
The increasing reliance on large language models for coding support raises an important problem: what is the best way to evaluate the real-world impact on programmer productivity? Current approaches, such as static benchmarking based on datasets like HumanEval, measure code correctness, but cannot capture the dynamic, human interaction of actual programming activity. As LLMs are increasingly integrated into coding environments and deployed in chat, suggestion, or real-time environments, now is the time to reconsider measuring not only LLMs' ability to complete tasks but also their impact. in human productivity. A much-needed contribution towards developing an assessment framework that is more pragmatic would be to ensure that these LLMs actually improve the true productivity of coding outside the laboratory.
Although many LLMs are designed for programming tasks, the evaluation of many of these LLMs still relies heavily on static benchmarks such as HumanEval and MBPP, in which models are judged not based on how well they can help users. human programmers but based on correctness. of code generated by themselves. While precision is vital for quantitatively measuring benchmarks, practicalities in real-world scenarios are often neglected. All types of programmers continually engage in LLM and iteratively modify their work in practical, real-world environments. None of these traditional approaches capture key metrics, such as how much time programmers spend coding, how often programmers accept LLM suggestions, or the degree to which LLMs actually help solve complex problems. The gap between theoretical classifications and practical utility raises questions about the generalizability of these methods, as they cannot represent actual LLM use and actual productivity gains are difficult to measure.
Researchers from MIT, Carnegie Mellon University, IBM Research, UC Berkeley, and Microsoft developed RealHumanEval, an innovative platform designed for human-centered evaluation of LLMs in programming. It enables real-time assessment of LLMs through two interaction modes: auto-complete suggestions or via chat-based assistance. Detailed logs of user interaction on the platform are recorded for accepted code suggestions and the time taken to complete a task. Real human evaluation goes beyond any static benchmarks by focusing on human productivity metrics that provide a much better understanding of how well LLMs perform once integrated with real-world coding workflows. This helps bridge the gap between theoretical performance and practice, providing insight into the ways in which LLMs help or hinder the coding process.
RealHumanEval allows users to interact via both autocomplete and chat, recording various aspects of these interactions. The current evaluation tested seven different LLMs, including models from the GPT and CodeLlama families on a set of 17 coding tasks with varying complexity. The system recorded a host of productivity metrics: completion time per task, number of tasks completed, and how often a user accepted a suggested LLM code. For this experiment, 243 participants participated and all collected data were analyzed to see how different LLMs contributed to greater coding efficiency. It analyzes them in detail and provides the results of interaction analysis to provide insights into the effectiveness of LLMs in the wild coding environment and provides detailed nuances of human-LLM collaboration.
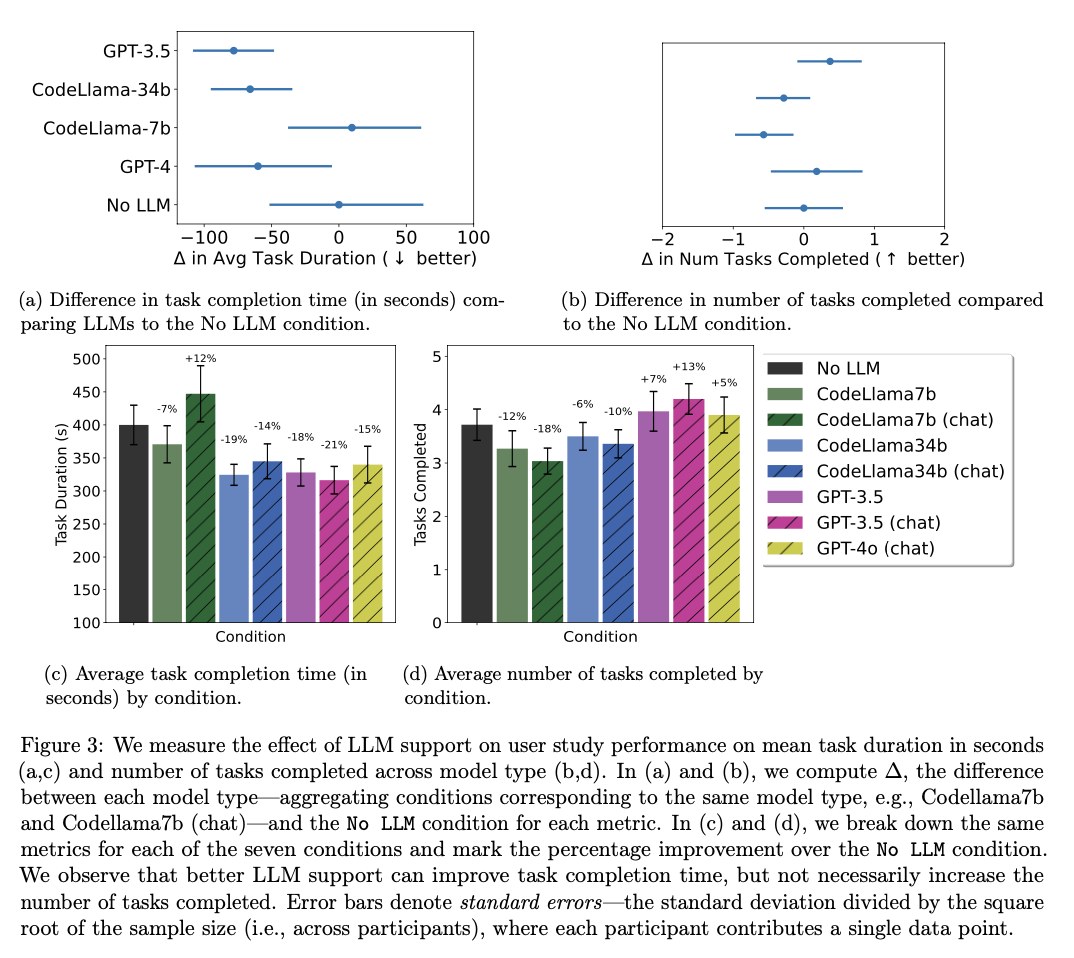
RealHumanEval testing of LLMs showed that the highest-performing models in the benchmarks generate significant gains in coding productivity, especially by saving time. For example, the previous models, GPT-3.5 and CodeLlama-34b completed tasks 19% and 15% faster, respectively, for programmers. On other occasions, the gain in productivity measures cannot be stated as uniform for all the models considered. An example of this is that there is not enough positive evidence regarding CodeLlama-7b. Additionally, although the time required to complete tasks has been reduced, the no. of tasks completed did not change much, meaning that LLMs will speed up the completion of individual tasks but, overall, do not necessarily increase the total number. of tasks completed in a given period of time. Again, acceptance of code hints was different for various models; GPT-3.5 was more accepted by users than the rest. These results highlight that while LLMs can potentially boost productivity, they actually have the power to boost output, but this is highly contextual.
In conclusion, RealHumanEval is a landmark testbed for LLMs in programming because it focuses on human-centric productivity metrics rather than traditional static benchmarks and therefore offers much-needed complementary insight into how well LLMs support real-world programmers. RealHumanEval allows deep insight into efficiency gains and user interaction patterns that help convey the strengths and limitations of LLMs when used in coding environments. This would be a contribution to this line of research for future research and development towards ai-assisted programming by providing valuable information on the optimization of such tools for practical use.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml.
(Next live webinar: October 29, 2024) Best platform to deliver optimized models: Predibase inference engine (promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}