
artificial intelligence has made notable progress with the development of large language models (LLMs), which have significantly impacted several domains, including natural language processing, reasoning, and even coding tasks. As LLMs become more powerful, they require sophisticated methods to optimize their performance during inference. Inference timing techniques and strategies used to improve the quality of answers generated by these models at runtime have become crucial. However, the research community has yet to establish best practices for integrating these techniques into a cohesive system.
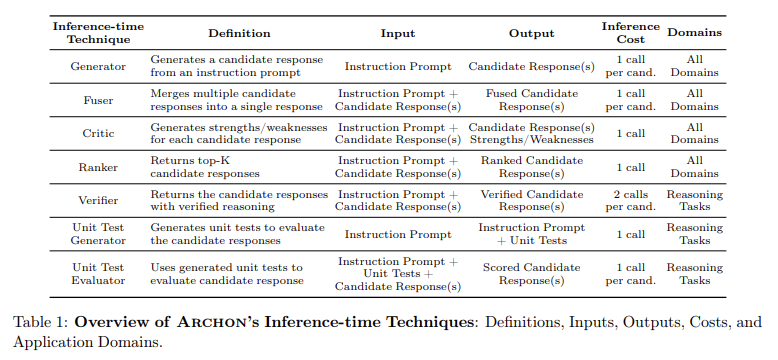
A central challenge to improving LLM performance is determining which inference timing techniques produce the best results for different tasks. The problem is compounded by the wide variety of functions, such as instruction following, reasoning, and coding, that can benefit from various combinations of inference timing techniques. Additionally, understanding the complex interactions between techniques such as assembly, resampling, sorting, merging, and verification is crucial to maximizing performance. Researchers need a robust system that can efficiently explore the extensive design space of possible combinations and optimize these architectures according to the task and computational constraints.
Traditional methods for optimizing inference time have focused on applying individual techniques to LLMs. For example, generation ensemble involves querying multiple models simultaneously and selecting the best answer, while repeated sampling involves querying a single model multiple times. These techniques have shown promise, but their independent application often leads to limited improvements. Frameworks such as Mixture-of-Agents (MoA) and LeanStar have attempted to integrate multiple techniques, but still face challenges in generalization and performance on various tasks. Therefore, there is a growing demand for a modular and automated approach to building optimized LLM systems.
Researchers at Stanford University and the University of Washington have developed Archona modular framework designed to automate LLM architecture search using inference-time techniques. The Archon framework leverages diverse LLM and inference timing methods, combining them into a cohesive system that outperforms traditional models. Instead of relying on a single LLM queried once, Archon dynamically selects, combines, and stacks layers of techniques to optimize performance for specific benchmarks. By treating the problem as a hyperparameter optimization task, the framework can identify optimal architectures that maximize accuracy, latency, and cost-effectiveness for a given computing budget.
The Archon framework is structured as a multi-layer system where each layer performs a different inference timing technique. For example, the first layer could generate multiple candidate responses using a set of LLMs, while subsequent layers apply classification, fusion, or verification techniques to refine these responses. The framework uses Bayesian optimization algorithms to search for potential configurations and select the most effective one for a target benchmark. This modular design allows Archon to outperform high-performance models such as the GPT-4o and Claude 3.5 Sonnet by an average of 15.1 percentage points across a wide range of tasks.
Archon's performance was evaluated on several benchmarks including MT-Bench, Arena-Hard-Auto, AlpacaEval 2.0, MixEval, MixEval Hard, MATH, and CodeContests. The results were compelling: Archon architectures demonstrated an average accuracy increase of 11.2 percentage points using open source models and 15.1 percentage points using a combination of open and closed source models. On coding tasks, the framework achieved a 56% improvement in Pass@1 scores, increasing accuracy from 17.9% to 29.3% by generating and evaluating unit tests. Even when limited to open source models, Archon outperformed state-of-the-art single-call models by 11.2 percentage points, highlighting the effectiveness of its layered approach.
Key results show that Archon achieves state-of-the-art performance in multiple domains by integrating multiple inference timing techniques. For the instruction-following tasks, adding numerous generation, classification, and fusion layers significantly improved the quality of the answers. Archon excelled in reasoning tasks like MixEval and MATH by incorporating unit testing and verification methods, resulting in an average increase of 3.7 to 8.9 percentage points when applying task-specific architectures. The framework combined extensive generation sampling and unit testing to produce accurate and reliable results for coding challenges.
Key findings from the Archon investigation:
- Increased performance: Archon achieves an average accuracy increase of 15.1 percentage points across multiple benchmarks, outperforming state-of-the-art models such as GPT-4o and Claude 3.5 Sonnet.
- Various applications: The framework excels at instruction following, reasoning, and coding tasks, demonstrating versatility.
- Effective inference timing techniques: Archon provides superior performance in all evaluated scenarios by combining techniques such as assembly, merging, sorting, and verification.
- Improved coding accuracy: Achieved a 56% increase in the accuracy of coding tasks by leveraging unit test generation and evaluation methods.
- Scalability and modularity: The framework's modular design allows it to easily adapt to new tasks and configurations, making it a robust tool for LLM optimization.

In conclusion, Archon addresses the critical need for an automated system that optimizes LLMs at the time of inference by effectively combining multiple techniques. This research provides a practical solution to the complexities of inference-time architecture design, making it easier for developers to create high-performance LLM systems tailored to specific tasks. The Archon framework sets a new standard for optimizing LLMs. It offers a systematic, automated approach to inference-time architecture search, demonstrating its ability to achieve top-notch results across multiple benchmarks.
look at the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
(Next Event: Oct 17, 202) RetrieveX – The GenAI Data Recovery Conference (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}