
Introducción
El desarrollo de la IA está logrando avances significativos, particularmente con el auge de los modelos de lenguajes grandes (LLM) y las aplicaciones de generación aumentada de recuperación (RAG). A medida que los desarrolladores se esfuerzan por crear sistemas de IA más robustos y confiables, las herramientas que facilitan la evaluación y el monitoreo se han vuelto esenciales. Una de esas herramientas es Opik, una plataforma de código abierto diseñada para agilizar la evaluación, prueba y seguimiento de aplicaciones LLM. Este artículo evaluará y monitoreará las aplicaciones LLM y RAG con Opik.

Descripción general
- Opik es una plataforma de código abierto para evaluar y monitorear aplicaciones LLM desarrolladas por Comet.
- Permite registrar y rastrear las interacciones de LLM, lo que ayuda a los desarrolladores a identificar y solucionar problemas en tiempo real.
- La evaluación de los LLM es crucial para garantizar la precisión, la relevancia y evitar alucinaciones en los resultados del modelo.
- Opik admite la integración con marcos como Pytest, lo que facilita la ejecución de canales de evaluación reutilizables.
- La plataforma ofrece Python SDK y una interfaz de usuario, que atiende a una amplia gama de preferencias de usuario.
- Opik se puede utilizar con Ragas para monitorear y evaluar sistemas RAG calculando métricas como la relevancia de las respuestas y la precisión del contexto.
¿Qué es Opik?
Opik es una plataforma de seguimiento y evaluación de LLM de código abierto de Comet. Le permite registrar, revisar y evaluar sus seguimientos de LLM en desarrollo y producción. También puede utilizar la plataforma y nuestro LLM como jueces evaluadores para identificar y solucionar problemas con su solicitud de LLM.

¿Por qué es importante la evaluación?
evaluando LLM y los sistemas RAG van más allá de las pruebas de precisión. Incluye factores como la relevancia de las respuestas, la corrección, la precisión del contexto y evitar las alucinaciones. Herramientas como Opik y Ragas permiten a los equipos:
- Seguimiento del desempeño del LLM en tiempo real, identificando cuellos de botella y áreas donde el sistema puede generar resultados incorrectos o irrelevantes.
- Evaluar tuberías RAGasegurando que el sistema de recuperación proporcione información precisa, relevante y completa para las tareas en cuestión.
Características clave de Opik
Estas son las características clave de Opik:
1. Evaluación de LLM de principio a fin
- opik rastrea automáticamente todo el proceso de LLM, proporcionando información sobre cada componente de la aplicación. Esta capacidad es crucial para depurar y comprender cómo interactúan las diferentes partes del sistema1.
- Admite evaluaciones complejas listas para usar, lo que permite a los desarrolladores implementar métricas que evalúan el rendimiento del modelo rápidamente.
2. Monitoreo en tiempo real
- La plataforma permite el monitoreo en tiempo real de las aplicaciones LLM, lo que ayuda a identificar comportamientos no deseados y problemas de rendimiento a medida que ocurren.
- Los desarrolladores pueden registrar interacciones con sus aplicaciones LLM y revisar estos registros para mejorar la comprensión y el rendimiento continuamente24.
3. Integración con marcos de prueba
- Opik se integra perfectamente con marcos de prueba populares como Pytest, lo que permite “pruebas unitarias modelo”. Esta característica facilita la creación de canales de evaluación reutilizables que se pueden aplicar en varios aplicaciones.
- Los desarrolladores pueden almacenar conjuntos de datos de evaluación dentro de la plataforma y ejecutar evaluaciones utilizando métricas integradas para la detección de alucinaciones y otras medidas importantes.
4. Interfaz fácil de usar
- La plataforma ofrece tanto una Pitón SDK para desarrolladores que prefieren la codificación y una interfaz de usuario para quienes prefieren la interacción gráfica. Este doble enfoque lo hace accesible a una gama más amplia de usuarios.
Primeros pasos con Opik
Opik está diseñado para integrarse perfectamente con sistemas LLM como los modelos GPT de OpenAI. Esto le permite registrar seguimientos, evaluar resultados y monitorear el rendimiento en cada paso del proceso. He aquí cómo empezar.
Seguimientos de registros para llamadas de OpenAI LLM: entorno de configuración
- Crear una cuenta Opik: Dirígete a Cometa y crear una cuenta. Necesitará una clave API para registrar seguimientos.
- Registro de seguimientos para llamadas OpenAI LLM: Opik le permite registrar seguimientos para Abierto ai llamadas envolviéndolas con la función track_openai. Esto garantiza que se registre cada interacción con el LLM, lo que permite un análisis detallado.
Instalación
Puedes instalar Opik usando pip:
!pip install --upgrade --quiet opik openai
import opik
opik.configure(use_local=False)
import os
import getpass
if "OPENAI_API_KEY" not in os.environ:
os.environ("OPENAI_API_KEY") = getpass.getpass("Enter your OpenAI API key: ")Opik se integra con OpenAI para proporcionar una forma sencilla de registrar seguimientos de todas las llamadas de OpenAI LLM.
Comet proporciona una versión alojada de la plataforma Opik. Puede crear una cuenta y obtener su clave API.
Registro de seguimientos para llamadas de OpenAI LLM: registro de seguimientos
from opik.integrations.openai import track_openai
from openai import OpenAI
os.environ("OPIK_PROJECT_NAME") = "openai-integration-demo"
client = OpenAI()
openai_client = track_openai(client)
prompt = """
Write a short two sentence story about Opik.
"""
completion = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=(
{"role": "user", "content": prompt}
)
)
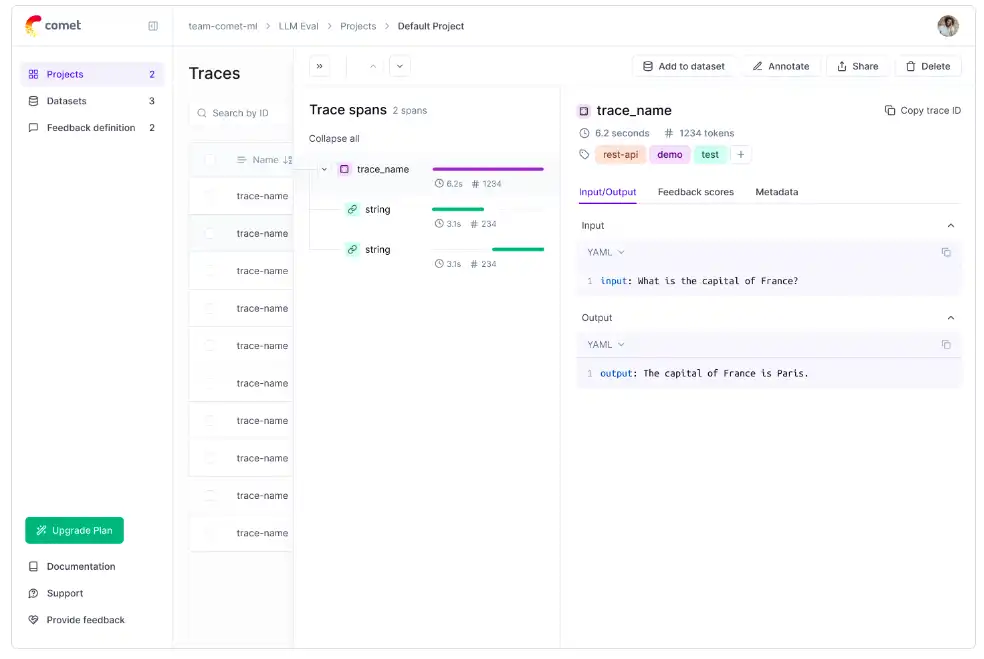
print(completion.choices(0).message.content)Para registrar seguimientos en Opik, necesitamos envolver nuestras llamadas de OpenAI con la función track_openai.
Este ejemplo muestra cómo configurar un cliente OpenAI incluido en Opik para el registro de seguimiento y crear una solicitud de finalización de chat con un simple mensaje.
Los mensajes de aviso y respuesta se registran automáticamente en OPik y se pueden ver en la interfaz de usuario.
Registrar seguimientos para llamadas de OpenAI LLM: registro de seguimientos de varios pasos
from opik import track
from opik.integrations.openai import track_openai
from openai import OpenAI
os.environ("OPIK_PROJECT_NAME") = "openai-integration-demo"
client = OpenAI()
openai_client = track_openai(client)
@track
def generate_story(prompt):
res = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=(
{"role": "user", "content": prompt}
)
)
return res.choices(0).message.content
@track
def generate_topic():
prompt = "Generate a topic for a story about Opik."
res = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=(
{"role": "user", "content": prompt}
)
)
return res.choices(0).message.content
@track
def generate_opik_story():
topic = generate_topic()
story = generate_story(topic)
return story
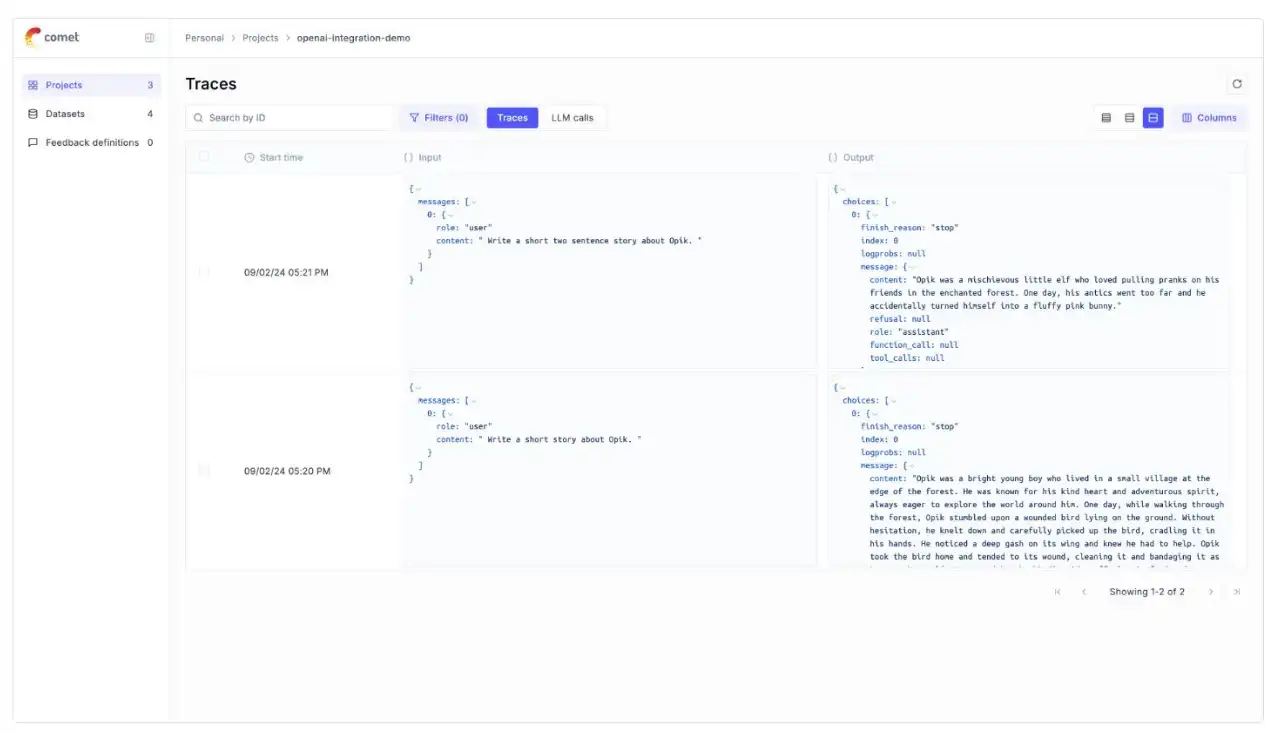
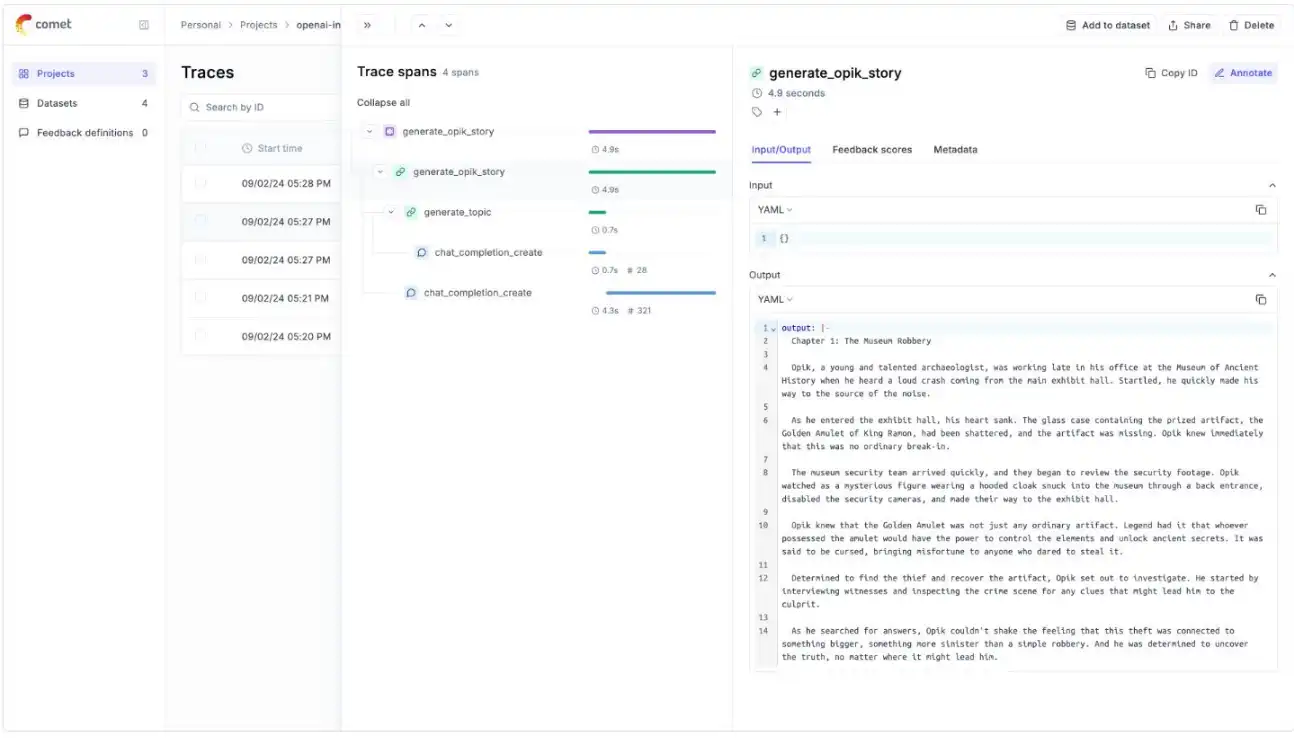
generate_opik_story()Si tiene varios pasos en su proceso de LLM, puede usar el decorador de pistas para registrar los seguimientos de cada paso.
Si se llama a OpenAI dentro de uno de estos pasos, la llamada LLM se asociará con ese paso correspondiente.
Este ejemplo demuestra cómo registrar seguimientos de varios pasos de un proceso utilizando el decorador @track, capturando el flujo desde la generación del tema hasta la generación de la historia.
Opik con Ragas para monitorear y evaluar RAG Systems
!pip install --quiet --upgrade opik ragas
import opik
opik.configure(use_local=False)- Aquí hay dos formas principales de usar Opik con Ragas:
- Uso de métricas de Ragas para puntuar trazas.
- Usar la función de evaluación de Ragas para calificar un conjunto de datos.
- Cometa proporciona una versión alojada de la plataforma Opik. Puede crear una cuenta y obtenga su clave API desde allí.
Ejemplo para configurar una clave API:
import os
import getpass
if "OPENAI_API_KEY" not in os.environ:
os.environ("OPENAI_API_KEY") = getpass.getpass("Enter your OpenAI API key: ")Creación de una tubería RAG simple utilizando métricas Ragas
Ragas proporciona un conjunto de métricas que se pueden utilizar para evaluar la calidad de una tubería RAG, que incluyen, entre otras: relevancia_respuesta, similitud_respuesta, corrección_respuesta, precisión_contexto, recuperación_contexto, recuperación_entidad_contexto, puntuación_summarización.
Puede encontrar una lista completa de métricas en la Documentación ragas.
Estas métricas se pueden calcular sobre la marcha y registrar en trazas o intervalos en Opik. Para este ejemplo, comenzaremos creando una canalización RAG simple y luego la calificaremos usando la métrica respuesta_relevancia.
# Import the metric
from ragas.metrics import AnswerRelevancy
# Import some additional dependencies
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
# Initialize the Ragas metric
llm = LangchainLLMWrapper(ChatOpenAI())
emb = LangchainEmbeddingsWrapper(OpenAIEmbeddings())
answer_relevancy_metric = AnswerRelevancy(llm=llm, embeddings=emb)Para utilizar la métrica Ragas sin utilizar la función de evaluación, debe inicializarla con un objeto RunConfig y un proveedor LLM. Para este ejemplo, usaremos LangChain como proveedor de LLM con el rastreador Opik habilitado.
Primero comenzaremos inicializando la métrica Ragas.
# Run this cell first if you are running this in a Jupyter notebook
import nest_asyncio
nest_asyncio.apply()
import asyncio
from ragas.integrations.opik import OpikTracer
from ragas.dataset_schema import SingleTurnSample
import os
os.environ("OPIK_PROJECT_NAME") = "ragas-integration"
# Define the scoring function
def compute_metric(metric, row):
row = SingleTurnSample(**row)
opik_tracer = OpikTracer(tags=("ragas"))
async def get_score(opik_tracer, metric, row):
score = await metric.single_turn_ascore(row, callbacks=(opik_tracer))
return score
# Run the async function using the current event loop
loop = asyncio.get_event_loop()
result = loop.run_until_complete(get_score(opik_tracer, metric, row))
return result- Una vez que se inicializa la métrica, puede usarla para calificar una pregunta de muestra.
- Para hacer eso, primero necesitamos definir una función de puntuación que pueda tomar un registro de datos con entrada, contexto, etc., y calificarlo usando la métrica que definimos anteriormente.
- Dado que la puntuación de la métrica se realiza de forma asincrónica, es necesario utilizar la biblioteca asyncio para ejecutar la función de puntuación.
# Score a simple example
row = {
"user_input": "What is the capital of France?",
"response": "Paris",
"retrieved_contexts": ("Paris is the capital of France.", "Paris is in France."),
}
score = compute_metric(answer_relevancy_metric, row)
print("Answer Relevancy score:", score)Si ahora navega a Opik, podrá ver que se ha creado un nuevo seguimiento en el proyecto Proyecto predeterminado.
Puede utilizar la función update_current_trace para puntuar seguimientos.
Este método tiene la ventaja de agregar el intervalo de puntuación al seguimiento, lo que permite un examen más profundo del proceso RAG. Sin embargo, debido a que calcula la métrica de Ragas de forma sincrónica, es posible que no sea apropiado para su uso en escenarios de producción.
from opik import track, opik_context
@track
def retrieve_contexts(question):
# Define the retrieval function, in this case we will hard code the contexts
return ("Paris is the capital of France.", "Paris is in France.")
@track
def answer_question(question, contexts):
# Define the answer function, in this case we will hard code the answer
return "Paris"
@track(name="Compute Ragas metric score", capture_input=False)
def compute_rag_score(answer_relevancy_metric, question, answer, contexts):
# Define the score function
row = {"user_input": question, "response": answer, "retrieved_contexts": contexts}
score = compute_metric(answer_relevancy_metric, row)
return score
@track
def rag_pipeline(question):
# Define the pipeline
contexts = retrieve_contexts(question)
answer = answer_question(question, contexts)
score = compute_rag_score(answer_relevancy_metric, question, answer, contexts)
opik_context.update_current_trace(
feedback_scores=({"name": "answer_relevancy", "value": round(score, 4)})
)
return answer
rag_pipeline("What is the capital of France?")Evaluación de conjuntos de datos
from datasets import load_dataset
from ragas.metrics import context_precision, answer_relevancy, faithfulness
from ragas import evaluate
from ragas.integrations.opik import OpikTracer
fiqa_eval = load_dataset("explodinggradients/fiqa", "ragas_eval")
# Reformat the dataset to match the schema expected by the Ragas evaluate function
dataset = fiqa_eval("baseline").select(range(3))
dataset = dataset.map(
lambda x: {
"user_input": x("question"),
"reference": x("ground_truths")(0),
"retrieved_contexts": x("contexts"),
}
)
opik_tracer_eval = OpikTracer(tags=("ragas_eval"), metadata={"evaluation_run": True})
result = evaluate(
dataset,
metrics=(context_precision, faithfulness, answer_relevancy),
callbacks=(opik_tracer_eval),
)
print(result)Si desea evaluar un conjunto de datos, puede utilizar la función de evaluación de Raga. Cuando se invoca esta función, la biblioteca Ragas calcula las métricas para cada fila del conjunto de datos y devuelve un resumen de los resultados.
Utilice la devolución de llamada de OpikTracer para registrar los resultados de la evaluación en la plataforma Opik:
Evaluación de solicitudes de LLM con Opik
Evaluar su solicitud de LLM le permite tener confianza en su desempeño. Este conjunto de evaluaciones suele realizarse tanto durante el desarrollo como como parte de las pruebas de una aplicación.
La evaluación se realiza en cinco pasos:
- Agregue seguimiento a su solicitud de LLM.
- Definir la tarea de evaluación.
- Elija el conjunto de datos en el que le gustaría evaluar su aplicación.
- Elija las métricas con las que le gustaría evaluar su aplicación.
- Cree y ejecute el experimento de evaluación.
Agregue seguimiento a su solicitud de LLM.
from opik import track
from opik.integrations.openai import track_openai
import openai
openai_client = track_openai(openai.OpenAI())
# This method is the LLM application that you want to evaluate
# Typically, this is not updated when creating evaluations
@track
def your_llm_application(input: str) -> str:
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=({"role": "user", "content": input}),
)
return response.choices(0).message.content
@track
def your_context_retriever(input: str) -> str:
return ("...")- Si bien no es obligatorio, se recomienda agregar seguimiento a su solicitud de LLM. Esto permite una visibilidad completa de cada ejecución de evaluación.
- El ejemplo demuestra el uso de una combinación del decorador de pistas y la función track_openai para rastrear la aplicación LLM.
Esto garantiza que las respuestas de los procesos de recuperación del modelo y del contexto sean rastreadas durante la evaluación.
Definir la tarea de evaluación
def evaluation_task(x: DatasetItem):
return {
"input": x.input('user_question'),
"output": your_llm_application(x.input('user_question')),
"context": your_context_retriever(x.input('user_question'))
}- Puede definir la tarea de evaluación después de agregar instrumentación a su aplicación LLM.
- La tarea de evaluación toma un elemento del conjunto de datos como entrada y devuelve un diccionario. El diccionario incluye claves que coinciden con los parámetros esperados por las métricas que está utilizando.
- En este ejemplo, la función evaluación_task recupera la entrada del conjunto de datos (x.input('user_question')), la ejecuta a través de la aplicación LLM y recupera el contexto utilizando el método your_context_retriever.
Este método se utiliza para estructurar los datos de evaluación para su posterior análisis.
Elija los datos de evaluación
Si ya ha creado un conjunto de datos:
Puede utilizar la función Opik.get_dataset para recuperarlo:
Ejemplo de código:
from opik import Opik
client = Opik()
dataset = client.get_dataset(name="your-dataset-name")Si aún no tienes un conjunto de datos:
Puedes crear uno usando la función Opik.create_dataset:
Ejemplo de código:
from opik import Opik
from opik.datasets import DatasetItem
client = Opik()
dataset = client.create_dataset(name="your-dataset-name")
dataset.insert((
DatasetItem(input="Hello, world!", expected_output="Hello, world!"),
DatasetItem(input="What is the capital of France?", expected_output="Paris"),
))- Para recuperar un conjunto de datos existente, utilice get_dataset con el nombre del conjunto de datos.
- Para crear un nuevo conjunto de datos, use create_dataset y puede insertar elementos de datos en el conjunto de datos con la función de inserción.
Elija las métricas de evaluación
En el mismo experimento de evaluación, puede utilizar varias métricas para evaluar su aplicación:
from opik.evaluation.metrics import Equals, Hallucination
equals_metric= Equals()
hallucination_metric=Hallucination()Opik proporciona un conjunto de métricas de evaluación integradas entre las que puede elegir. Estos se dividen en dos categorías principales:
- Métricas heurísticas: estas métricas que son de naturaleza determinista, por ejemplo, igualan o contienen
- LLM como juez: estas métricas utilizan un LLM para juzgar la calidad del resultado; normalmente se utilizan para detectar alucinaciones o relevancia del contexto.
Ejecute la evaluación
evaluation= evaluate(experiment_name=”My experiment”,dataset=dataset,task=evaluation_task,scoring_metrics=(hallucination_metric),experiment_config={”model”: Model})Ahora que tenemos la tarea que queremos evaluar, el conjunto de datos para evaluar, las métricas con las que queremos evaluar, podemos ejecutar la evaluación.
Conclusión
Opik representa un avance significativo en las herramientas disponibles para evaluar y monitorear solicitudes de LLM. Los desarrolladores pueden crear con confianza sistemas de inteligencia artificial confiables al ofrecer funciones integrales para rastrear, evaluar y depurar LLM dentro de un marco fácil de usar. A medida que avance la tecnología de IA, herramientas como Opik serán fundamentales para garantizar que estos sistemas funcionen de manera efectiva y confiable en aplicaciones del mundo real.
Además, si está buscando un curso de IA generativa en línea, explore: Programa GenAI Pinnacle
Preguntas frecuentes
Respuesta. Opik es una plataforma de código abierto desarrollada por Comet para evaluar y monitorear aplicaciones LLM (Large Language Model). Ayuda a los desarrolladores a registrar, rastrear y evaluar los LLM para identificar y solucionar problemas tanto en entornos de desarrollo como de producción.
Respuesta. La evaluación de los sistemas LLM y RAG (recuperación-generación aumentada) garantiza algo más que precisión. Cubre la relevancia de las respuestas, la precisión del contexto y la prevención de alucinaciones, lo que ayuda a realizar un seguimiento del rendimiento, detectar problemas y mejorar la calidad de los resultados.
Respuesta. Opik ofrece características como evaluación LLM de un extremo a otro, monitoreo en tiempo real, integración perfecta con marcos de prueba como Pytest y una interfaz fácil de usar, que admite tanto el SDK de Python como la interacción gráfica.
Respuesta. Opik le permite registrar seguimientos de llamadas de OpenAI LLM envolviéndolos con la función track_openai. Esto registra cada interacción para un análisis más profundo y una depuración del comportamiento de LLM, proporcionando información sobre cómo responden los modelos a diferentes indicaciones.
Respuesta. Opik se integra con Ragas, lo que permite a los usuarios evaluar y monitorear los sistemas RAG. Métricas como la relevancia de las respuestas y la precisión del contexto se pueden calcular sobre la marcha y registrarse en Opik, lo que ayuda a rastrear y mejorar el rendimiento del sistema RAG.

Hola, soy Janvi Kumari y actualmente soy asociado de Insights en Analytics Vidhya y me apasiona aprovechar los datos para obtener conocimientos e innovación. Curioso, motivado y con ganas de aprender. Si desea conectarse, no dude en comunicarse conmigo en LinkedIn





