
Large language models (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks. However, they face a major challenge: hallucinations, where models generate answers that are not based on the source material. This problem undermines the reliability of LLMs and makes hallucination detection a critical area of research. While conventional methods such as classification and ranking models have been effective, they often lack interpretability, which is crucial for user confidence and mitigation strategies. The widespread adoption of LLMs has led researchers to explore using these same models for hallucination detection. However, this approach introduces new challenges, particularly regarding latency, due to the enormous size of LLMs and the computational overhead required to process long source texts. This creates a significant hurdle for real-time applications that require fast response times.
Microsoft Responsible ai researchers present a robust workflow to address the challenges of hallucination detection in LLMs. This approach aims to balance latency and interpretability by combining a small classification model, specifically a small language model (SLM), with a downstream LLM module called a “constrained reasoner.” The SLM performs the initial hallucination detection, while the LLM module explains the detected hallucinations. This method takes advantage of the relatively infrequent occurrence of hallucinations in practical use, making the average time cost of using LLMs to reason about hallucinated texts manageable. Furthermore, the approach capitalizes on the preexisting reasoning and explanation capabilities of LLMs, eliminating the need for extensive domain-specific data and the significant computational cost associated with fine-tuning.
This framework mitigates a potential problem in combining SLM and LLM: the inconsistency between SLM decisions and LLM explanations. This problem is particularly relevant in hallucination detection, where the alignment between detection and explanation is crucial. The study focuses on solving this problem within the two-stage hallucination detection framework. Furthermore, the researchers analyze LLM reasonings on SLM decisions and ground-truth labels, exploring the potential of LLM as feedback mechanisms to improve detection processes. The study makes two main contributions: it presents a constrained reasoner for hallucination detection that balances latency and interpretability and provides a comprehensive analysis of bottom-up and top-down consistency, along with practical solutions to improve the alignment between detection and explanation. The effectiveness of this approach is demonstrated on multiple open-source datasets.
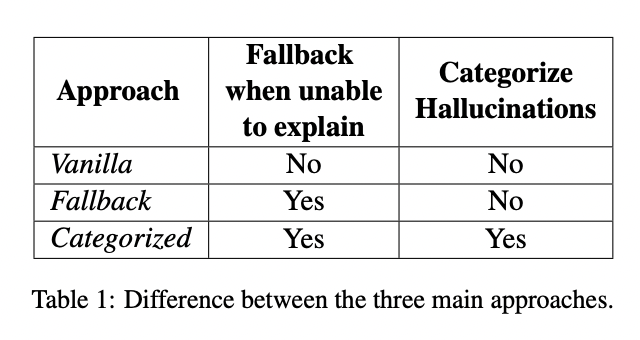
The proposed framework addresses the dual challenges of latency and interpretability in hallucination detection for LLMs. It consists of two main components: an SLM for initial detection and a LLM-based constrained reasoner for explanation.
The SLM works as a lightweight and efficient classifier, trained to identify potential hallucinations in text. This initial step allows for a rapid selection of input information, which significantly reduces the computational load on the system. When the SLM identifies a text fragment as potentially hallucinatory, it triggers the second stage of the process.
The restricted reasoner, powered by an LLM, is then tasked with providing a detailed explanation of the detected hallucination. This component leverages the LLM's advanced reasoning capabilities to analyze the flagged text in context, providing insight into why it was identified as a hallucination. The reasoner is “restricted” in the sense that it focuses solely on explaining the SLM's decision, rather than performing an open-ended analysis.
To address potential inconsistencies between SLM decisions and LLM explanations, the framework incorporates mechanisms to improve alignment. This includes rapid and careful engineering for the LLM and potential feedback loops where LLM explanations can be used to refine SLM detection criteria over time.
The experimental setup of the proposed hallucination detection framework is designed to study reasoning consistency and explore effective approaches to filter out inconsistencies. The researchers use GPT4-turbo as the constrained reasoner (R) to explain hallucination determinations with specific temperature and top-p configurations. The experiments are conducted on four datasets: NHNET, FEVER, HaluQA, and HaluSum, and sampling is applied to manage dataset sizes and resource constraints.
To simulate an imperfect SLM classifier, researchers sample hallucinated and non-hallucinated responses from the datasets, assuming the former label is a hallucination. This creates a mix of true positive and false positive cases for analysis.
The methodology focuses on three main approaches:
1. Vanilla: A baseline approach where R simply explains why the text was detected as a hallucination without addressing the inconsistencies.
2. Fallback: introduces an “UNKNOWN” flag to indicate when R cannot provide an adequate explanation, pointing out possible inconsistencies.
3. Categorized: Refines the flagging mechanism by incorporating granular hallucination categories, including a specific category (hallu12) to flag inconsistencies where the text is not a hallucination.
These approaches are compared to assess their effectiveness in handling inconsistencies between SLM decisions and LLM explanations to improve the overall reliability and interpretability of the hallucination detection framework.
Experimental results demonstrate the effectiveness of the proposed hallucination detection framework, in particular the categorized approach. By identifying inconsistencies between SLM decisions and LLM explanations, the categorized approach achieved near-perfect performance on all datasets, with precision, recall, and F1 scores consistently above 0.998 on many datasets.
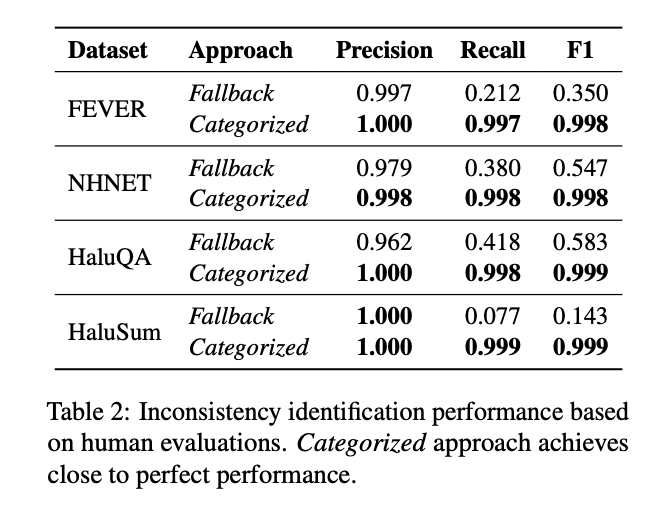
Compared to the backup method, which showed high precision but poor recall, the categorized method excelled in both metrics. This superior performance translated into more effective inconsistency filtering. While the traditional method showed high inconsistency rates and the backup method showed limited improvement, the categorized method dramatically reduced inconsistencies to as low as 0.1–1% across all datasets after filtering.
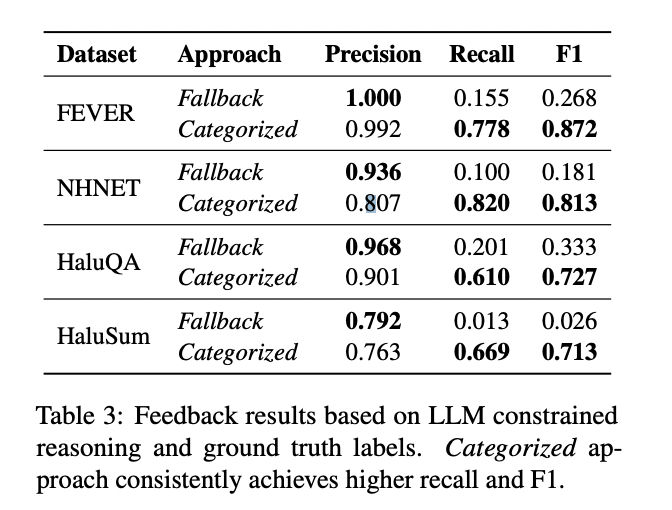
The categorized method also demonstrated great potential as a feedback mechanism to improve the SLM in the initial phase. It consistently outperformed the backup method in identifying false positives, achieving a macro-average F1 score of 0.781. This indicates its ability to accurately evaluate SLM decisions relative to the ground truth, making it a promising tool for refining the detection process.
These results highlight the ability of the categorized approach to improve the consistency between detection and explanation in the hallucination detection framework, while providing valuable feedback for system improvement.
This study presents a practical framework for efficient and interpretable hallucination detection by integrating an SLM for detection with an LLM for restricted reasoning. The researchers' proposed categorized prompting and filtering strategy effectively aligns LLM explanations with SLM decisions, demonstrating empirical success on four hallucination datasets and factual consistency. Furthermore, this approach has potential as a feedback mechanism for refining SLMs, paving the way for more robust and adaptive systems. The findings offer broader implications for improving classification systems and enhancing SLMs through LLM-driven restricted interpretation.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Below is a highly recommended webinar from our sponsor: ai/webinar-nvidia-nims-and-haystack?utm_campaign=2409-campaign-nvidia-nims-and-haystack-&utm_source=marktechpost&utm_medium=banner-ad-desktop” target=”_blank” rel=”noreferrer noopener”>'Developing High-Performance ai Applications with NVIDIA NIM and Haystack'
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}