

Clustering is a powerful technique within unsupervised machine learning that groups a given data based on their inherent similarities. Unlike supervised learning methods, such as classification, which rely on pre-labeled data to guide the learning process, clustering operates on unlabeled data. This means there are no predefined categories or labels and instead, the algorithm discovers the underlying structure of the data without prior knowledge of what the grouping should look like.
The main goal of clustering is to organize data points into clusters, where data points within the same cluster have higher similarity to each other compared to those in different clusters. This distinction allows the clustering algorithm to form groups that reflect natural patterns in the data. Essentially, clustering aims to maximize intra-cluster similarity while minimizing inter-cluster similarity. This technique is particularly useful in use-cases where you need to find hidden relationships or structure in data, making it valuable in areas such as fraud detection and anomaly identification.
By applying clustering, one can reveal patterns and insights that might not be obvious through other methods, and its simplicity and flexibility makes it adaptable to a wide variety of data types and applications.
A practical application of clustering is fraud detection in online systems. Consider an example where multiple users are making requests to a website, and each request includes details like the IP address, time of the request, and transaction amount.
Here’s how clustering can help detect fraud:
- Imagine that most users are making requests from unique IP addresses, and their transaction patterns naturally differ.
- However, if multiple requests come from the same IP address and show similar transaction patterns (such as frequent, high-value transactions), it could indicate that a fraudster is making multiple fake transactions from one source.
By clustering all user requests based on IP address and transaction behavior, we could detect suspicious clusters of requests that all originate from a single IP. This can flag potentially fraudulent activity and help in taking preventive measures.
An example diagram that visually demonstrates the concept of clustering is shown in the figure below.
Imagine you have data points representing transaction requests, plotted on a graph where:
- x-axis: Number of requests from the same IP address.
- Y-axis: Average transaction amount.
On the left side, we have the raw data. Without labels, we might already see some patterns forming. On the right, after applying clustering, the data points are grouped into clusters, with each cluster representing a different user behavior.
To group data effectively, we must define a similarity measure, or metric, that quantifies how close data points are to each other. This similarity can be measured in multiple ways, depending on the data’s structure and the insights we aim to discover. There are two key approaches to measuring similarity — manual similarity measures and embedded similarity measures.
A manual similarity measure involves explicitly defining a mathematical formula to compare data points based on their raw features. This method is intuitive and we can use distance metrics like Euclidean distance, cosine similarity, or Jaccard similarity to evaluate how similar two points are. For instance, in fraud detection, we could manually compute the Euclidean distance between transaction attributes (e.g transaction amount, frequency of requests) to detect clusters of suspicious behavior. Although this approach is relatively easy to set up, it requires careful selection of the relevant features and may miss deeper patterns in the data.
On the other hand, an embedded similarity measure leverages the power of machine learning models to create learned representations, or embeddings of the data. Embeddings are vectors that capture complex relationships in the data and can be generated from models like Word2Vec for text or neural networks for images. Once these embeddings are computed, similarity can be measured using traditional metrics like cosine similarity, but now the comparison occurs in a transformed, lower-dimensional space that captures more meaningful information. Embedded similarity is particularly useful for complex data, such as user behavior on websites or text data in natural language processing. For example, in a movie or ads recommendation system, user actions can be embedded into vectors, and similarities in this embedding space can be used to recommend content to similar users.
While manual similarity measures provide transparency and greater control on feature selection and setup, embedded similarity measures give the ability to capture deeper and more abstract relationships in the data. The choice between the two depends on the complexity of the data and the specific goals of the clustering task. If you have well-understood, structured data, a manual measure may be sufficient. But if your data is rich and multi-dimensional, such as in text or image analysis, an embedding-based approach may give more meaningful clusters. Understanding these trade-offs is key to selecting the right approach for your clustering task.
In cases like fraud detection, where the data is often rich and based on behavior of user activity, an embedding-based approach is generally more effective for capturing nuanced patterns that could signal risky activity.
Coordinated fraudulent attack behaviors often exhibit specific patterns or characteristics. For instance, fraudulent activity may originate from a set of similar IP addresses or rely on consistent, repeated tactics. Detecting these patterns is crucial for maintaining the integrity of a system, and clustering is an effective technique for grouping entities based on shared traits. This helps the identification of potential threats by examining the collective behavior within clusters.
However, clustering alone may not be enough to accurately detect fraud, as it can also group benign activities alongside harmful ones. For example, in a social media environment, users posting harmless messages like “How are you today?” might be grouped with those engaged in phishing attacks. Hence, additional criteria is necessary to separate harmful behavior from benign actions.
To address this, we introduce the Behavioral Analysis and Cluster Classification System (BACCS) as a framework designed to detect and manage abusive behaviors. BACCS works by generating and classifying clusters of entities, such as individual accounts, organizational profiles, and transactional nodes, and can be applied across a wide range of sectors including social media, banking, and e-commerce. Importantly, BACCS focuses on classifying behaviors rather than content, making it more suitable for identifying complex fraudulent activities.
The system evaluates clusters by analyzing the aggregate properties of the entities within them. These properties are typically boolean (true/false), and the system assesses the proportion of entities exhibiting a specific characteristic to determine the overall nature of the cluster. For example, a high percentage of newly created accounts within a cluster might indicate fraudulent activity. Based on predefined policies, BACCS identifies combinations of property ratios that suggest abusive behavior and determines the appropriate actions to mitigate the threat.
The BACCS framework offers several advantages:
- It enables the grouping of entities based on behavioral similarities, enabling the detection of coordinated attacks.
- It allows for the classification of clusters by defining relevant properties of the cluster members and applying custom policies to identify potential abuse.
- It supports automatic actions against clusters flagged as harmful, ensuring system integrity and enhancing protection against malicious activities.
This flexible and adaptive approach allows BACCS to continuously evolve, ensuring that it remains effective in addressing new and emerging forms of coordinated attacks across different platforms and industries.
Let’s understand more with the help of an analogy: Let’s say you have a wagon full of apples that you want to sell. All apples are put into bags before being loaded onto the wagon by multiple workers. Some of these workers don’t like you, and try to fill their bags with sour apples to mess with you. You need to identify any bag that might contain sour apples. To identify a sour apple you need to check if it is soft, the only problem is that some apples are naturally softer than others. You solve the problem of these malicious workers by opening each bag and picking out five apples, and you check if they are soft or not. If almost all the apples are soft it’s likely that the bag contains sour apples, and you put it to the side for further inspection later on. Once you’ve identified all the potential bags with a suspicious amount of softness you pour out their contents and pick out the healthy apples which are hard and throw away all the soft ones. You’ve now minimized the risk of your customers taking a bite of a sour apple.
BACCS operates in a similar manner; instead of apples, you have entities (e.g., user accounts). Instead of bad workers, you have malicious users, and instead of the bag of apples, you have entities grouped by common characteristics (e.g., similar account creation times). BACCS samples each group of entities and checks for signs of malicious behavior (e.g., a high rate of policy violations). If a group shows a high prevalence of these signs, it’s flagged for further investigation.
Just like checking the materials in the classroom, BACCS uses predefined signals (also referred to as properties) to assess the quality of entities within a cluster. If a cluster is found to be problematic, further actions can be taken to isolate or remove the malicious entities. This system is flexible and can adapt to new types of malicious behavior by adjusting the criteria for flagging clusters or by creating new types of clusters based on emerging patterns of abuse.
This analogy illustrates how BACCS helps maintain the integrity of the environment by proactively identifying and mitigating potential issues, ensuring a safer and more reliable space for all legitimate users.
The system offers numerous advantages:
- Better Precision: By clustering entities, BACCS provides strong evidence of coordination, enabling the creation of policies that would be too imprecise if applied to individual entities in isolation.
- Explainability: Unlike some machine learning techniques, the classifications made by BACCS are transparent and understandable. It is straightforward to trace and understand how a particular decision was made.
- Quick Response Time: Since BACCS operates on a rule-based system rather than relying on machine learning, there is no need for extensive model training. This results in faster response times, which is important for immediate issue resolution.
BACCS might be the right solution for your needs if you:
- Focus on classifying behavior rather than content: While many clusters in BACCS may be formed around content (e.g., images, email content, user phone numbers), the system itself does not classify content directly.
- Handle issues with a relatively high frequancy of occurance: BACCS employs a statistical approach that is most effective when the clusters contain a significant proportion of abusive entities. It may not be as effective for harmful events that sparsely occur but is more suited for highly prevalent problems such as spam.
- Deal with coordinated or similar behavior: The clustering signal primarily indicates coordinated or similar behavior, making BACCS particularly useful for addressing these types of issues.
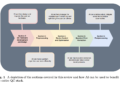
Here’s how you can incorporate BACCS framework in a real production system:
- When entities engage in activities on a platform, you build an observation layer to capture this activity and convert it into events. These events can then be monitored by a system designed for cluster analysis and actioning.
- Based on these events, the system needs to group entities into clusters using various attributes — for example, all users posting from the same IP address are grouped into one cluster. These clusters should then be forwarded for further classification.
- During the classification process, the system needs to compute a set of specialized boolean signals for a sample of the cluster members. An example of such a signal could be whether the account age is less than a day. The system then aggregates these signal counts for the cluster, such as determining that, in a sample of 100 users, 80 have an account age of less than one day.
- These aggregated signal counts should be evaluated against policies that determine whether a cluster appears to be anomalous and what actions should be taken if it is. For instance, a policy might state that if more than 60% of the members in an IP cluster have an account age of less than a day, these members should undergo further verification.
- If a policy identifies a cluster as anomalous, the system should identify all members of the cluster exhibiting the signals that triggered the policy (e.g., all members with an account age of less than one day).
- The system should then direct all such users to the appropriate action framework, implementing the action specified by the policy (e.g., further verification or blocking their account).
Typically, the entire process from activity of an entity to the application of an action is completed within several minutes. It’s also crucial to recognize that while this system provides a framework and infrastructure for cluster classification, clients/organizations need to supply their own cluster definitions, properties, and policies tailored to their specific domain.
Let’s look at the example where we try to mitigate spam via clustering users by ip when they send an email, and blocking them if >60% of the cluster members have account age less than a day.
Members can already be present in the clusters. A re-classification of a cluster can be triggered when it reaches a certain size or has enough changes since the previous classification.
When selecting clustering criteria and defining properties for users, the goal is to identify patterns or behaviors that align with the specific risks or activities you’re trying to detect. For instance, if you’re working on detecting fraudulent behavior or coordinated attacks, the criteria should capture traits that are often shared by malicious actors. Here are some factors to consider when picking clustering criteria and defining user properties:
The clustering criteria you choose should revolve around characteristics that represent behavior likely to signal risk. These characteristics could include:
- Time-Based Patterns: For example, grouping users by account creation times or the frequency of actions in a given time period can help detect spikes in activity that may be indicative of coordinated behavior.
- Geolocation or IP Addresses: Clustering users by their IP address or geographical location can be especially effective in detecting coordinated actions, such as multiple fraudulent logins or content submissions originating from the same region.
- Content Similarity: In cases like misinformation or spam detection, clustering by the similarity of content (e.g., similar text in posts/emails) can identify suspiciously coordinated efforts.
- Behavioral Metrics: Characteristics like the number of transactions made, average session time, or the types of interactions with the platform (e.g., likes, comments, or clicks) can indicate unusual patterns when grouped together.
The key is to choose criteria that are not just correlated with benign user behavior but also distinct enough to isolate risky patterns, which will lead to more effective clustering.
Defining User Properties
Once you’ve chosen the criteria for clustering, defining meaningful properties for the users within each cluster is critical. These properties should be measurable signals that can help you assess the likelihood of harmful behavior. Common properties include:
- Account Age: Newly created accounts tend to have a higher risk of being involved in malicious activities, so a property like “Account Age < 1 Day” can flag suspicious behavior.
- Connection Density: For social media platforms, properties like the number of connections or interactions between accounts within a cluster can signal abnormal behavior.
- Transaction Amounts: In cases of financial fraud, the average transaction size or the frequency of high-value transactions can be key properties to flag risky clusters.
Each property should be clearly linked to a behavior that could indicate either legitimate use or potential abuse. Importantly, properties should be boolean or numerical values that allow for easy aggregation and comparison across the cluster.
Another advanced strategy is using a machine learning classifier’s output as a property, but with an adjusted threshold. Normally, you would set a high threshold for classifying harmful behavior to avoid false positives. However, when combined with clustering, you can afford to lower this threshold because the clustering itself acts as an additional signal to reinforce the property.
Let’s consider that there is a model x, that catches scam and disables email accounts that have model x score > 0.95. Assume this model is already live in production and is disabling bad email accounts at threshold 0.95 with 100% precision. We have to increase the recall of this model, without impacting the precision.
- First, we need to define clusters that can group coordinated activity together. Let’s say we know that there’s a coordinated activity going on, where bad actors are using the same subject line but different email ids to send scammy emails. So using BACCS, we will form clusters of email accounts that all have the same subject name in their sent emails.
- Next, we need to lower the raw model threshold and define a BACCS property. We will now integrate model x into our production detection infra and create property using lowered model threshold, say 0.75. This property will have a value of “True” for an email account that has model x score >= 0.75.
- Then we’ll define the anomaly threshold and say, if 50% of entities in the campaign name clusters have this property, then classify the clusters as bad and take down ad accounts that have this property as True.
So we essentially lowered the model’s threshold and started disabling entities in particular clusters at significantly lower threshold than what the model is currently enforcing at, and yet can be sure the precision of enforcement does not drop and we get an increase in recall. Let’s understand how –
Supposed we have 6 entities that have the same subject line, that have model x score as follows:
If we use the raw model score (0.95) we would have disabled 2/6 email accounts only.
If we cluster entities on subject line text, and define a policy to find bad clusters having greater than 50% entities with model x score >= 0.75, we would have taken down all these accounts:
So we increased the recall of enforcement from 33% to 83%. Essentially, even if individual behaviors seem less risky, the fact that they are part of a suspicious cluster elevates their importance. This combination provides a strong signal for detecting harmful activity while minimizing the chances of false positives.
By lowering the threshold, you allow the clustering process to surface patterns that might otherwise be missed if you relied on classification alone. This approach takes advantage of both the granular insights from machine learning models and the broader behavioral patterns that clustering can identify. Together, they create a more robust system for detecting and mitigating risks and catching many more entities while still keeping a lower false positive rate.
Clustering techniques remain an important method for detecting coordinated attacks and ensuring system safety, particularly on platforms more prone to fraud, abuse or other malicious activities. By grouping similar behaviors into clusters and applying policies to take down bad entities from such clusters, we can detect and mitigate harmful activity and ensure a safer digital ecosystem for all users. Choosing more advanced embedding-based approaches helps represent complex user behavioral patterns better than manual methods of similarity detection measures.
As we continue advancing our security protocols, frameworks like BACCS play a crucial role in taking down large coordinated attacks. The integration of clustering with behavior-based policies allows for dynamic adaptation, enabling us to respond swiftly to new forms of abuse while reinforcing trust and safety across platforms.
In the future, there is a big opportunity for further research and exploration into complementary techniques that could enhance clustering’s effectiveness. Techniques such as graph-based analysis for mapping complex relationships between entities could be integrated with clustering to offer even higher precision in threat detection. Moreover, hybrid approaches that combine clustering with machine learning classification can be a very effective approach for detecting malicious activities at higher recall and lower false positive rate. Exploring these methods, along with continuous refinement of current methods, will ensure that we remain resilient against the evolving landscape of digital threats.





{kind=link}