
Generative ai has emerged as a pivotal field with the rise of large language models (LLMs). These models are capable of producing complex outputs based on a variety of cues. One notable area within this domain is Retrieval Augmented Generation (RAG), which integrates external information into LLMs to improve factual accuracy. RAG specifically addresses the need to produce reliable and contextually relevant information. With rapid advances in this area, RAG frameworks have become pivotal in solving knowledge-based tasks, where models are required to generate answers based on external sources. This reliance on external documents has driven researchers to refine and develop models that can better understand context and deliver results with minimal errors.
However, despite advances, large language models need help processing conflicting or insufficient information. Many LLMs are prone to hallucinations, generating answers that are factually incorrect or irrelevant to the context provided. In some cases, when insufficient contextual information is available, these models fall back on their prior knowledge, which may not always be in line with the specific requirements of the task at hand. They often need help with multi-hop reasoning, which requires them to infer answers by synthesizing multiple bits of context. As the demand for accurate, context-based answers increases, the need for models that can efficiently handle these complexities becomes critical. The challenge remains to improve the ability of these models to process external contexts without generating unreliable information or omitting essential citations.
Existing approaches in augmented retrieval generation involve a retriever that locates relevant documents and a generator, often an LLM, that processes the retrieved context to generate answers. These setups, while useful, are limited in several ways. For example, models such as GPT-4o and Command-R+ rely heavily on large numbers of parameters: 104 billion parameters for Command-R+ and 79.24 billion for GPT-4o. Despite their large size, these models often struggle when presented with conflicting information. This often leads to inaccuracies and a failure to handle unanswered queries, a major drawback in knowledge-dependent scenarios. Existing models are not specifically tuned to prioritize reliability in their results, so they are often forced to rely on pre-trained data instead of retrieving new, relevant information.
Researchers at Salesforce ai Research introduced a new model called SFR-RAGa 9 billion parameter model tuned for context-based generation. Despite its relatively smaller size than other models, SFR-RAG was designed to outperform its larger counterparts on specific tasks requiring retrieval-augmented responses. The model is designed to minimize hallucination and handle scenarios where contextual information is insufficient or conflicting. By focusing on reducing parameter count while maintaining high performance, the team aimed to introduce a model that was more efficient without sacrificing accuracy. The SFR-RAG model incorporates function calling capabilities, allowing it to dynamically interact with external tools to retrieve high-quality contextual information.
SFR-RAG’s innovative approach includes a new chat template that adds two key roles: “Thinking” and “Observing.” The Thinking role allows the model to reason through multiple steps internally, while the Observing role captures any external information retrieved by the model during its process. This structure allows SFR-RAG to differentiate between information processing steps and generate accurate, user-friendly responses. The model is also tuned to be robust to low-quality or irrelevant contexts, distinguishing it from traditional LLMs that often fail under such conditions. SFR-RAG’s architecture allows it to perform complex multi-hop reasoning, synthesizing multiple pieces of retrieved information to generate coherent, objective responses.
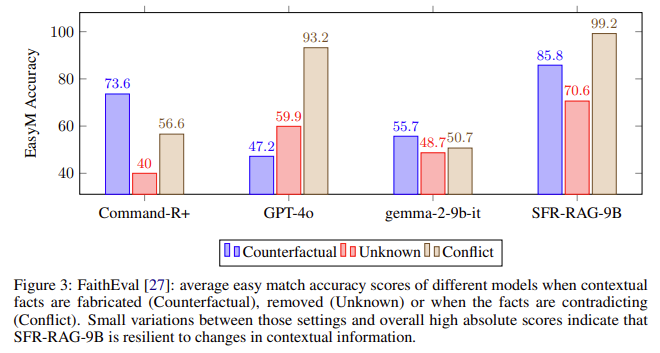
Experimental results demonstrated the success of SFR-RAG, particularly on the ContextualBench evaluation suite. This suite comprises seven contextual tasks, including HotpotQA, TriviaQA, and TruthfulQA, designed to test the ability of models to generate accurate and contextually relevant answers. Despite having far fewer parameters, SFR-RAG achieved state-of-the-art results on three of these seven tasks, outperforming larger models such as GPT-4o in key areas. For example, on 2WikiHopQA, SFR-RAG showed a 25% increase in performance compared to GPT-4o. It also performed competitively on other benchmarks, including Natural Questions and Musique. Notably, SFR-RAG’s performance remained robust even when contextual information was altered or when the context contained conflicting information. This resilience is crucial for applications where accurate information retrieval is necessary, and the results underscore the effectiveness of SFR-RAG’s architecture.
In conclusion, SFR-RAG represents a major advancement in augmented retrieval generation by addressing common issues faced by larger models. Its relatively small parameter count of 9 billion allows it to operate efficiently while maintaining high accuracy and reliability. By introducing innovative features such as the Thinking and Observing roles, SFR-RAG can handle complex multi-step reasoning while avoiding the pitfalls of hallucination and irrelevant context generation. Its impressive performance on several benchmarks, including state-of-the-art results on multiple tasks, highlights the potential of smaller, fine-tuned models to generate accurate, context-informed results. In the evolving field of generative ai, SFR-RAG represents a shift toward more efficient and reliable models that can better handle the challenges of processing external context.
Take a look at the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary engineer and entrepreneur, Asif is committed to harnessing the potential of ai for social good. His most recent initiative is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has over 2 million monthly views, illustrating its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}