
Generative ai models can produce information on a wide range of topics, but their application brings new challenges. These include maintaining relevance, avoiding toxic content, protecting sensitive information like personally identifiable information (PII), and mitigating hallucinations. Although foundation models (FMs) on amazon Bedrock offer built-in protections, these are often model-specific and might not fully align with an organization’s use cases or responsible ai principles. As a result, developers frequently need to implement additional customized safety and privacy controls. This need becomes more pronounced when organizations use multiple FMs across different use cases, because maintaining consistent safeguards is crucial for accelerating development cycles and implementing a uniform approach to responsible ai.
In April 2024, we announced the general availability of amazon Bedrock Guardrails to help you introduce safeguards, prevent harmful content, and evaluate models against key safety criteria. With amazon Bedrock Guardrails, you can implement safeguards in your generative ai applications that are customized to your use cases and responsible ai policies. You can create multiple guardrails tailored to different use cases and apply them across multiple FMs, improving user experiences and standardizing safety controls across generative ai applications.
In addition, to enable safeguarding applications using different FMs, amazon Bedrock Guardrails now supports the ApplyGuardrail API to evaluate user inputs and model responses for custom and third-party FMs available outside of amazon Bedrock. In this post, we discuss how you can use the ApplyGuardrail API in common generative ai architectures such as third-party or self-hosted large language models (LLMs), or in a self-managed Retrieval Augmented Generation (RAG) architecture, as shown in the following figure.
<img class="alignnone wp-image-86984" src="https://technicalterrence.com/wp-content/uploads/2024/10/Implement-model-independent-safety-measures-with-Amazon-Bedrock-Guardrails.png" alt="Overview of topics that amazon Bedrock Guardrails filter” width=”1396″ height=”808″/>
Solution overview
For this post, we create a guardrail that stops our FM from providing fiduciary advice. The full list of configurations for the guardrail is available in the amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/bedrock_guardrails_apply_guardrail_api.ipynb” target=”_blank” rel=”noopener”>GitHub repo. You can modify the code as needed for your use case.
Prerequisites
Make sure you have the correct AWS Identity and Access Management (IAM) permissions to use amazon Bedrock Guardrails. For instructions, see Set up permissions to use guardrails.
Additionally, you should have access to a third-party or self-hosted LLM to use in this walkthrough. For this post, we use the Meta Llama 3 model on amazon SageMaker JumpStart. For more details, see AWS Managed Policies for SageMaker projects and JumpStart.
You can create a guardrail using the amazon Bedrock console, infrastructure as code (IaC), or the API. For the example code to create the guardrail, see the amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/guardrails-api.ipynb” target=”_blank” rel=”noopener”>GitHub repo. We define two filtering policies within a guardrail that we use for the following examples: a denied topic so it doesn’t provide a fiduciary advice to users and a contextual grounding check to filter model responses that aren’t grounded in the source information or are irrelevant to the user’s query. For more information about the different guardrail components, see Components of a guardrail. Make sure you’ve created a guardrail before moving forward.
Using the ApplyGuardrail API
The ApplyGuardrail API allows you to invoke a guardrail regardless of the model used. The guardrail is applied at the text parameter, as demonstrated in the following code:
For this example, we apply the guardrail to the entire input from the user. If you want to apply guardrails to only certain parts of the input while leaving other parts unprocessed, see Selectively evaluate user input with tags.
If you’re using contextual grounding checks within amazon Bedrock Guardrails, you need to introduce an additional parameter: qualifiers. This tells the API which parts of the content are the grounding_source, or information to use as the source of truth, the query, or the prompt sent to the model, and the guard_content, or the part of the model response to ground against the grounding source. Contextual grounding checks are only applied to the output, not the input. See the following code:
The final required components are the guardrailIdentifier and the guardrailVersion of the guardrail you want to use, and the source, which indicates whether the text being analyzed is a prompt to a model or a response from the model. This is demonstrated in the following code using Boto3; the full code example is available in the amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/bedrock_guardrails_apply_guardrail_api.ipynb” target=”_blank” rel=”noopener”>GitHub repo:
The response of the API provides the following details:
- If the guardrail intervened.
- Why the guardrail intervened.
- The consumption utilized for the request. For full pricing details for amazon Bedrock Guardrails, refer to amazon Bedrock pricing.
The following response shows a guardrail intervening because of denied topics:
The following response shows a guardrail intervening because of contextual grounding checks:
From the response to the first request, you can observe that the guardrail intervened so it wouldn’t provide a fiduciary advice to a user who asked for a recommendation of a financial product. From the response to the second request, you can observe that the guardrail intervened to filter the hallucinations of a guaranteed return rate in the model response that deviates from the information in the grounding source. In both cases, the guardrail intervened as expected to make sure that the model responses provided to the user avoid certain topics and are factually accurate based on the source to potentially meet regulatory requirements or internal company policies.
Using the ApplyGuardrail API with a self-hosted LLM
A common use case for the ApplyGuardrail API is in conjunction with an LLM from a third-party provider or a model that you self-host. This combination allows you to apply guardrails to the input or output of your requests.
The general flow includes the following steps:
- Receive an input for your model.
- Apply the guardrail to this input using the
ApplyGuardrailAPI. - If the input passes the guardrail, send it to your model for inference.
- Receive the output from your model.
- Apply the guardrail to your output.
- If the output passes the guardrail, return the final output.
- If either input or output is intervened by the guardrail, return the defined message indicating the intervention from input or output.
This workflow is demonstrated in the following diagram.
See the provided amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/bedrock_guardrails_apply_guardrail_api.ipynb” target=”_blank” rel=”noopener”>code example to see an implementation of the workflow.
We use the Meta-Llama-3-8B model hosted on an amazon SageMaker endpoint. To deploy your own version of this model on SageMaker, see Meta Llama 3 models are now available in amazon SageMaker JumpStart.
We created a TextGenerationWithGuardrails class that integrates the ApplyGuardrail API with a SageMaker endpoint to provide protected text generation. This class includes the following key methods:
generate_text– Calls our LLM through a SageMaker endpoint to generate text based on the input.analyze_text– A core method that applies our guardrail using theApplyGuardrailAPI. It interprets the API response to determine if the guardrail passed or intervened.analyze_promptandanalyze_output– These methods useanalyze_textto apply our guardrail to the input prompt and generated output, respectively. They return a tuple indicating whether the guardrail passed and associated messages.
The class implements the workflow in the preceding diagram. It works as follows:
- It checks the input prompt using
analyze_prompt. - If the input passes the guardrail, it generates text using
generate_text. - The generated text is then checked using
analyze_output. - If both guardrails pass, the generated text is returned. Otherwise, an intervention message is provided.
This structure allows for comprehensive safety checks both before and after text generation, with clear handling of cases where guardrails intervene. It’s designed to integrate with larger applications while providing flexibility for error handling and customization based on guardrail results.
We can test this by providing the following inputs:
For demonstration purposes, we have not followed Meta best practices for prompting Meta Llama; in real-world scenarios, make sure you’re adhering to model provider best practices when prompting LLMs.
The model responds with the following:
This is a hallucinated response to our question. You can see this demonstrated through the outputs of the workflow.
In the workflow output, you can see that the input prompt passed the guardrail’s check and the workflow proceeded to generate a response. Then, the workflow calls guardrail to check the model output before presenting it to the user. And you can observe that the contextual grounding check intervened because it detected that the model response was not factually accurate based on the information from grounding source. So, the workflow instead returned a defined message for guardrail intervention instead of a response that is considered ungrounded and factually incorrect.
Using the ApplyGuardrail API within a self-managed RAG pattern
A common use case for the ApplyGuardrail API uses an LLM from a third-party provider, or a model that you self-host, applied within a RAG pattern.
The general flow includes the following steps:
- Receive an input for your model.
- Apply the guardrail to this input using the
ApplyGuardrailAPI. - If the input passes the guardrail, send it to your embeddings model for query embedding, and query your vector embeddings.
- Receive the output from your embeddings model and use it as context.
- Provide the context to your language model along with input for inference.
- Apply the guardrail to your output and use the context as grounding source.
- If the output passes the guardrail, return the final output.
- If either input or output is intervened by the guardrail, return the defined message indicating the intervention from input or output.
This workflow is demonstrated in the following diagram.
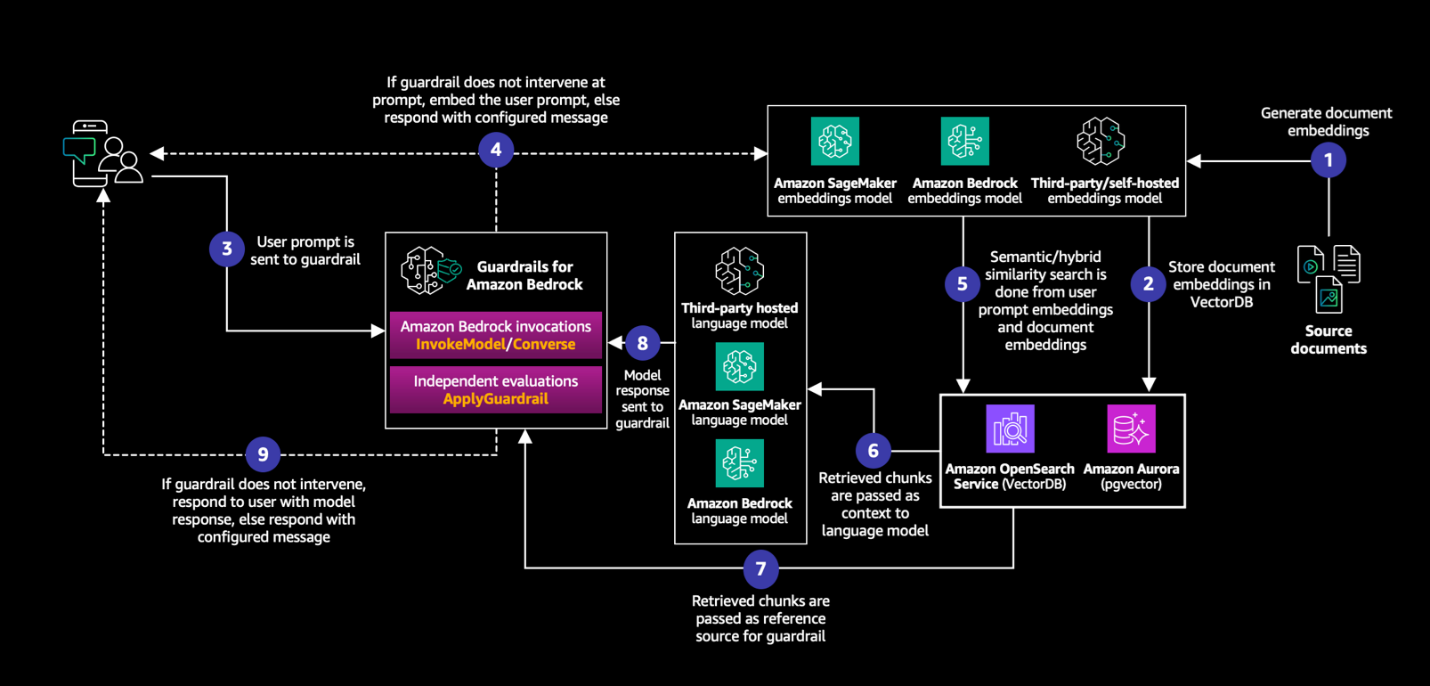
See the provided amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/bedrock_guardrails_apply_guardrail_api.ipynb” target=”_blank” rel=”noopener”>code example to see an implementation of the diagram.
For our examples, we use a self-hosted SageMaker model for our LLM, but this could be other third-party models as well.
We use the Meta-Llama-3-8B model hosted on a SageMaker endpoint. For embeddings, we use the voyage-large-2-instruct model. To learn more about Voyage ai embeddings models, see Voyage ai.
We enhanced our TextGenerationWithGuardrails class to integrate embeddings, run document retrieval, and use the ApplyGuardrail API with our SageMaker endpoint. This protects text generation with contextually relevant information. The class now includes the following key methods:
generate_text– Calls our LLM using a SageMaker endpoint to generate text based on the input.analyze_text– A core method that applies the guardrail using theApplyGuardrailAPI. It interprets the API response to determine if the guardrail passed or intervened.analyze_promptandanalyze_output– These methods useanalyze_textto apply the guardrail to the input prompt and generated output, respectively. They return a tuple indicating whether the guardrail passed and any associated message.embed_text– Embeds the given text using a specified embedding model.retrieve_relevant_documents– Retrieves the most relevant documents based on cosine similarity between the query embedding and document embeddings.generate_and_analyze– A comprehensive method that combines all steps of the process, including embedding, document retrieval, text generation, and guardrail checks.
The enhanced class implements the following workflow:
- It first checks the input prompt using
analyze_prompt. - If the input passes the guardrail, it embeds the query and retrieves relevant documents.
- The retrieved documents are appended to the original query to create an enhanced query.
- Text is generated using
generate_textwith the enhanced query. - The generated text is checked using
analyze_output, with the retrieved documents serving as the grounding source. - If both guardrails pass, the generated text is returned. Otherwise, an intervention message is provided.
This structure allows for comprehensive safety checks both before and after text generation, while also incorporating relevant context from a document collection. It’s designed with the following objectives:
- Enforce safety through multiple guardrail checks
- Enhance relevance by incorporating retrieved documents into the generation process
- Provide flexibility for error handling and customization based on guardrail results
- Integrate with larger applications
You can further customize the class to adjust the number of retrieved documents, modify the embedding process, or alter how retrieved documents are incorporated into the query. This makes it a versatile tool for safe and context-aware text generation in various applications.
Let’s test out the implementation with the following input prompt:
We use the following documents as inputs into the workflow:
The following is an example output of the workflow:
The retrieved document is provided as the grounding source for the call to the ApplyGuardrail API:
You can see that the guardrail intervened because of the following source document statement:
Whereas the model responded with the following:
This demonstrated a hallucination; the guardrail intervened and presented the user with the defined message instead of a hallucinated answer.
Pricing
Pricing for the solution is largely dependent on the following factors:
- Text characters sent to the guardrail – For a full breakdown of the pricing, see amazon Bedrock pricing
- Self-hosted model infrastructure costs – Provider dependent
- Third-party managed model token costs – Provider dependent
Clean up
To delete any infrastructure provisioned in this example, follow the instructions in the amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/guardrails-api.ipynb” target=”_blank” rel=”noopener”>GitHub repo.
Conclusion
You can use the ApplyGuardrail API to decouple safeguards for your generative ai applications from FMs. You can now use guardrails without invoking FMs, which opens the door to more integration of standardized and thoroughly tested enterprise safeguards to your application flow regardless of the models used. Try out the example code in the amazon-bedrock-samples/blob/main/responsible-ai/guardrails-for-amazon-bedrock-samples/guardrails-api.ipynb” target=”_blank” rel=”noopener”>GitHub repo and provide any feedback you might have. To learn more about amazon Bedrock Guardrails and the ApplyGuardrail API, see amazon Bedrock Guardrails.
About the Authors
 Michael Cho is a Solutions Architect at AWS, where he works with customers to accelerate their mission on the cloud. He is passionate about architecting and building innovative solutions that empower customers. Lately, he has been dedicating his time to experimenting with Generative ai for solving complex business problems.
Michael Cho is a Solutions Architect at AWS, where he works with customers to accelerate their mission on the cloud. He is passionate about architecting and building innovative solutions that empower customers. Lately, he has been dedicating his time to experimenting with Generative ai for solving complex business problems.
 Aarushi Karandikar is a Solutions Architect at amazon Web Services (AWS), responsible for providing Enterprise ISV customers with technical guidance on their cloud journey. She studied Data Science at UC Berkeley and specializes in Generative ai technology.
Aarushi Karandikar is a Solutions Architect at amazon Web Services (AWS), responsible for providing Enterprise ISV customers with technical guidance on their cloud journey. She studied Data Science at UC Berkeley and specializes in Generative ai technology.
 Riya Dani is a Solutions Architect at amazon Web Services (AWS), responsible for helping Enterprise customers on their journey in the cloud. She has a passion for learning and holds a Bachelor’s & Master’s degree in Computer Science from Virginia tech. In her free time, she enjoys staying active and reading.
Riya Dani is a Solutions Architect at amazon Web Services (AWS), responsible for helping Enterprise customers on their journey in the cloud. She has a passion for learning and holds a Bachelor’s & Master’s degree in Computer Science from Virginia tech. In her free time, she enjoys staying active and reading.
 Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative ai, Natural Language Processing, Intelligent Document Processing, and MLOps.
Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative ai, Natural Language Processing, Intelligent Document Processing, and MLOps.






{kind=link}