase to search and retrieve relevant documents, followed by a generation phase to create answers with contextual information.
- RAG method enhances response accuracy by leveraging real-time data retrieval, significantly reducing the incidence of ai hallucinations through contextual and up-to-date information.
- RAG also improves ai hallucinations by grounding generated content in real-time data, improving reliability and accuracy in responses.
- Utilizing vector databases in RAG systems allows for effective similarity matching, which plays a crucial role in improving ai hallucinations by ensuring that the generated responses are grounded in relevant and accurate data.
Frequently Asked Questions
A. RAG (Retrieval Augmented Generation) is a technique that combines retrieval of relevant information from a knowledge base with ai text generation. It’s important because it reduces ai hallucinations by grounding responses in verified data sources.
A. Unlike traditional LLMs that rely solely on their training data, RAG actively retrieves and references current, specific information from a maintained knowledge base before generating responses, ensuring higher accuracy and relevance.
A. Vector databases are specialized databases that store and retrieve data based on semantic similarity. They’re essential for RAG because they enable efficient storage and retrieval of text embeddings (numerical representations of text), allowing quick access to relevant information.
A. RAG systems can be configured to continuously update their knowledge base with new information. The vector database is updated with new embeddings as fresh data arrives, making it immediately available for retrieval.
A. Retrieval-Augmented Generation (RAG) enhances ai accuracy by retrieving real-time, relevant information before generating responses, effectively reducing hallucinations and ensuring more reliable and factually consistent outputs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






{kind=link}