
Large language models (LLMs) have revolutionized several domains, including code completion, where artificial intelligence predicts and suggests code based on a developer's previous inputs. This technology significantly improves productivity, allowing developers to write code faster and with fewer errors. Despite the promise of LLMs, many models struggle to balance speed and accuracy. Larger models typically have higher accuracy, but introduce delays that make real-time encoding tasks difficult, leading to inefficiency. This challenge has spurred efforts to create smaller, more efficient models that retain high performance in code completion.
The main problem in the field of LLMs for code completion is the balance between model size and performance. Larger models, while powerful, require more time and computational resources, resulting in slower response times for developers. This decreases its usability, particularly in real-time applications where quick feedback is essential. The need for faster and lighter models that still offer high accuracy in code predictions has become a crucial research focus in recent years.
Traditional code completion methods typically involve extending LLMs to increase prediction accuracy. These methods, such as those used in CodeLlama-34B and StarCoder2-15B, rely on huge data sets and billions of parameters, significantly increasing their size and complexity. While this approach improves the models' ability to generate accurate code, it comes at the cost of increased response times and increased hardware requirements. Developers often find that the size of these models and the computational demands hinder their workflow.
The aiXcoder and Peking University research team presented aiXcoder-7Bdesigned to be lightweight and highly effective in code completion tasks. With only 7 billion parameters, it achieves remarkable accuracy compared to larger models, making it an ideal solution for real-time encoding environments. aiXcoder-7B focuses on balancing size and performance, ensuring it can be deployed in academia and industry without the computational burdens typical of larger LLMs. The model's efficiency sets it apart in a field dominated by much larger alternatives.
The research team employed multi-objective training, including methods such as Next-Token Prediction (NTP), Fill-In-the-Middle (FIM), and the advanced Structured Fill-In-the-Middle (SFIM). SFIM, in particular, allows the model to consider the syntax and structure of the code in greater depth, allowing it to predict more accurately across a wide range of coding scenarios. This contrasts with other models that often only consider code as plain text without understanding its structural nuances. aiXcoder-7B's ability to predict missing code segments within a function or between files gives it a unique advantage in real-world programming tasks.
The training process for aiXcoder-7B involved using an extensive data set of 1.2 billion unique tokens. The model was trained using a rigorous data collection process that included crawling, cleaning, deduplication, and data quality checks. The dataset included 3.5TB of source code from multiple programming languages, ensuring the model could handle multiple languages, including Python, Java, C++, and JavaScript. To further improve its performance, aiXcoder-7B used various data sampling strategies, such as sampling based on file content similarities, file dependencies, and file path similarities. These strategies helped the model understand contexts between files, which is crucial for tasks where code completion depends on references spread across multiple files.
aiXcoder-7B outperformed six similarly sized LLMs on six different benchmarks. In particular, the HumanEval benchmark achieved a Pass@1 score of 54.9%, outperforming even larger models such as CodeLlama-34B (48.2%) and StarCoder2-15B (46.3%). In another benchmark, FIM-Eval, aiXcoder-7B demonstrated strong generalization capabilities across different types of code, achieving superior performance in languages such as Java and Python. Its ability to generate code that closely resembles human-written code, both in style and length, further distinguishes it from its competitors. For example, in Java, aiXcoder-7B produced only 0.97 times the size of human-written code compared to other models that produced much longer code.
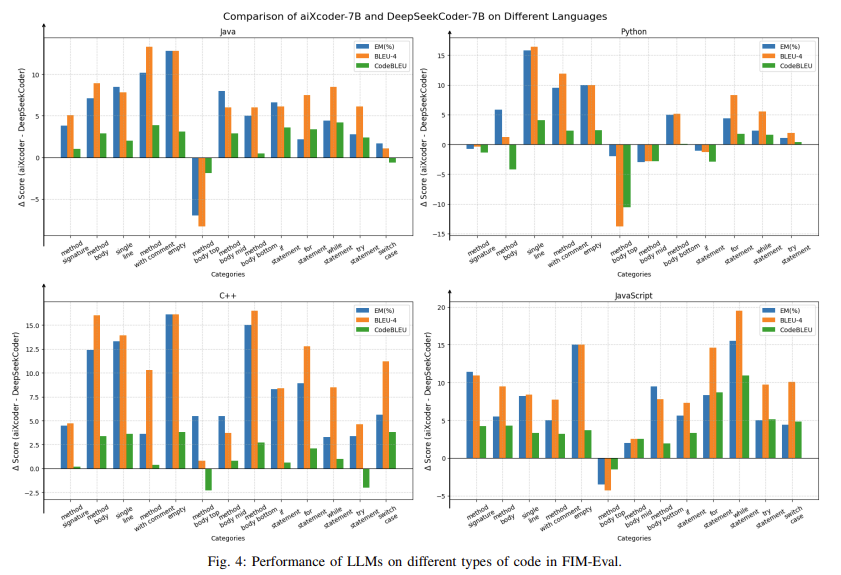
The aiXcoder-7B shows the potential to create smaller, faster and more efficient LLMs without sacrificing accuracy. Its performance across multiple benchmarks and programming languages positions it as a great tool for developers who need to complete code reliably and in real time. The combination of multi-objective training, a large data set, and innovative sampling techniques has allowed aiXcoder-7B to set a new standard for lightweight LLMs in this domain.
In conclusion, aiXcoder-7B addresses a critical gap in the field of LLMs for code completion by offering a highly efficient and accurate model. The research behind the model highlights several key conclusions that can guide future development in this area:
- Seven billion parameters ensure efficiency without sacrificing precision.
- It uses multi-objective training, including SFIM, to improve prediction capabilities.
- Trained with 1.2 billion tokens with a comprehensive data collection process.
- It outperforms larger models on benchmarks, achieving a 54.9% Pass@1 on HumanEval.
- Able to generate code that closely reflects human-written code in both style and length.
look at the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml.
(Next live webinar: October 29, 2024) Best platform to deliver optimized models: Predibase inference engine (promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>




{kind=link}