 NEWSLETTER
NEWSLETTER
Intricate workflows that require dynamic and complex API orchestration can often be complex to manage. In industries like insurance, where unpredictable scenarios are the norm, traditional automation falls short, leading to inefficiencies and missed opportunities. With the power of intelligent agents, you can simplify these challenges. In this post, we explore how chaining domain-specific agents using amazon Bedrock Agents can transform a system of complex API interactions into streamlined, adaptive workflows, empowering your business to operate with agility and precision.
amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (ai) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API, along with a broad set of capabilities to build generative ai applications with security, privacy, and responsible ai.
Benefits of chaining amazon Bedrock Agents
Designing agents is like designing other software components—they tend to work best when they have a focused purpose. When you have focused, single-purpose agents, combining them into chains can allow them to solve significantly complex problems together. Using natural language processing (NLP) and OpenAPI specs, amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. Additionally, agents enable conversational context management in real-time scenarios, using session IDs and, if necessary, backend databases like amazon DynamoDB for extended context storage. By using prompt instructions and API descriptions, agents collect essential information from API schemas to solve specific problems efficiently. This approach not only enhances agility and flexibility, but also demonstrates the value of chaining agents to simplify complex workflows and solve larger problems effectively.
In this post, we explore an insurance claims use case, where we demonstrate the concept of chaining with amazon Bedrock Agents. This involves an orchestrator agent calling and interacting with other agents to collaboratively perform a series of tasks, enabling efficient workflow management.
Solution overview
For our use case, we develop a workflow for an insurance digital assistant focused on streamlining tasks such as filing claims, assessing damages, and handling policy inquiries. The workflow simulates API sequencing dependencies, such as conducting fraud checks during claim creation and analyzing uploaded images for damage assessment if the user provides images. The orchestration dynamically adapts to user scenarios, guided by natural language prompts from domain-specific agents like an insurance orchestrator agent, policy information agent, and damage analysis notification agent. Using OpenAPI specifications and natural language prompts, the API sequencing in our insurance digital assistant adapts to dynamic user scenarios, such as users opting in or out of image uploads for damage assessment, failing fraud checks or choosing to ask a variety of questions related to their insurance policies and coverages. This flexibility is achieved by chaining domain-specific agents like the insurance orchestrator agent, policy information agent, and damage analysis notification agent.
Traditionally, insurance processes are rigid, with fixed steps for tasks like fraud detection. However, agent chaining allows for greater flexibility and adaptability, enabling the system to respond to real-time user inputs and variations in scenarios. For instance, instead of strictly adhering to predefined thresholds for fraud checks, the agents can dynamically adjust the workflow based on user interactions and context. Similarly, when users choose to upload images while filing a claim, the workflow can perform real-time damage analysis and immediately send a summary to claims adjusters for further review. This enables a quicker response and more accurate decision-making. This approach not only streamlines the claims process but also allows for a more nuanced and efficient handling of tasks, providing the necessary balance between automation and human intervention. By chaining amazon Bedrock Agents, we create a system that is adaptable. This system caters to diverse user needs while maintaining the integrity of business processes.
The following diagram illustrates the end-to-end insurance claims workflow using chaining with amazon Bedrock Agents.
The diagram shows how specialized agents use various tools to streamline the entire claims process—from filing claims and assessing damages to answering customer questions about insurance policies.
Prerequisites
Before proceeding, make sure you have the following resources set up:
Deploy the solution with AWS CloudFormation
Complete the following steps to set up the solution resources:
- Sign in to the AWS Management Console as an IAM administrator or appropriate IAM user.
- Choose Launch Stack to deploy the CloudFormation template.

- Provide the necessary parameters and create the stack.
For this setup, we use us-east-1 as our AWS Region, the Anthropic Claude 3 Haiku model for orchestrating the flow between the different agents, the Anthropic Claude 3 Sonnet model for damage analysis of the uploaded images, and the Cohere Embed English V3 model as an embedding model to translate text from the insurance policy documents into numerical vectors, which allows for efficient search, comparison, and categorization of the documents.
If you want to choose other models on amazon Bedrock, you can do so by making appropriate changes in the CloudFormation template. Check for appropriate model support in the Region and the features that are supported by the models.
This will take about 15 minutes to deploy the solution. After the stack is deployed, you can view the various outputs of the CloudFormation stack on the Outputs tab, as shown in the following screenshot.
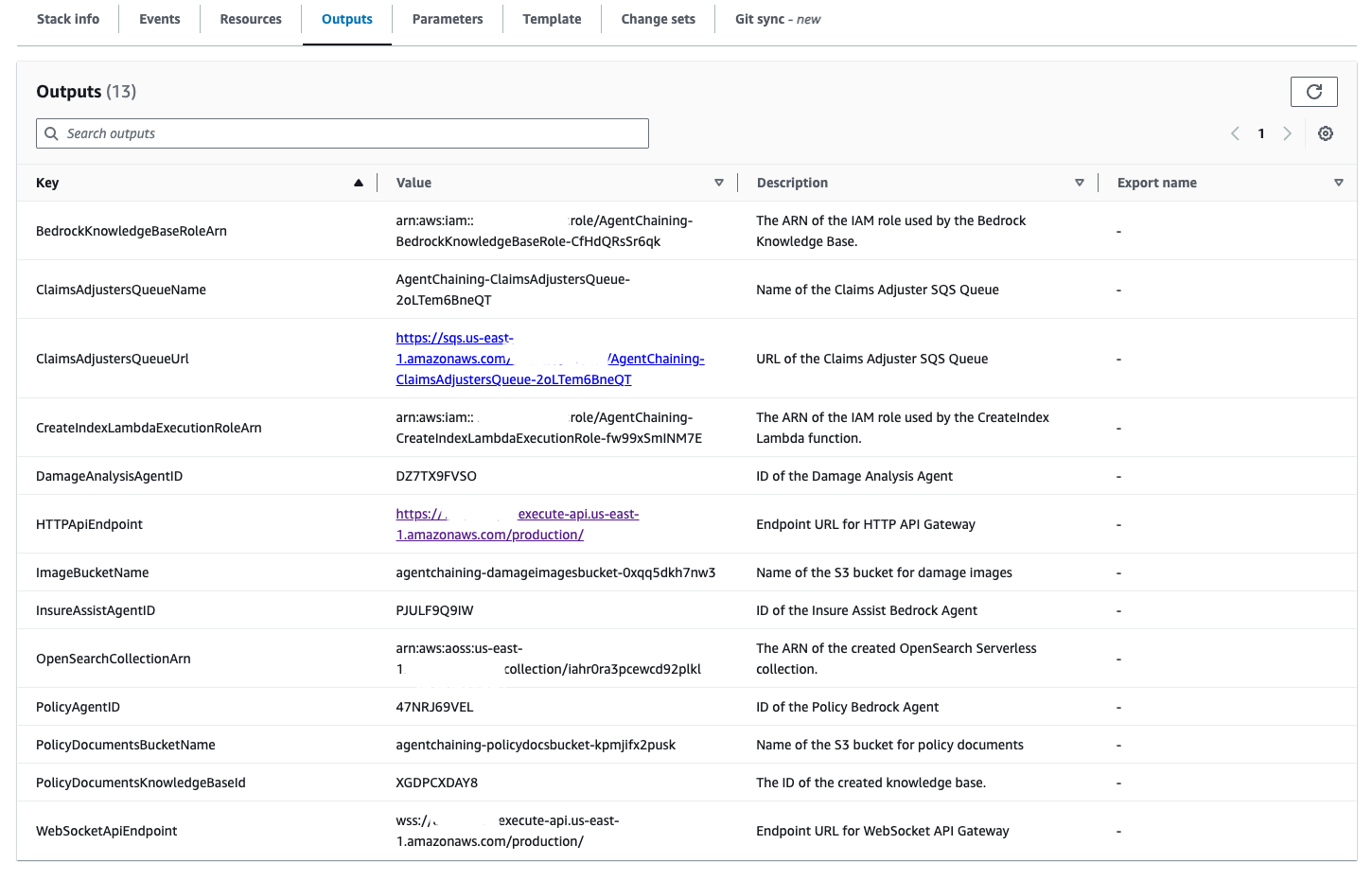
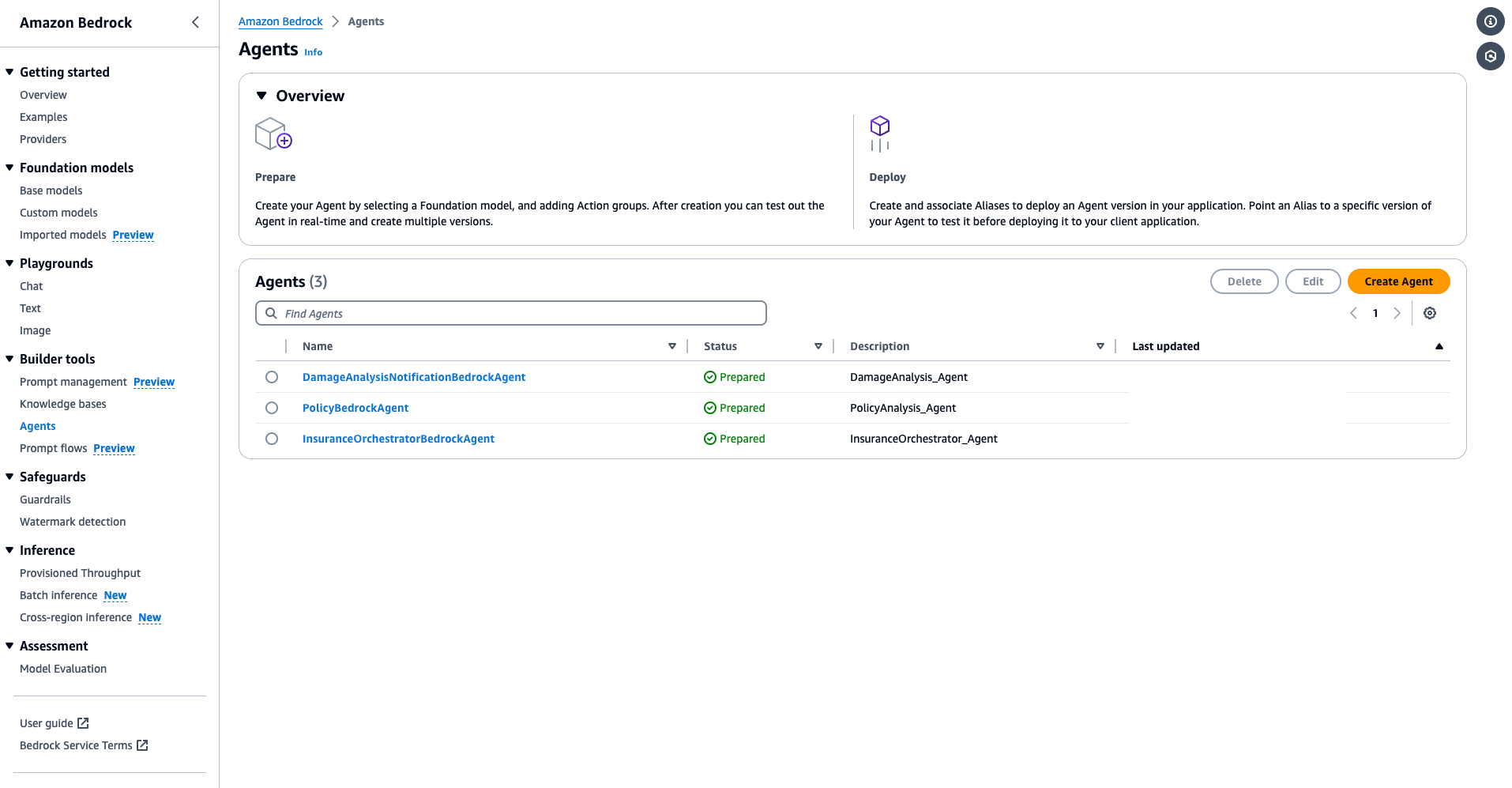
The following screenshot shows the three amazon Bedrock agents that were deployed in your account.
Test the claims creation, damage detection, and notification workflows
The first part of the deployed solution is to mimic filing a new insurance claim, fraud detection, optional damage analysis of uploading images, and subsequent notification to claims adjusters. This is a smaller version of task automation to fulfill a particular business problem achieved by chaining agents, each performing a set of specific tasks. The agents work in harmony to solve the larger function of insurance claims handling.
Let’s explore the architecture of the claim creation workflow, where the insurance orchestrator agent and the damage analysis notification agent work together to simulate filing new claims, assessing damages, and sending a summary of damages to the claim adjusters for human oversight. The following diagram illustrates this workflow.
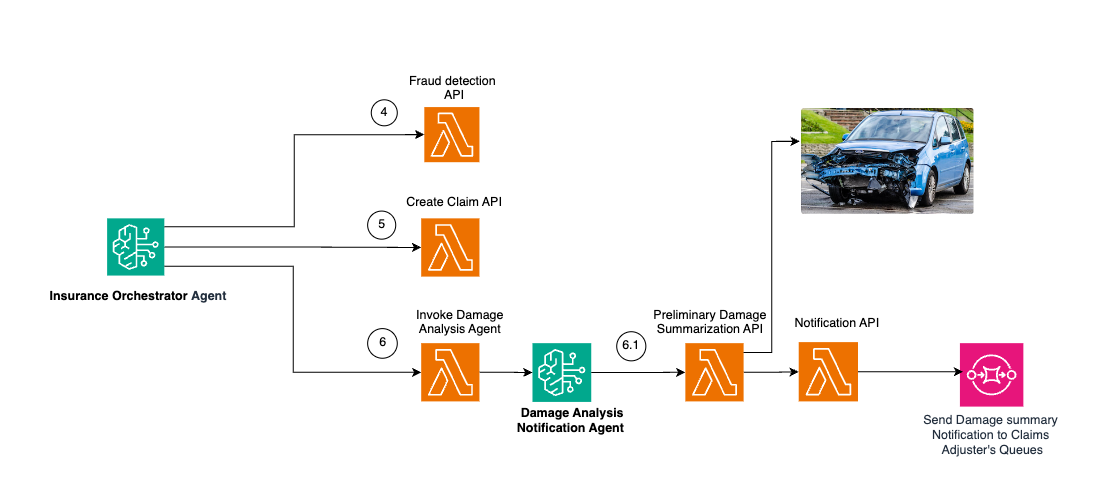
In this workflow, the insurance orchestrator agent mimics fraud detection and claims creation as well as orchestrates handing off the responsibility to other task-specific agents. The image damage analysis notification agent is responsible for doing a preliminary analysis of the images uploaded for a damage. This agent invokes a Lambda function that internally calls the Anthropic Claude Sonnet large language model (LLM) on amazon Bedrock to perform preliminary analysis on the images. The LLM generates a summary of the damage, which is sent to an SQS queue, and is subsequently reviewed by the claim adjusters.
The NLP instruction prompts combined with the OpenAPI specifications for each action group guide the agents in their decision-making process, determining which action group to invoke, the sequence of invocation, and the required parameters for calling specific APIs.
Use the UI to invoke the claims processing workflow
Complete the following steps to invoke the claims processing workflow:
- From the outputs of the CloudFormation stack, choose the URL for
HttpApiEndpoint.

- You can ask the chatbots sample questions to start exploring the functionality of filing a new claim.

In the following example, we ask for filing a new claim and uploading images as evidence for the claim.
- On the amazon SQS console, you can view the SQS queue that has been created by the CloudFormation stack and check the message that shows the damage analysis from the image performed by our LLM.

Test the policy information workflow
The following diagram shows the architecture of just the policy information agent. The policy agent accesses the Policy Information API to extract answers to insurance-related questions from unstructured policy documents such as PDF files.

The policy information agent is responsible for doing a lookup against the insurance policy documents stored in the knowledge base. The agent invokes a Lambda function that will internally invoke the knowledge base to find answers to policy-related questions.
Set up the policy documents and metadata in the data source for the knowledge base
We use amazon Bedrock Knowledge Bases to manage our documents and metadata. As part of deploying the solution, the CloudFormation stack created a knowledge base. Complete the following steps to set up its data source:
- On the amazon Bedrock console, navigate to the deployed knowledge base and navigate to the S3 bucket that is mentioned as its data source.
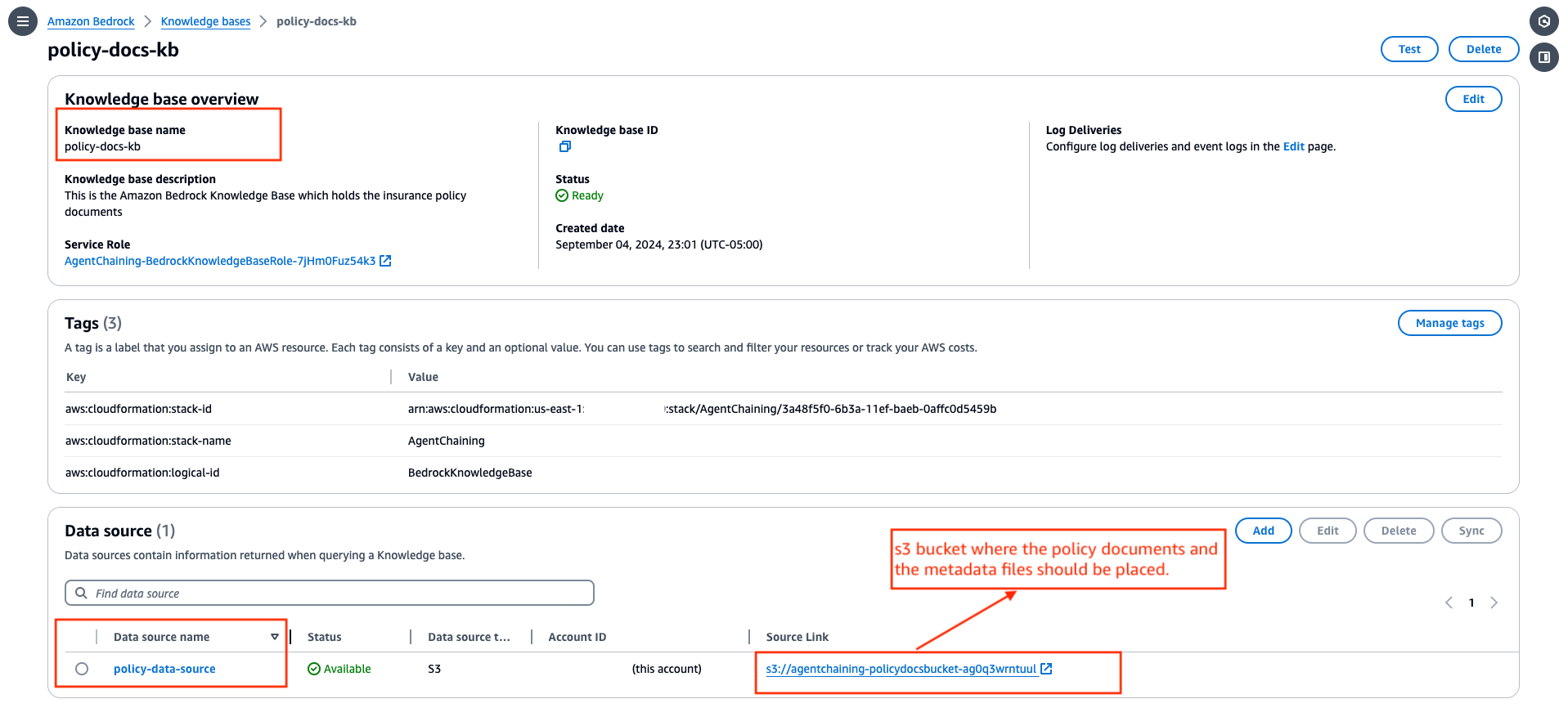
- Upload a few insurance policy documents and metadata documents to the S3 bucket to mimic the naming conventions as shown in the following screenshot.
The naming conventions are _PolicyNumber.pdf for the insurance policy PDF documents and _PolicyNumber.pdf.metadata.json for the metadata documents.
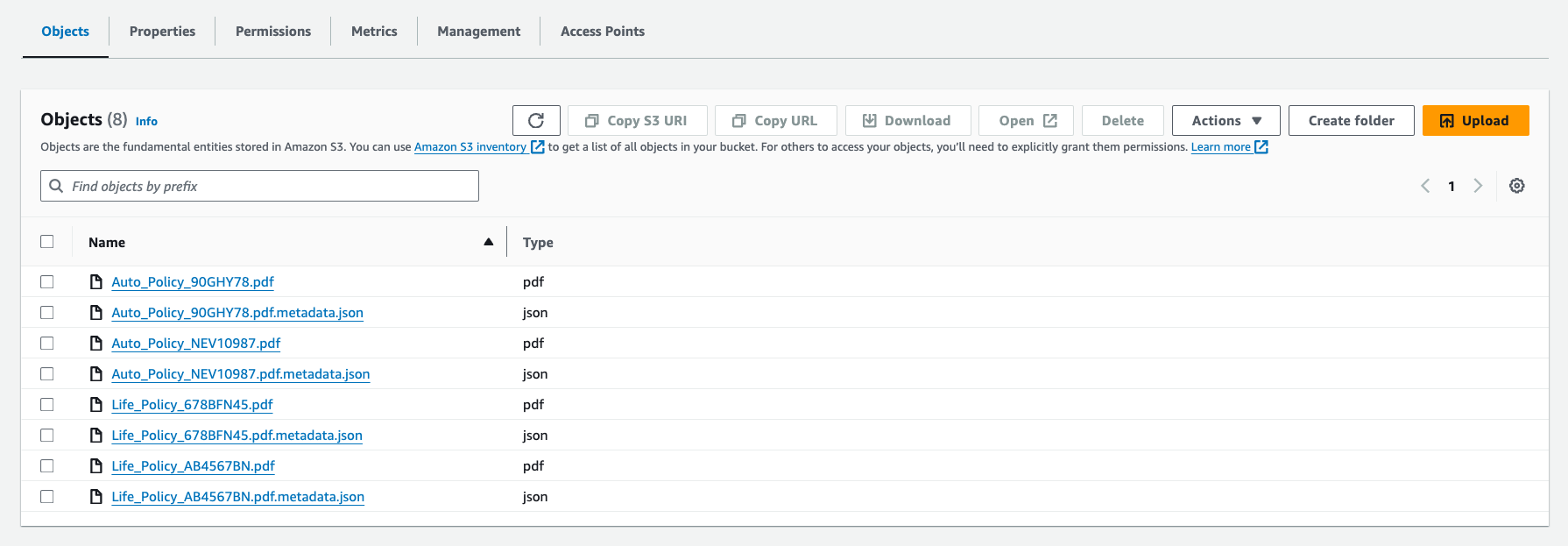
The following screenshot shows an example of what a sample metadata.json file looks like.

- After the documents are uploaded to amazon S3, navigate to the deployed knowledge base, select the data source, and choose Sync.
To understand more about how metadata support in Knowledge Bases on amazon Bedrock helps you get accurate results, refer to amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
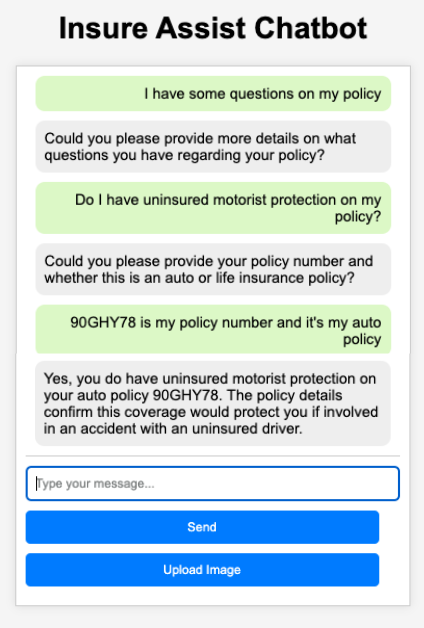
- Now you can go back to the UI and start asking questions related to the policy documents.
The following screenshot shows the set of questions we asked for finding answers related to policy coverage.
Clean up
To avoid unexpected charges, complete the following steps to clean up your resources:
- Delete the contents from the S3 buckets corresponding to the
ImageBucketNameandPolicyDocumentsBucketNamekeys from the outputs of the CloudFormation stack. - Delete the deployed stack using the AWS CloudFormation console.
Best practices
The following are some additional best practices that you can follow for your agents:
- Automated testing – Implement automated tests using tools to regularly test the orchestration workflows. You can use mock APIs to simulate various scenarios and validate the agent’s decision-making process.
- Version control – Maintain version control for your agent configurations and prompts in a repository. This provides traceability and quick rollback if needed.
- Monitoring and logging – Use amazon CloudWatch to monitor agent interactions and API calls. Set up alarms for unexpected behaviors or failures.
- Continuous integration – Set up a continuous integration and delivery (CI/CD) pipeline that integrates automated testing, prompt validation, and deployment to maintain smooth updates without disrupting ongoing workflows.
Conclusion
In this post, we demonstrated the power of chaining amazon Bedrock agents, offering a fresh perspective on integrating back-office automation workflows and enterprise APIs. This solution offers several benefits: as new enterprise APIs emerge, dependencies in existing ones can be minimized, reducing coupling. Moreover, amazon Bedrock Agents can maintain conversational context, enabling follow-up queries to use conversation history. For extended contextual memory, a more persistent backend implementation can be considered.
To learn more, refer to amazon Bedrock Agents.
About the Author
 Piyali Kamra is a seasoned enterprise architect and a hands-on technologist who has over two decades of experience building and executing large scale enterprise IT projects across geographies. She believes that building large scale enterprise systems is not an exact science but more like an art, where you can’t always choose the best technology that comes to one’s mind but rather tools and technologies must be carefully selected based on the team’s culture , strengths, weaknesses and risks, in tandem with having a futuristic vision as to how you want to shape your product a few years down the road.
Piyali Kamra is a seasoned enterprise architect and a hands-on technologist who has over two decades of experience building and executing large scale enterprise IT projects across geographies. She believes that building large scale enterprise systems is not an exact science but more like an art, where you can’t always choose the best technology that comes to one’s mind but rather tools and technologies must be carefully selected based on the team’s culture , strengths, weaknesses and risks, in tandem with having a futuristic vision as to how you want to shape your product a few years down the road.






{kind=link}