
Con este blog, me gustaría mostrar un pequeño agente integrado con `LangGraph` y Google Gemini con fines de investigación. El objetivo es demostrar un agente de investigación (asistente de papel a voz) que planea resumir el trabajo de investigación. Esta herramienta utilizará un modelo de visión para inferir la información. Este método solo identifica el paso y sus subpasos e intenta obtener la respuesta para esos elementos de acción. Finalmente, todas las respuestas se convierten en conversaciones en las que dos personas discutirán el trabajo. Puedes considerar esto como un mini NotebookLM de Google.
Para profundizar más, estoy usando un único gráfico unidireccional donde la comunicación entre los pasos ocurre de arriba a abajo. También he utilizado conexiones de nodos condicionales para procesar trabajos repetidos.
- Un proceso para construir agentes simples con la ayuda de Langgraph
- Conversación multimodal con Google Gemini llm
<h2 class="wp-block-heading" id="h-paper-to-voice-assistant-map-reduce-in-agentic-ai“>Asistente de papel a voz: reducción de mapas en IA agente
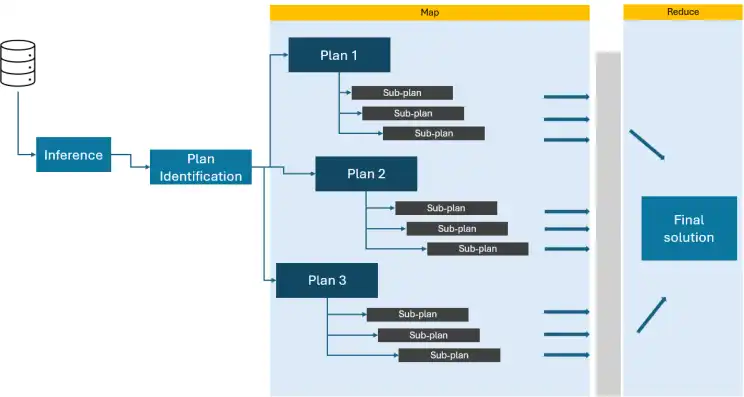
Imagine un problema tan grande que una sola persona tardaría varios días o meses en resolverlo. Ahora, imagine un equipo de personas capacitadas, a cada una de las cuales se le asigna una sección específica de la tarea en la que trabajar. Podrían comenzar clasificando los planes por objetivo o complejidad y luego, gradualmente, unir secciones más pequeñas. Una vez que cada solucionador ha completado su sección, combinan sus soluciones en la final.
Básicamente, así es como funciona map-reduce en Agentic ai. El “problema” principal se divide en enunciados de subproblemas.. El “solucionadores”son LLM individuales, que asignan cada subplan con diferentes solucionadores. Cada solucionador trabaja en su subproblema asignado, realizando cálculos o infiriendo información según sea necesario. Finalmente, se combinan los resultados de todos los “solucionadores” (reducción) para producir el resultado final.
<h2 class="wp-block-heading" id="h-from-automation-to-assistance-the-evolving-role-of-ai-agents”>De la automatización a la asistencia: la evolución del papel de los agentes de IA
Después de los avances en la IA generativa, los agentes LLM son bastante populares y la gente está aprovechando sus capacidades. Algunos sostienen que los agentes pueden automatizar el proceso de principio a fin. Sin embargo, los veo como facilitadores de la productividad. Pueden ayudar a resolver problemas, diseñar flujos de trabajo y permitir que los humanos se concentren en partes críticas. Por ejemplo, los agentes pueden actuar como probadores automatizados que exploran el espacio de las demostraciones matemáticas. Pueden ofrecer nuevas perspectivas y formas de pensar más allá de las pruebas “generadas por humanos”.
Otro ejemplo reciente es Cursor Studio habilitado para IA. El cursor Es un entorno controlado similar al código VS que admite asistencia de programación.
Los agentes también se están volviendo más capaces de planificar y tomar medidas, de forma similar a la forma en que razonan los humanos y, lo más importante, pueden ajustar sus estrategias. Están mejorando rápidamente su capacidad para analizar tareas, desarrollar planes para completarlas y perfeccionar su enfoque mediante la autocrítica repetida. Algunas técnicas implican mantener a los humanos informados, donde los agentes buscan orientación de los humanos a intervalos y luego proceden según esas instrucciones.

¿Qué no está incluido?
- No he incluido ninguna herramienta como búsqueda ni ninguna función personalizada para hacerlo más avanzado.
- No se desarrolla ningún método de enrutamiento ni conexión inversa.
- No se utilizan técnicas de ramificación para procesamiento paralelo o trabajo condicional.
- Se pueden implementar cosas similares cargando pdf y analizando imágenes y gráficos.
- Jugando con solo 3 imágenes en un mensaje.
Bibliotecas de Python utilizadas
- langchain-google-genai : Para conectar langchain con los modelos de IA generativa de Google
- python-dotenv: Para cargar claves secretas o cualquier variable de entorno
- langgrafo: Para construir los agentes
- pypdfium2 y almohada: Para convertir PDF en imágenes
- pydub : para segmentar el audio
- grado_cliente : para llamar al modelo HF
Asistente de papel a voz: implementación práctica
Aquí está la implementación:
Cargue las bibliotecas de soporte
from dotenv import dotenv_values
from langchain_core.messages import HumanMessage
import os
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.graph import StateGraph, START, END,MessagesState
from langgraph.graph.message import add_messages
from langgraph.constants import Send
import pypdfium2 as pdfium
import json
from PIL import Image
import operator
from typing import Annotated, TypedDict # ,Optional, List
from langchain_core.pydantic_v1 import BaseModel # ,FieldCargar variables de entorno
config = dotenv_values("../.env")
os.environ("GOOGLE_API_KEY") = config('GEMINI_API')Actualmente, estoy utilizando un enfoque multimodal en este proyecto. Para lograr esto, cargo un archivo PDF y convierto cada página en una imagen. Luego, estas imágenes se introducen en el modelo de visión de Géminis con fines de conversación.
El siguiente código demuestra cómo cargar un archivo PDF, convertir cada página en una imagen y guardar estas imágenes en un directorio.
pdf = pdfium.PdfDocument("./pdf_image/vision.pdf")
for i in range(len(pdf)):
page = pdf(i)
image = page.render(scale=4).to_pil()
image.save(f"./pdf_image/vision_P{i:03d}.jpg")Mostremos una página para nuestra referencia.
image_path = "./pdf_image/vision_P000.jpg"
img = Image.open(image_path)
imgProducción:

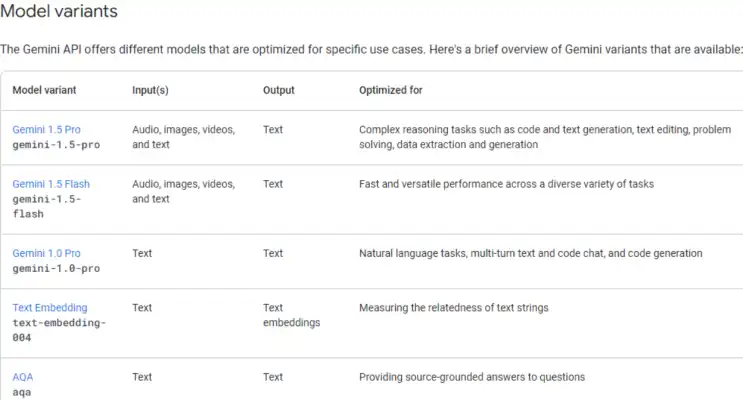
Modelo de visión de Google
Conexión del modelo Gemini mediante clave API. Las siguientes son las diferentes variantes disponibles. Una cosa importante a tener en cuenta es que debemos seleccionar el modelo que admita el tipo de datos. Como estoy trabajando con imágenes en la conversación, necesitaba optar por el Géminis 1.5 Pro o modelos Flash, ya que estas variantes admiten datos de imágenes.
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-flash-001", # "gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
Avancemos construyendo el esquema para administrar la salida y transferir información entre nodos. Utilice el operador agregar para fusionar todos los pasos y subpasos que creará el agente.
class State(TypedDict):
image_path: str # To store reference of all the pages
steps: Annotated(list, operator.add) # Store all the steps generated by the agent
substeps: Annotated(list, operator.add) # Store all the sub steps generated by the agent for every step
solutions: Annotated(list, operator.add) # Store all the solutions generated by the agent for each step
content:str # store the content of the paper
plan:str # store the processed plan
Dialog: Annotated(list, operator.add)El esquema para controlar la salida del primer paso.
class Task(BaseModel):
task: strSchema almacenará el resultado de cada subpaso en función de las tareas identificadas en el paso anterior.
class SubStep(BaseModel):
substep: strEsquema para controlar la salida durante el bucle condicional.
class StepState(TypedDict):
step: str
image_path: str
solutions: str
Dialog: strPaso 1: generar tareas
En nuestro primer paso, pasaremos las imágenes al LLM y le indicaremos que identifique todos los planes que pretende ejecutar para comprender completamente el trabajo de investigación. Proporcionaré varias páginas a la vez y le pediré al modelo que genere un plan combinado basado en todas las imágenes.
def generate_steps(state: State):
prompt="""
Consider you are a research scientist in artificial intelligence who is expert in understanding research papers.
You will be given a research paper and you need to identify all the steps a researcher need to perform.
Identify each steps and their substeps.
"""
message = HumanMessage(content=({'type':'text','text':prompt},
*({"type":'image_url','image_url':img} for img in state('image_path'))
)
)
response = llm.invoke((message))
return {"content": (response.content),"image_path":state('image_path')}Paso 2: análisis del plan
En este paso, tomaremos el plan identificado en el primer paso e indicaremos al modelo que lo convierta a un formato estructurado. Definí el esquema e incluí esa información en el mensaje. Es importante tener en cuenta que se pueden utilizar herramientas de análisis externas para transformar el plan en una estructura de datos adecuada. Para mejorar la solidez, puede utilizar “Herramientas” para analizar los datos o crear también un esquema más riguroso.
def markdown_to_json(state: State):
prompt ="""
You are given a markdown content and you need to parse this data into json format. Follow correctly key and value
pairs for each bullet point.
Follow following schema strictly.
schema:
(
{
"step": "description of step 1 ",
"substeps": (
{
"key": "title of sub step 1 of step 1",
"value": "description of sub step 1 of step 1"
},
{
"key": "title of sub step 2 of step 1",
"value": "description of sub step 2 of step 1"
})},
{
"step": "description of step 2",
"substeps": (
{
"key": "title of sub step 1 of step 2",
"value": "description of sub step 1 of step 2"
},
{
"key": "title of sub step 2 of step 2",
"value": "description of sub step 2 of step 2"
})})'
Content:
%s
"""% state('content')
str_response = llm.invoke((prompt))
return({'content':str_response.content,"image_path":state('image_path')})Paso 3 Envía un mensaje de texto a Json
En el tercer paso, tomaremos el plan identificado en el segundo paso y lo convertiremos al formato JSON. Tenga en cuenta que es posible que este método no siempre funcione si LLM viola la estructura del esquema.
def parse_json(state: State):
str_response_json = json.loads(state('content')(7:-3).strip())
output = ()
for step in str_response_json:
substeps = ()
for item in step('substeps'):
for k,v in item.items():
if k=='value':
substeps.append(v)
output.append({'step':step('step'),'substeps':substeps})
return({"plan":output})Paso 4: solución para cada paso
Este paso se ocupará de los hallazgos de la solución de cada paso. Se necesitará un plan y se combinarán todos los subplanes en un par de Preguntas y Respuestas en un solo mensaje. Además, LLM identificará la solución de cada subpaso.
Este paso también combinará las múltiples salidas en una con la ayuda del Anotador y el operador “agregar”. Por ahora, este paso está funcionando con calidad aceptable. Sin embargo, se puede mejorar utilizando ramificaciones y traduciendo cada subpaso en una indicación de razonamiento adecuada.
Principalmente, cada subpaso debe traducirse en una cadena de pensamiento para que LLM pueda preparar una solución. También se puede usar React.
def sovle_substeps(state: StepState):
print(state)
inp = state('step')
print('solving sub steps')
qanda=" ".join((f'\n Question: {substep} \n Answer:' for substep in inp('substeps')))
prompt=f""" You will be given instruction to analyze research papers. You need to understand the
instruction and solve all the questions mentioned in the list.
Keep the pair of Question and its answer in your response. Your response should be next to the keyword "Answer"
Instruction:
{inp('step')}
Questions:
{qanda}
"""
message = HumanMessage(content=({'type':'text','text':prompt},
*({"type":'image_url','image_url':img} for img in state('image_path'))
)
)
response = llm.invoke((message))
return {"steps":(inp('step')), 'solutions':(response.content)}Paso 5: bucle condicional
Este paso es fundamental para gestionar el flujo de la conversación. Implica un proceso iterativo que traza los planes (pasos) generados y pasa información continuamente de un nodo a otro en un bucle. El ciclo termina una vez que se han ejecutado todos los planes. Actualmente, este paso maneja la comunicación unidireccional entre nodos, pero si es necesaria una comunicación bidireccional, deberíamos considerar implementar diferentes técnicas de ramificación.
def continue_to_substeps(state: State):
steps = state('plan')
return (Send("sovle_substeps", {"step": s,'image_path':state('image_path')}) for s in steps)Paso 6: Voz
Una vez generadas todas las respuestas, el siguiente código las convertirá en un diálogo y luego combinará todo en un podcast con dos personas discutiendo el artículo. El siguiente mensaje está tomado de aquí.
SYSTEM_PROMPT = """
You are a world-class podcast producer tasked with transforming the provided input text into an engaging and informative podcast script. The input may be unstructured or messy, sourced from PDFs or web pages. Your goal is to extract the most interesting and insightful content for a compelling podcast discussion.
# Steps to Follow:
1. **Analyze the Input:**
Carefully examine the text, identifying key topics, points, and interesting facts or anecdotes that
could drive an engaging podcast conversation. Disregard irrelevant information or formatting issues.
2. **Brainstorm Ideas:**
In the ``, creatively brainstorm ways to present the key points engagingly. Consider:
- Analogies, storytelling techniques, or hypothetical scenarios to make content relatable
- Ways to make complex topics accessible to a general audience
- Thought-provoking questions to explore during the podcast
- Creative approaches to fill any gaps in the information
3. **Craft the Dialogue:**
Develop a natural, conversational flow between the host (Jane) and the guest speaker (the author or an expert on the topic). Incorporate:
- The best ideas from your brainstorming session
- Clear explanations of complex topics
- An engaging and lively tone to captivate listeners
- A balance of information and entertainment
Rules for the dialogue:
- The host (Jane) always initiates the conversation and interviews the guest
- Include thoughtful questions from the host to guide the discussion
- Incorporate natural speech patterns, including occasional verbal fillers (e.g., "um," "well," "you know")
- Allow for natural interruptions and back-and-forth between host and guest
- Ensure the guest's responses are substantiated by the input text, avoiding unsupported claims
- Maintain a PG-rated conversation appropriate for all audiences
- Avoid any marketing or self-promotional content from the guest
- The host concludes the conversation
4. **Summarize Key Insights:**
Naturally weave a summary of key points into the closing part of the dialogue. This should feel like a casual conversation rather than a formal recap, reinforcing the main takeaways before signing off.
5. **Maintain Authenticity:**
Throughout the script, strive for authenticity in the conversation. Include:
- Moments of genuine curiosity or surprise from the host
- Instances where the guest might briefly struggle to articulate a complex idea
- Light-hearted moments or humor when appropriate
- Brief personal anecdotes or examples that relate to the topic (within the bounds of the input text)
6. **Consider Pacing and Structure:**
Ensure the dialogue has a natural ebb and flow:
- Start with a strong hook to grab the listener's attention
- Gradually build complexity as the conversation progresses
- Include brief "breather" moments for listeners to absorb complex information
- End on a high note, perhaps with a thought-provoking question or a call-to-action for listeners
"""def generate_dialog(state):
text = state('text')
tone = state('tone')
length = state('length')
language = state('language')
modified_system_prompt = SYSTEM_PROMPT
modified_system_prompt += f"\n\PLEASE paraphrase the following TEXT in dialog format."
if tone:
modified_system_prompt += f"\n\nTONE: The tone of the podcast should be {tone}."
if length:
length_instructions = {
"Short (1-2 min)": "Keep the podcast brief, around 1-2 minutes long.",
"Medium (3-5 min)": "Aim for a moderate length, about 3-5 minutes.",
}
modified_system_prompt += f"\n\nLENGTH: {length_instructions(length)}"
if language:
modified_system_prompt += (
f"\n\nOUTPUT LANGUAGE : The the podcast should be {language}."
)
messages = modified_system_prompt + '\nTEXT: '+ text
response = llm.invoke((messages))
return {"Step":(state('step')),"Finding":(state('text')), 'Dialog':(response.content)}def continue_to_substeps_voice(state: State):
print('voice substeps')
solutions = state('solutions')
steps = state('steps')
tone="Formal" # ("Fun", "Formal")
return (Send("generate_dialog", {"step":st,"text": s,'tone':tone,'length':"Short (1-2 min)",'language':"EN"}) for st,s in zip(steps,solutions))Paso 7: construcción del gráfico
Ahora es el momento de seguir todos los pasos que hemos descrito:
- Inicializar el gráfico: Comience inicializando el gráfico y definiendo todos los nodos necesarios.
- Definir y conectar nodos: Conecta los nodos mediante bordes, asegurando el flujo de información de un nodo a otro.
- Introducir el bucle: Implemente el bucle como se describe en el paso 5, permitiendo el procesamiento iterativo de los planes.
- Terminar el proceso: Finalmente, use el método END de LangGraph para cerrar y finalizar el proceso adecuadamente.
Es hora de mostrar la red para una mejor comprensión.
graph = StateGraph(State)
graph.add_node("generate_steps", generate_steps)
graph.add_node("markdown_to_json", markdown_to_json)
graph.add_node("parse_json", parse_json)
graph.add_node("sovle_substeps", sovle_substeps)
graph.add_node("generate_dialog", generate_dialog)
graph.add_edge(START, "generate_steps")
graph.add_edge("generate_steps", "markdown_to_json")
graph.add_edge("markdown_to_json", "parse_json")
graph.add_conditional_edges("parse_json", continue_to_substeps, ("sovle_substeps"))
graph.add_conditional_edges("sovle_substeps", continue_to_substeps_voice, ("generate_dialog"))
graph.add_edge("generate_dialog", END)
app = graph.compile()
Es hora de mostrar la red para una mejor comprensión.
from IPython.display import Image, display
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception:
print('There seems error')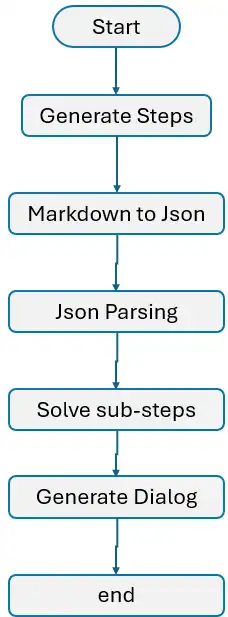
Comencemos el proceso y evaluemos cómo opera el marco actual. Por ahora, estoy probando con sólo tres imágenes, aunque esto se puede extender a varias imágenes. El código tomará imágenes como entrada y pasará estos datos al punto de entrada del gráfico. Posteriormente, cada paso tomará la entrada del paso anterior y pasará la salida al siguiente paso hasta que se complete el proceso.
output = ()
for s in app.stream({"image_path": (f"./pdf_image/vision_P{i:03d}.jpg" for i in range(6))}):
output.append(s)
with open('./data/output.json','w') as f:
json.dump(output,f)Producción:
with open('./data/output.json','r') as f:
output1 = json.load(f)print(output1(10)('generate_dialog')('Dialog')(0))Producción:
Estoy usando el siguiente código para transmitir los resultados de forma secuencial, donde cada plan y subplan se asignará a una respuesta correspondiente.
import sys
import time
def printify(tx,stream=False):
if stream:
for char in tx:
sys.stdout.write(char)
sys.stdout.flush()
time.sleep(0.05)
else:
print(tx)topics =()
substeps=()
for idx, plan in enumerate(output1(2)('parse_json')('plan')):
topics.append(plan('step'))
substeps.append(plan('substeps'))Separemos las respuestas de cada subpaso.
text_planner = {}
stream = False
for topic,substep,responses in zip(topics,substeps,output1(3:10)):
response = responses('sovle_substeps')
response_topic = response('steps')
if topic in response_topic:
answer = response('solutions')(0).strip().split('Answer:')
answer =(ans.strip() for ans in answer if len(ans.strip())>0)
for q,a in zip(substep,answer):
printify(f'Sub-Step : {q}\n',stream=stream)
printify(f'Action : {a}\n',stream=stream)
text_planner(topic)={'answer':list(zip(substep,answer))}El resultado de los subpasos y su acción

El último nodo del gráfico convierte todas las respuestas en diálogo. Almacenémoslos en variables separadas para poder convertirlos en voz.
stream = False
dialog_planner ={}
for topic,responses in zip(topics,output1(10:17)):
dialog = responses('generate_dialog')('Dialog')(0)
dialog = dialog.strip().split('## Podcast Script')(-1).strip()
dialog = dialog.replace('(Guest Name)','Robin').replace('**Guest:**','**Robin:**')
printify(f'Dialog: : {dialog}\n',stream=stream)
dialog_planner(topic)=dialogSalida del cuadro de diálogo
Diálogo a voz
from pydantic import BaseModel, Field
from typing import List, Literal, Tuple, Optional
import glob
import os
import time
from pathlib import Path
from tempfile import NamedTemporaryFile
from scipy.io.wavfile import write as write_wav
import requests
from pydub import AudioSegment
from gradio_client import Client
import json
from tqdm.notebook import tqdm
import sys
from time import sleepwith open('./data/dialog_planner.json','r') as f:
dialog_planner1 = json.load(f)Ahora, conviertamos estos diálogos de texto en voz.
1. Texto a voz
Por ahora, estoy accediendo al modelo tts desde el punto final HF y, para ello, necesito configurar la URL y la clave API.
HF_API_URL = config('HF_API_URL')
HF_API_KEY = config('HF_API_KEY')
headers = {"Authorization": HF_API_KEY}2. Cliente Gradio
Estoy usando el cliente Gradio para llamar al modelo y establecer la siguiente ruta para que el cliente gradio Puede guardar los datos de audio en el directorio especificado. Si no se define ninguna ruta, el cliente almacenará el audio en un directorio temporal.
os.environ('GRADIO_TEMP_DIR') = "path_to_data_dir"
hf_client = Client("mrfakename/MeloTTS")
hf_client.output_dir= "path_to_data_dir"
def get_text_to_voice(text,speed,accent,language):
file_path = hf_client.predict(
text=text,
language=language,
speaker=accent,
speed=speed,
api_name="/synthesize",
)
return(file_path)3. Acento de voz
Para generar la conversación del podcast estoy asignando dos acentos diferentes: uno para el presentador y otro para el invitado.
def generate_podcast_audio(text: str, language: str) -> str:
if "**Jane:**" in text:
text = text.replace("**Jane:**",'').strip()
accent = "EN-US"
speed = 0.9
elif "**Robin:**" in text: # host
text = text.replace("**Robin:**",'').strip()
accent = "EN_INDIA"
speed = 1
else:
return 'Empty Text'
for attempt in range(3):
try:
file_path = get_text_to_voice(text,speed,accent,language)
return file_path
except Exception as e:
if attempt == 2: # Last attempt
raise # Re-raise the last exception if all attempts fail
time.sleep(1) # Wait for 1 second before retrying4. Almacene la voz en un archivo mp3.
Cada clip de audio tendrá una duración inferior a 2 minutos. Esta sección generará audio para cada conversación breve y los archivos se guardarán en el directorio especificado.
def store_voice(topic_dialog):
audio_path = ()
item =0
for topic,dialog in tqdm(topic_dialog.items()):
dialog_speaker = dialog.split("\n")
for speaker in tqdm(dialog_speaker):
one_dialog = speaker.strip()
language_for_tts = "EN"
if len(one_dialog)>0:
audio_file_path = generate_podcast_audio(
one_dialog, language_for_tts
)
audio_path.append(audio_file_path)
# continue
sleep(5)
break
return(audio_path)audio_paths = store_voice(topic_dialog=dialog_planner1)5. Audio combinado
Finalmente, combinemos todos los clips de audio cortos para crear una conversación más larga.
def consolidate_voice(audio_paths,voice_dir):
audio_segments =()
voice_path = (paths for paths in audio_paths if paths!='Empty Text')
audio_segment = AudioSegment.from_file(voice_dir+"/light-guitar.wav")
audio_segments.append(audio_segment)
for audio_file_path in tqdm(voice_path):
audio_segment = AudioSegment.from_file(audio_file_path)
audio_segments.append(audio_segment)
audio_segment = AudioSegment.from_file(voice_dir+"/ambient-guitar.wav")
audio_segments.append(audio_segment)
combined_audio = sum(audio_segments)
temporary_directory = voice_dir+"/tmp/"
os.makedirs(temporary_directory, exist_ok=True)
temporary_file = NamedTemporaryFile(
dir=temporary_directory,
delete=False,
suffix=".mp3",
)
combined_audio.export(temporary_file.name, format="mp3")consolidate_voice(audio_paths=audio_paths,voice_dir="./data")Además, para comprender mejor la IA del agente, explore: El programa pionero de la IA del agente.
Conclusión
En general, este proyecto está destinado exclusivamente a fines de demostración y requerirá un esfuerzo y cambios de proceso significativos para crear un agente listo para producción. Puede servir como prueba de concepto (POC) con un mínimo esfuerzo. En esta demostración, no he tenido en cuenta factores como la complejidad del tiempo, el costo y la precisión, que son consideraciones críticas en un entorno de producción. Dicho esto, concluiré aquí. Gracias por leer. Para obtener más detalles técnicos, consulte GitHub.
Preguntas frecuentes
Respuesta. El asistente Paper-to-Voice está diseñado para simplificar el proceso de resumir trabajos de investigación al convertir la información extraída a un formato conversacional, lo que permite una fácil comprensión y accesibilidad.
Respuesta. El asistente utiliza un enfoque de reducción de mapas, en el que divide el trabajo de investigación en pasos y subpasos, procesa la información utilizando LangGraph y Google Gemini LLM y luego combina los resultados en un diálogo coherente.
Respuesta. El proyecto utiliza LangGraph, modelos de IA generativa de Google Gemini, procesamiento multimodal (visión y texto) y conversión de texto a voz con la ayuda de bibliotecas de Python como pypdfium2, Pillow, pydub y gradio_client.
Respuesta. Sí, el agente puede analizar archivos PDF que contienen imágenes convirtiendo cada página en imágenes e introduciéndolas en el modelo de visión, lo que le permite extraer información visual y textual.
Respuesta. No, este proyecto es una prueba de concepto (POC) que demuestra el flujo de trabajo. Se necesita una mayor optimización, manejo de la complejidad del tiempo, costos y ajustes de precisión para que esté listo para producción.






{kind=link}