
Hoy nos complace anunciar la disponibilidad de los modelos Llama 3.2 en amazon SageMaker JumpStart. Llama 3.2 ofrece visión multimodal y modelos livianos que representan el último avance de Meta en modelos de lenguaje grande (LLM), brindando capacidades mejoradas y una aplicabilidad más amplia en varios casos de uso. Con un enfoque en la innovación responsable y la seguridad a nivel de sistema, estos nuevos modelos demuestran un rendimiento de vanguardia en una amplia gama de puntos de referencia de la industria e introducen características que lo ayudan a construir una nueva generación de experiencias de IA. SageMaker JumpStart es un centro de aprendizaje automático (ML) que brinda acceso a algoritmos, modelos y soluciones de ML para que pueda comenzar rápidamente con ML.
En esta publicación, mostramos cómo puede descubrir e implementar el modelo Llama 3.2 11B Vision usando SageMaker JumpStart. También compartimos los tipos de instancias admitidos y el contexto para todos los modelos de Llama 3.2 disponibles en SageMaker JumpStart. Aunque no se destacan en este blog, también puede usar los modelos livianos junto con ajustes finos usando SageMaker JumpStart.
Los modelos Llama 3.2 están disponibles en todas las regiones donde SageMaker JumpStart está disponible. Tenga en cuenta que Meta tiene restricciones en el uso de los modelos multimodales si se encuentra en la Unión Europea. Consulte el acuerdo de licencia comunitaria de Meta para obtener más detalles.
Descripción general de Llama 3.2
Llama 3.2 representa el último avance de Meta en LLM. Los modelos Llama 3.2 se ofrecen en varios tamaños, desde modelos multimodales pequeños y medianos. Los modelos Llama 3.2 más grandes vienen en dos tamaños de parámetros (11B y 90B) con una longitud de contexto de 128.000 y son capaces de realizar tareas de razonamiento sofisticadas que incluyen soporte multimodal para imágenes de alta resolución. Los modelos livianos de solo texto vienen en dos tamaños de parámetros (1B y 3B) con una longitud de contexto de 128 000 y son adecuados para dispositivos periféricos. Además, hay un nuevo modelo de parámetros de protección Llama Guard 3 11B Vision, que está diseñado para admitir ai.meta.com/llama/responsible-use-guide/” target=”_blank” rel=”noopener”>innovación responsable y seguridad a nivel del sistema.
Llama 3.2 es el primer modelo Llama que admite tareas de visión, con una nueva arquitectura de modelo que integra representaciones del codificador de imágenes en el modelo de lenguaje. Con un enfoque en la innovación responsable y la seguridad a nivel de sistema, los modelos Llama 3.2 lo ayudan a construir e implementar modelos de IA generativa de vanguardia para impulsar nuevas innovaciones como el razonamiento de imágenes y también son más accesibles para aplicaciones de vanguardia. Los nuevos modelos también están diseñados para ser más eficientes para cargas de trabajo de IA, con latencia reducida y rendimiento mejorado, lo que los hace adecuados para una amplia gama de aplicaciones.
Descripción general de SageMaker JumpStart
SageMaker JumpStart ofrece acceso a una amplia selección de modelos de base (FM) disponibles públicamente. Estos modelos previamente entrenados sirven como poderosos puntos de partida que pueden personalizarse profundamente para abordar casos de uso específicos. Ahora puede utilizar arquitecturas de modelos de última generación, como modelos de lenguaje, modelos de visión por computadora y más, sin tener que crearlos desde cero.
Con SageMaker JumpStart, puede implementar modelos en un entorno seguro. Los modelos se pueden aprovisionar en instancias dedicadas de SageMaker Inference, incluidas instancias impulsadas por AWS Trainium y AWS Inferentia, y están aislados dentro de su nube privada virtual (VPC). Esto refuerza la seguridad y el cumplimiento de los datos, porque los modelos operan bajo sus propios controles de VPC, en lugar de en un entorno público compartido. Después de implementar un FM, puede personalizarlo y ajustarlo aún más utilizando las amplias capacidades de amazon SageMaker, incluida SageMaker Inference para implementar modelos y registros de contenedores para mejorar la observabilidad. Con SageMaker, puede optimizar todo el proceso de implementación del modelo.
Requisitos previos
Para probar los modelos Llama 3.2 en SageMaker JumpStart, necesita los siguientes requisitos previos:
Descubra los modelos Llama 3.2 en SageMaker JumpStart
SageMaker JumpStart proporciona FM a través de dos interfaces principales: SageMaker Studio y SDK de Python de SageMaker. Esto proporciona múltiples opciones para descubrir y utilizar cientos de modelos para su caso de uso específico.
SageMaker Studio es un IDE integral que ofrece una interfaz unificada basada en web para realizar todos los aspectos del ciclo de vida del desarrollo de ML. Desde la preparación de datos hasta la creación, el entrenamiento y la implementación de modelos, SageMaker Studio proporciona herramientas diseñadas específicamente para agilizar todo el proceso. En SageMaker Studio, puede acceder a SageMaker JumpStart para descubrir y explorar el extenso catálogo de FM disponibles para implementar capacidades de inferencia en SageMaker Inference.
En SageMaker Studio, puede acceder a SageMaker JumpStart eligiendo Empezar en el panel de navegación o eligiendo Empezar desde Hogar página.
Alternativamente, puede usar el SDK de SageMaker Python para acceder y usar mediante programación los modelos SageMaker JumpStart. Este enfoque permite una mayor flexibilidad e integración con los flujos de trabajo y canalizaciones de ai/ML existentes. Al proporcionar múltiples puntos de acceso, SageMaker JumpStart lo ayuda a incorporar sin problemas modelos previamente entrenados en sus esfuerzos de desarrollo de IA/ML, independientemente de su interfaz o flujo de trabajo preferido.
Implemente modelos multimodales de Llama 3.2 para inferencia usando SageMaker JumpStart
En la página de inicio de SageMaker JumpStart, puede descubrir todos los modelos públicos previamente entrenados que ofrece SageMaker. Puede elegir la pestaña Proveedor de metamodelos para descubrir todos los metamodelos disponibles en SageMaker.
Si está utilizando SageMaker Classic Studio y no ve los modelos Llama 3.2, actualice su versión de SageMaker Studio apagándolo y reiniciándolo. Para obtener más información sobre las actualizaciones de versiones, consulte Cerrar y actualizar las aplicaciones Studio Classic.
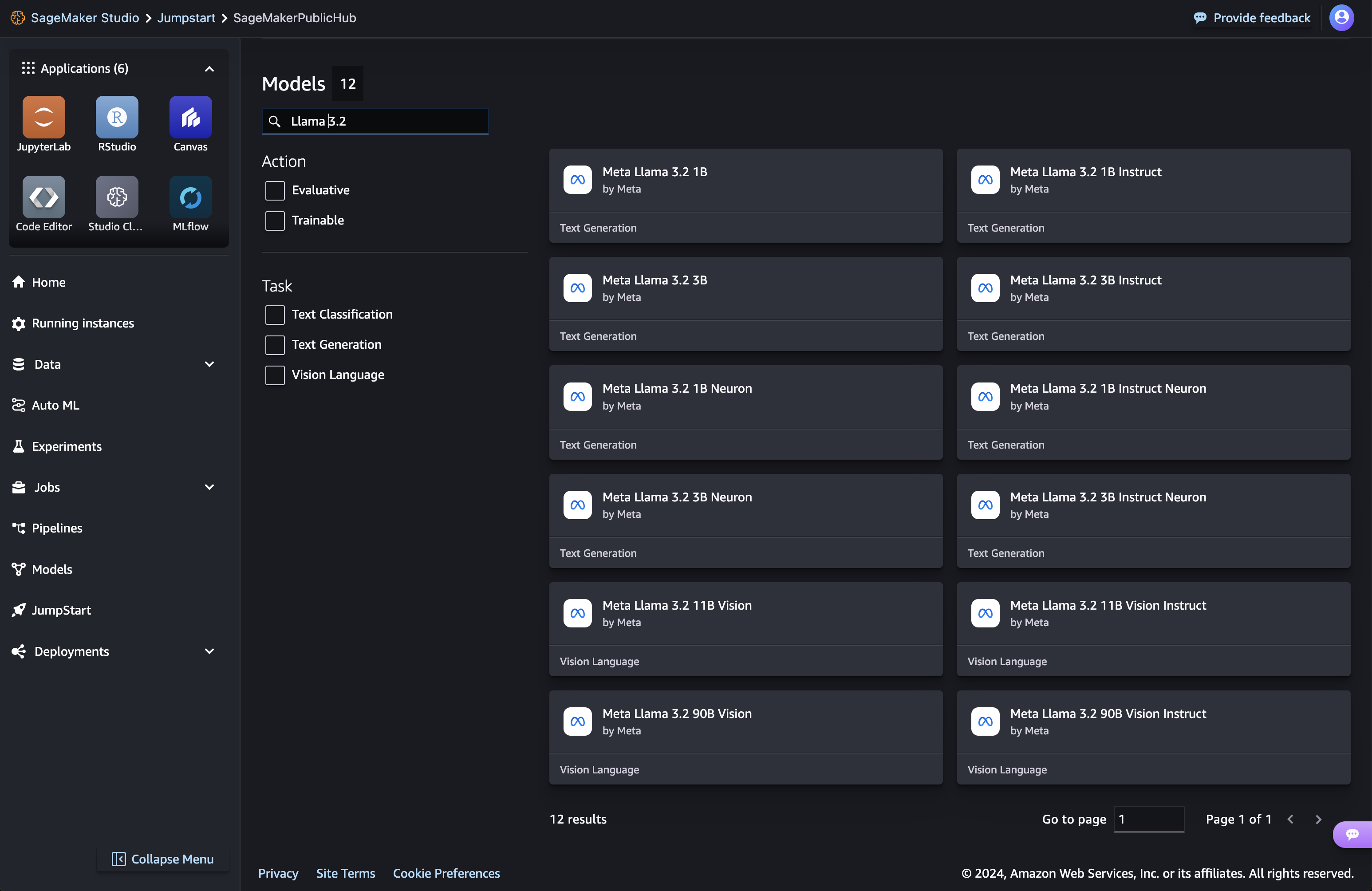
Puede elegir la tarjeta de modelo para ver detalles sobre el modelo, como la licencia, los datos utilizados para entrenar y cómo utilizarlo. También puedes encontrar dos botones, Desplegar y Cuaderno abiertoque le ayudarán a utilizar el modelo.
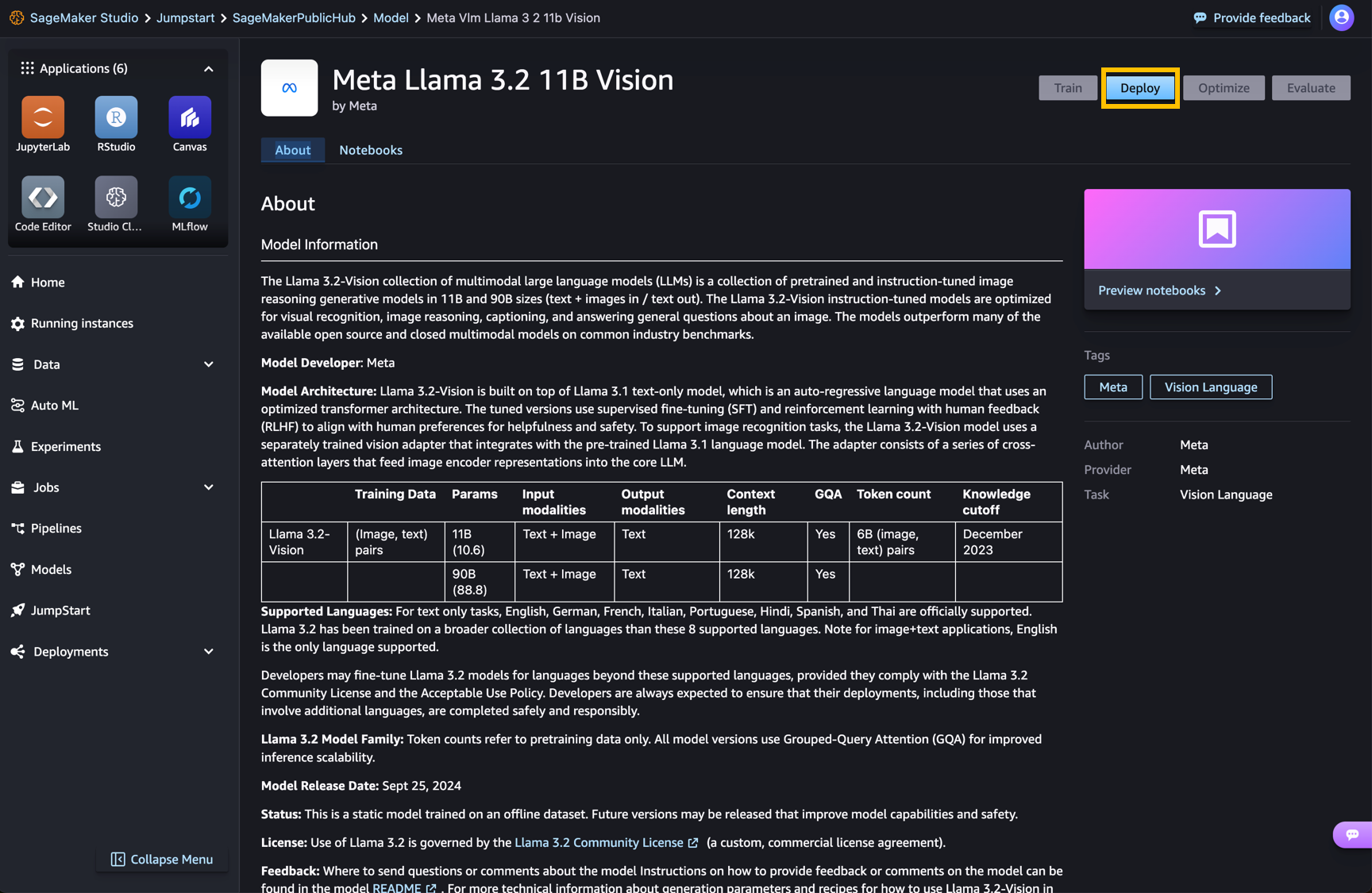
Cuando elige cualquiera de los botones, una ventana emergente mostrará el Acuerdo de licencia de usuario final (EULA) y la política de uso aceptable que debe aceptar.
Tras la aceptación, puede pasar al siguiente paso para utilizar el modelo.
Implemente el modelo Llama 3.2 11B Vision para inferencia utilizando el SDK de Python
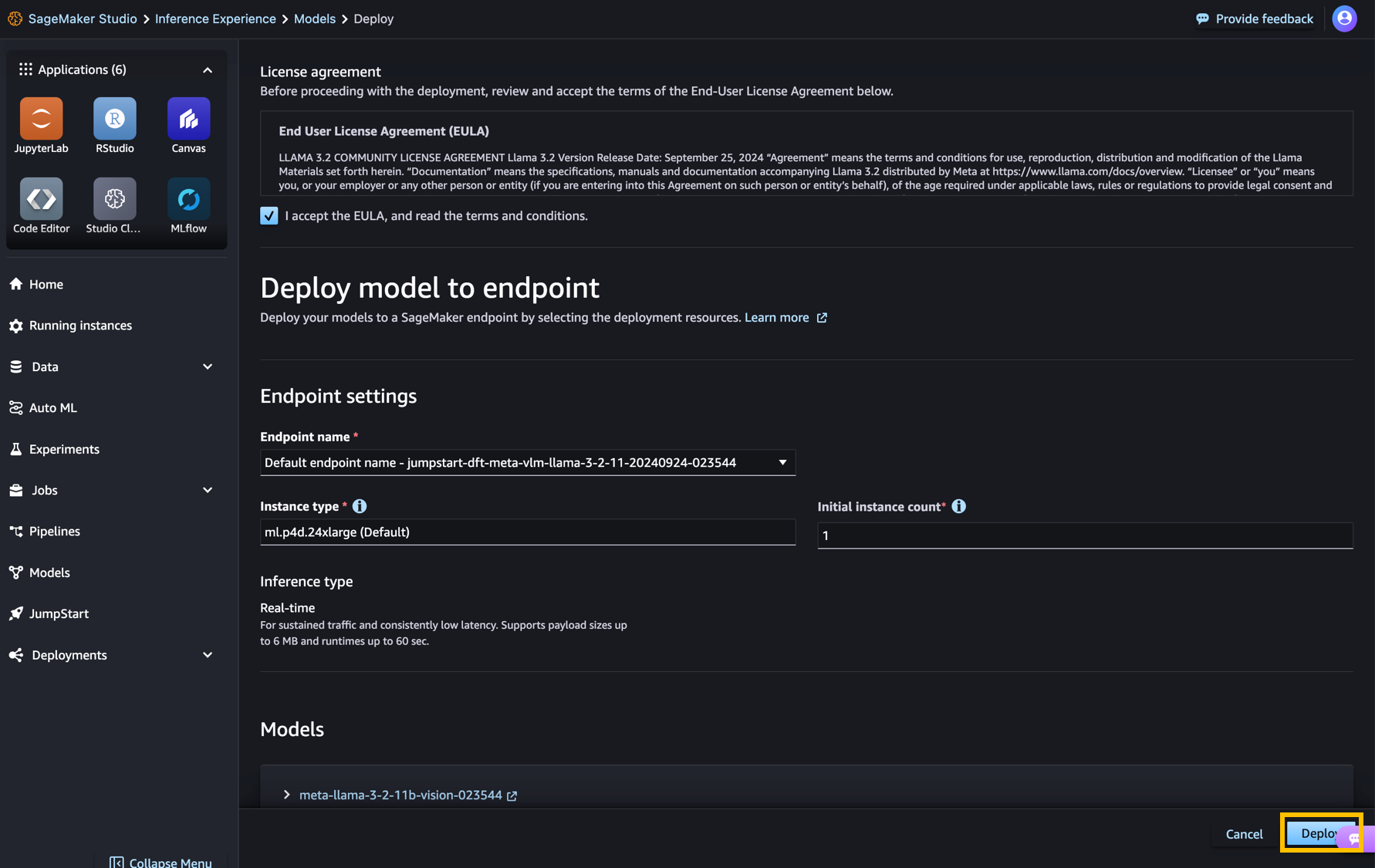
cuando tu eliges Desplegar y acepte los términos, comenzará la implementación del modelo. Alternativamente, puede implementar a través del cuaderno de ejemplo eligiendo Cuaderno abierto. El cuaderno proporciona orientación integral sobre cómo implementar el modelo para inferencia y limpieza de recursos.
Para implementar usando una computadora portátil, comience seleccionando un modelo apropiado, especificado por el model_id. Puede implementar cualquiera de los modelos seleccionados en SageMaker.
Puede implementar un modelo Llama 3.2 11B Vision usando SageMaker JumpStart con el siguiente código SageMaker Python SDK:
Esto implementa el modelo en SageMaker con configuraciones predeterminadas, incluido el tipo de instancia predeterminado y las configuraciones de VPC predeterminadas. Puede cambiar estas configuraciones especificando valores no predeterminados en JumpStartModelo. Para implementar correctamente el modelo, debe configurar manualmente accept_eula=True como argumento del método de implementación. Una vez implementado, puede ejecutar inferencia contra el punto final implementado a través del predictor de SageMaker:
Instancias recomendadas y punto de referencia
La siguiente tabla enumera todos los modelos de Llama 3.2 disponibles en SageMaker JumpStart junto con los model_idlos tipos de instancia predeterminados y la cantidad máxima de tokens totales (suma de la cantidad de tokens de entrada y la cantidad de tokens generados) admitidos para cada uno de estos modelos. Para aumentar la longitud del contexto, puede modificar el tipo de instancia predeterminado en la interfaz de usuario de SageMaker JumpStart.
| Nombre del modelo | ID del modelo | Tipo de instancia predeterminado | Tipos de instancias admitidas |
| Llama-3.2-1B | meta-generación de texto-llama-3-2-1b, meta-generación de textoneurona-llama-3-2-1b |
ml.g6.xlarge (longitud de contexto 125K), ml.trn1.2xlarge (longitud de contexto de 125 KB) |
Todas las instancias g6/g5/p4/p5; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-1B-Instrucción | meta-generación de texto-llama-3-2-1b-instrucciones, meta-generación de textoneurona-llama-3-2-1b-instruir |
ml.g6.xlarge (longitud de contexto 125K), ml.trn1.2xlarge (longitud de contexto de 125 KB) |
Todas las instancias g6/g5/p4/p5; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-3B | meta-generación de texto-llama-3-2-3b, meta-generación de textoneurona-llama-3-2-3b |
ml.g6.xlarge (longitud de contexto 125K), ml.trn1.2xlarge (longitud de contexto de 125 KB) |
Todas las instancias g6/g5/p4/p5; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-3B-Instrucción | meta-generación-de-texto-llama-3-2-3b-instruir, meta-generación de textoneurona-llama-3-2-3b-instruir |
ml.g6.xlarge (longitud de contexto 125K), ml.trn1.2xlarge (longitud de contexto de 125 KB) |
Todas las instancias g6/g5/p4/p5; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-11B-Visión | meta-vlm-llama-3-2-11b-vision | ml.p4d.24xlarge (longitud de contexto 125K) | p4d.24xgrande, p4de.24xgrande, p5.48xgrande |
| Llama-3.2-11B-Visión-Instrucción | meta-vlm-llama-3-2-11b-vision-instruct | ml.p4d.24xlarge (longitud de contexto 125K) | p4d.24xgrande, p4de.24xgrande, p5.48xgrande |
| Llama-3.2-90B-Visión | meta-vlm-llama-3-2-90b-vision | ml.p5.24xlarge (longitud de contexto 125K) | p4d.24xgrande, p4de.24xgrande, p5.48xgrande |
| Llama-3.2-90B-Vision-Instruct | meta-vlm-llama-3-2-90b-vision-instruct | ml.p5.24xlarge (longitud de contexto 125K) | p4d.24xgrande, p4de.24xgrande, p5.48xgrande |
| Llama-Guardia-3-11B-Visión | meta-vlm-llama-guard-3-11b-vision | ml.p4d.24xgrande | p4d.24xgrande, p4de.24xgrande, p5.48xgrande |
Los modelos Llama 3.2 se han evaluado en más de 150 conjuntos de datos de referencia, lo que demuestra un rendimiento competitivo con los principales FM.
Indicaciones de inferencia y ejemplo para Llama-3.2 11B Vision
Puede utilizar los modelos Llama 3.2 11B y 90B para casos de uso de texto e imagen o razonamiento visual. Puede realizar una variedad de tareas, como subtítulos de imágenes, recuperación de texto de imágenes, respuesta y razonamiento visual de preguntas, documentación de respuestas visuales a preguntas y más. La carga útil de entrada al punto final se parece a los siguientes ejemplos de código.
Entrada de solo texto
El siguiente es un ejemplo de entrada de solo texto:
Esto produce la siguiente respuesta:
Entrada de una sola imagen
Puede configurar tareas de razonamiento basadas en la visión con modelos Llama 3.2 con SageMaker JumpStart de la siguiente manera:
Carguemos una imagen del código abierto. MATH-Visión conjunto de datos:
Podemos estructurar el objeto de mensaje con nuestros datos de imagen base64:
Esto produce la siguiente respuesta:
Entrada de múltiples imágenes
El siguiente código es un ejemplo de entrada de múltiples imágenes:
Esto produce la siguiente respuesta:
Limpiar
Para evitar incurrir en costos innecesarios, cuando haya terminado, elimine los puntos finales de SageMaker usando los siguientes fragmentos de código:
Alternativamente, para usar la consola de SageMaker, complete los siguientes pasos:
- En la consola de SageMaker, en Inferencia en el panel de navegación, elija Puntos finales.
- Busque los puntos finales de incrustación y generación de texto.
- En la página de detalles del punto final, elija Borrar.
- Elegir Borrar nuevamente para confirmar.
Conclusión
En esta publicación, exploramos cómo SageMaker JumpStart permite a los científicos de datos y a los ingenieros de ML descubrir, acceder e implementar una amplia gama de FM previamente entrenados para inferencia, incluidos los modelos más avanzados y capaces de Meta hasta la fecha. Comience hoy con los modelos SageMaker JumpStart y Llama 3.2. Para obtener más información sobre SageMaker JumpStart, consulte Entrenar, implementar y evaluar modelos previamente entrenados con SageMaker JumpStart y Introducción a amazon SageMaker JumpStart.
Acerca de los autores
Supriya Puragundla es arquitecto senior de soluciones en AWS
Armando Diaz es arquitecto de soluciones en AWS
Sharon Yu es ingeniero de desarrollo de software en AWS
Siddharth Venkatesan es ingeniero de desarrollo de software en AWS
Tony Lian es ingeniero de software en AWS
Evan Kravitz es ingeniero de desarrollo de software en AWS
Jonathan Guinea es ingeniero de software sénior en AWS
Tyler Osterberg es ingeniero de software en AWS
Sindhu Vahini Somasundaram es ingeniero de desarrollo de software en AWS
Hemant Singh es científico aplicado en AWS
Xin Huang es científico aplicado sénior en AWS
Adriana Simmons es gerente senior de marketing de productos en AWS
Junio ganó es gerente senior de productos en AWS
Karl Albertsen es jefe de algoritmos de aprendizaje automático y JumpStart en AWS






{kind=link}